6 Gráficos de comparación
Los gráficos de comparación son una forma de visualizar diferencias entre grupos o categorías, o también para comparar cambios en el tiempo. Siguiendo la Figura 1, los gráficos de comparación que veremos en este libro son:
Gráfico de barras (bar plot): se utiliza para comparar la frecuencia o valor de una variable categórica.
Gráfico de líneas (line plot): se utiliza para comparar cambios en una variable numérica a lo largo del tiempo.
En este capítulo vamos a trabajar con tres datasets:
iris: dataset donde se han medido la longitud y anchura de pétalos y sépalos de 150 flores, además de la especie a la que pertenecen (ver Tipos de visualización).gapminder: dataset con la evolución temporal del desarrollo económico, población y esperanza de vida de los países del mundo (ver Tipos de visualización).inventario: dataset con datos de inventario de 27 parcelas en los que se ha medido el DBH, altura y especie (ver Sección 2.2).
Para comenzar, vamos a cargar los paquetes necesarios y a leer los datos que utilizaremos en este capítulo.
6.1 Objetivos
Al final de este capítulo serás capaz de:
Crear gráficos de barras para comparar la frecuencia de una variable categórica.
Crear gráficos de líneas para comparar cambios en una variable numérica a lo largo del tiempo.
6.2 Gráfico de barras
El gráfico de barras es una de las formas más comunes de visualizar la frecuencia de una variable categórica. En este caso, vamos a utilizar el dataset de iris para comparar la frecuencia de las especies de flores. Para ello, tenemos dos funciones que nos permiten crear gráficos de barras:
geom_bar(): utilizastat = "count"para contar la frecuencia de cada categoría. Solamente necesita definir una estética (xoy)geom_col(): utilizastat = "identity"para representar los valores de la variable. Necesita definir dos estéticas (xey)
Vamos a generar el mismo gráfico utilizando ambas funciones para ver la diferencia. El gráfico que generaremos será la frecuencia de las especies de flores en el dataset de iris.
Como vemos, solamente indicamos la estética x. Como existen 50 flores de cada especie, simplemente nos da ese número para cada especie.
iris |>
ggplot(aes(x = Species)) +
geom_bar() +
labs(
title = "Frecuencia de especies de flores",
x = "Especies",
y = "Frecuencia"
)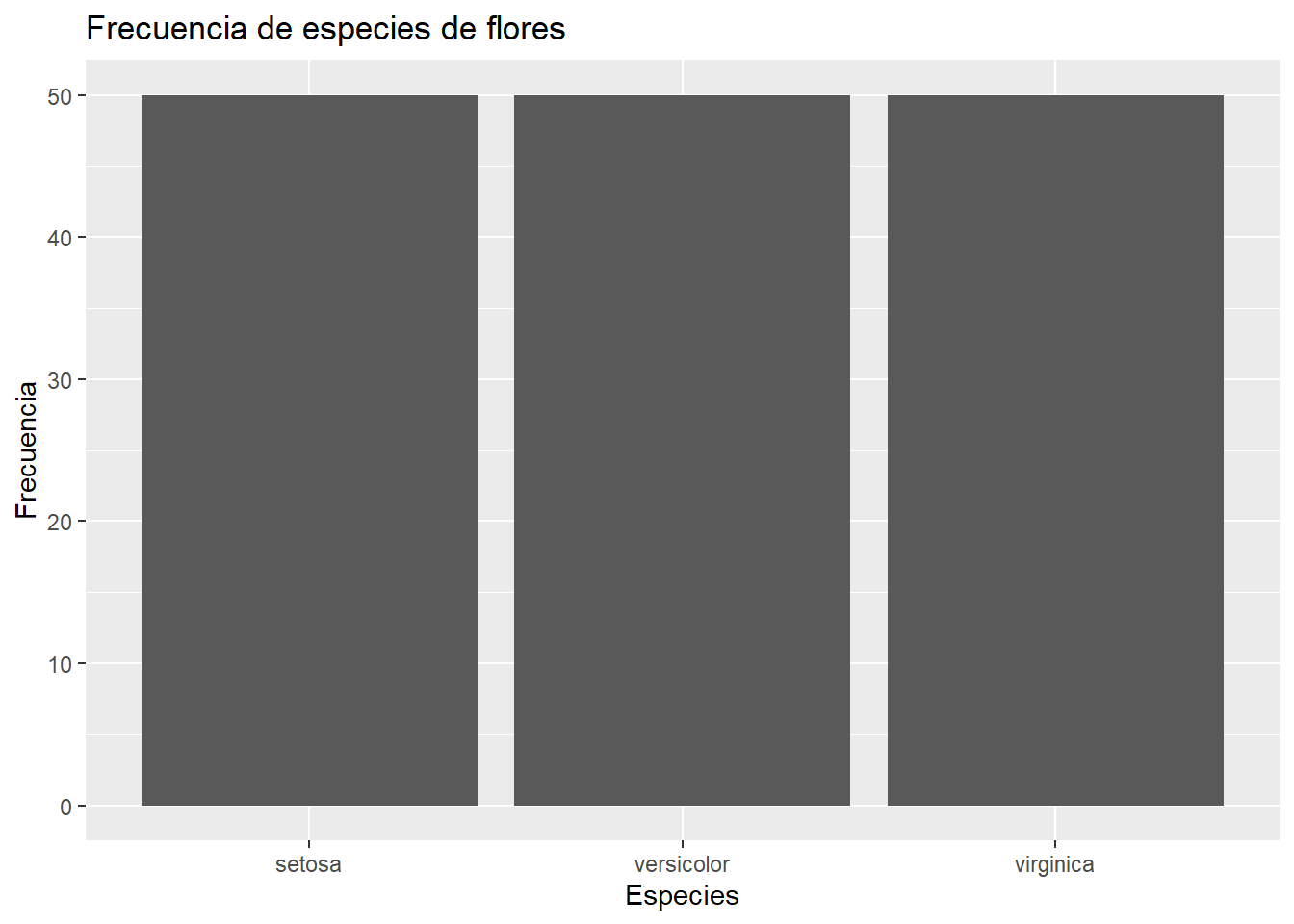
geom_bar() para la frecuencia de las especies de Iris
En este caso, necesitamos calcular primero los valores que queremos mostrar:
## Calcular frecuencias
iris_count <- count(iris, Species)
## Imprimir
iris_count Species n
1 setosa 50
2 versicolor 50
3 virginica 50Una vez tenemos los valores, vamos a generar el mismo gráfico. Fíjate que tenemos que añadir la estética y para decirle donde tiene que buscar los valores.
iris_count |>
ggplot(aes(x = Species, y = n)) +
geom_col() +
labs(
title = "Frecuencia de especies de flores",
x = "Especies",
y = "Frecuencia"
)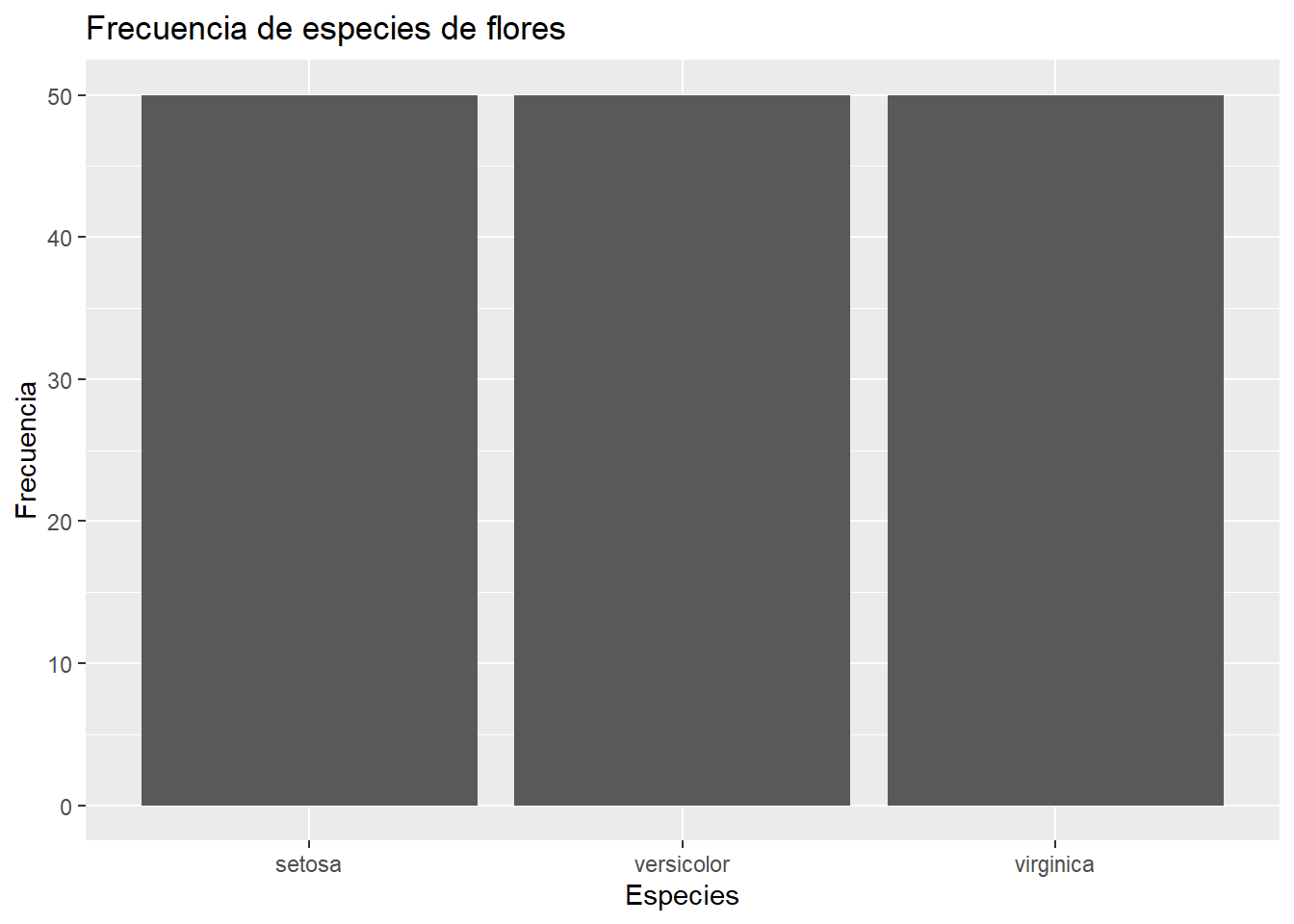
geom_col() para la frecuencia de las especies de Iris
Pues esta es la forma más básica de generar un gráfico de barras. Vamos a ver algo más interesante.
6.2.1 Position
Recuerdas cuando utilizamos geom_jitter(), que dijimos que era lo mismo que geom_point(position = "jitter")? Pues resulta que position es un argumento muy importante en los gráficos de barras para definir cómo se van a posicionar las barras. Esto cobra importancia cuando mapeamos una variable a la estética fill. Vamos a utilizar los datos de gapminder para los años mayores a 1990 y comparar el PIB per cápita de algunos países europeos.
## Filtrar datos
gapminder_tbl <- gapminder |>
filter(year > 1990) |>
filter(country %in% c("Spain", "Germany", "France", "Italy", "Portugal")) |>
mutate(
year = as.factor(year)
)
## Imprimir
gapminder_tbl# A tibble: 20 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <fct> <dbl> <int> <dbl>
1 France Europe 1992 77.5 57374179 24704.
2 France Europe 1997 78.6 58623428 25890.
3 France Europe 2002 79.6 59925035 28926.
4 France Europe 2007 80.7 61083916 30470.
5 Germany Europe 1992 76.1 80597764 26505.
6 Germany Europe 1997 77.3 82011073 27789.
7 Germany Europe 2002 78.7 82350671 30036.
8 Germany Europe 2007 79.4 82400996 32170.
9 Italy Europe 1992 77.4 56840847 22014.
10 Italy Europe 1997 78.8 57479469 24675.
11 Italy Europe 2002 80.2 57926999 27968.
12 Italy Europe 2007 80.5 58147733 28570.
13 Portugal Europe 1992 74.9 9927680 16207.
14 Portugal Europe 1997 76.0 10156415 17641.
15 Portugal Europe 2002 77.3 10433867 19971.
16 Portugal Europe 2007 78.1 10642836 20510.
17 Spain Europe 1992 77.6 39549438 18603.
18 Spain Europe 1997 78.8 39855442 20445.
19 Spain Europe 2002 79.8 40152517 24835.
20 Spain Europe 2007 80.9 40448191 28821.gapminder_tbl |>
ggplot(aes(x = year, y = gdpPercap, fill = country)) +
geom_col() +
labs(
x = NULL,
y = "PIB per cápita",
fill = NULL
) +
scale_fill_viridis_d() +
theme_bw()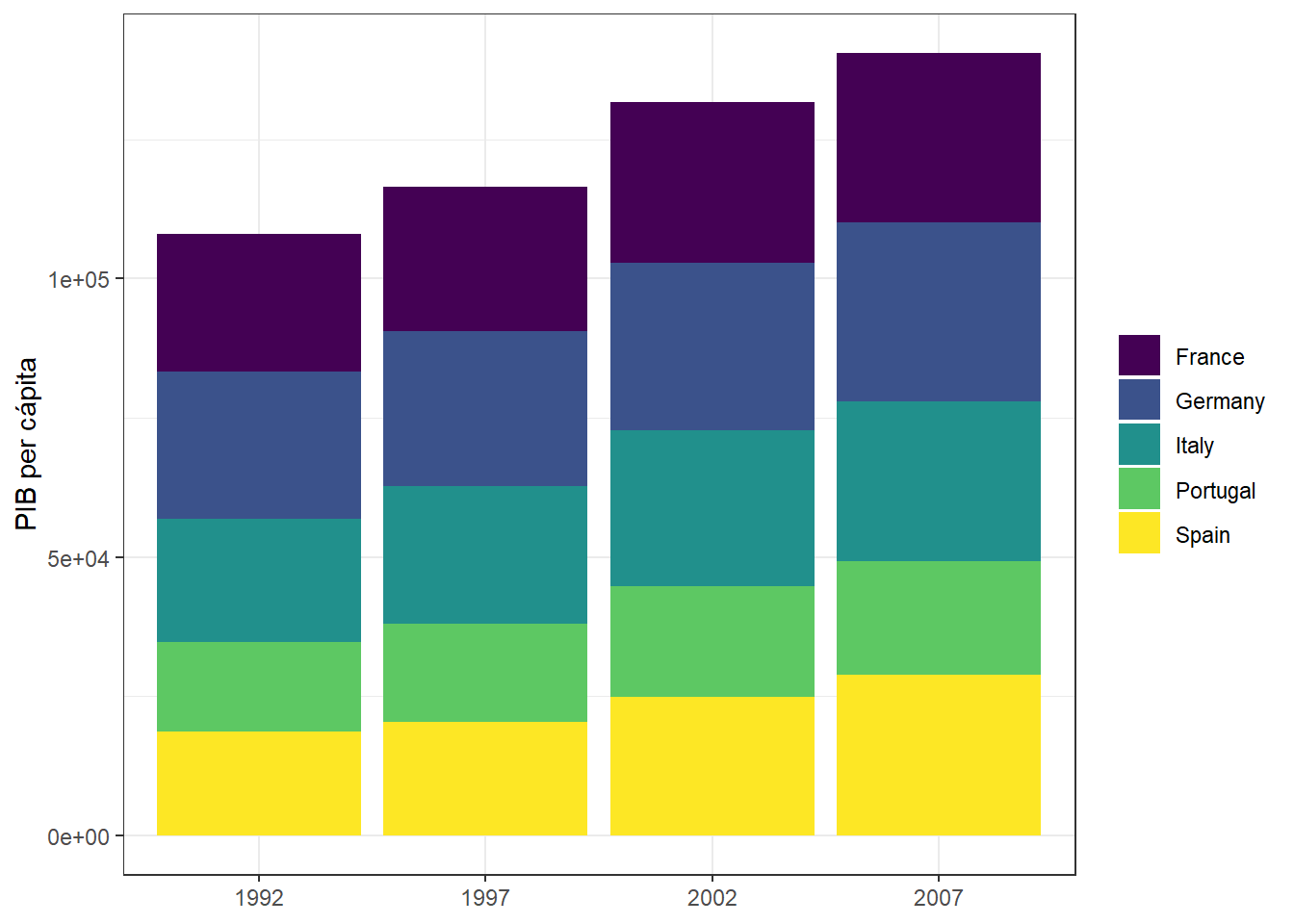
Como ves, por defecto las barras se ponen unas encima de otras. Este comportamiento viene definido por el argumento position, cuyas opciones son:
position = position_stack(): valor por defecto. Las barras se acumulan unas encima de otras.position = position_dodge(): las barras se separan unas de otras.position = position_dodge2(): las barras se separan unas de otras con un espacio entre ellas.position = position_fill(): muestra el valor relativo de cada clase. Cada barra suma un total de 1 = 100%.position = position_nudge(): todas las barras empiezan en 0 y se localizan unas detrás de otras.
En la siguiente aplicación puedes experimentar para ver el comportamiento con los diferentes valores de position.
#| standalone: true
#| viewerHeight: 600
## Load packages
library(bslib)
library(dplyr)
library(gapminder)
library(ggplot2)
library(glue)
library(shiny)
## UI
ui <- page_sidebar(
sidebar = sidebar(
open = "open",
width = 200,
selectInput(
inputId = "position_input",
label = "Position",
choices = c("dodge", "dodge2", "fill", "nudge", "stack"),
selected = "stack"
)
),
verbatimTextOutput("code") |> card(),
plotOutput("plot", width = 500) |> card()
)
## Server
server <- function(input, output, session) {
output$code <- renderPrint({
glue(
'
gapminder_tbl |>
ggplot(aes(x = year, y = gdpPercap, fill = country)) +
geom_col(
position = position_{input$position_input}()
) +
labs(x = NULL,y = "PIB per cápita",fill = NULL) +
scale_fill_viridis_d() +
theme_bw(base_size = 8)
'
)
})
## Plot
output$plot <- renderPlot({
gapminder |>
filter(year > 1990) |>
filter(country %in% c("Spain", "Germany", "France", "Italy", "Portugal")) |>
mutate(year = as.factor(year)) |>
ggplot(aes(x = year, y = gdpPercap, fill = country)) +
geom_col(
position = input$position_input
) +
labs(
x = NULL,
y = "PIB per cápita",
fill = NULL
) +
scale_fill_viridis_d() +
theme_bw(base_size = 8)
}, res = 96
)
}
## Run app
shinyApp(ui = ui, server = server)Podemos sacar una serie de conclusiones:
-
nudgees un método peligroso por dos motivos:Puede ser confundido con
stackUna barra con valores altos puede ocultar otras barras con valores más bajos, como ocurre en la imagen anterior.
stackes un método poco efectivo para comunicar. En el ejemplo anterior, España es sencilla de comparar a lo largo de los años. Pero y el resto? Al no estar en la misma escala, hace más complicado que los usuarios de tu gráfica puedan ver los cambios por ejemplo en Italia o Alemania.De los casos vistos,
dodge2es el mejor. Aún así, es mejorable.fill: es una buena opción cuando tiene sentido comparar los grupos en términos relativos (en este caso, no tiene sentido decir que una país tiene el 20% del PIB. El 20% de qué?).
6.2.2 Buenas prácticas
Vamos a volver al ejemplo de las especies de flores en el dataset de iris Figura 6.1, aunque sea un ejemplo muy sencillo, nos sirve para ver algunas buenas prácticas a la hora de generar gráficos de barras. En lugar de utilizar las 150, vamos a filtrar las 60 aleatorias para que no tengamos el mismo número de flores en cada clase:
## Filtrar datos
set.seed(111)
iris_sample <- iris |>
slice_sample(n = 60)Y ahora vamos a generar el gráfico de barras añadiendo mejoras:
Vamos a generar el primer gráfico:
iris_sample |>
ggplot(aes(x = Species)) +
geom_bar() +
labs(
title = "Frecuencia de especies de flores",
x = "Especies",
y = "Frecuencia"
)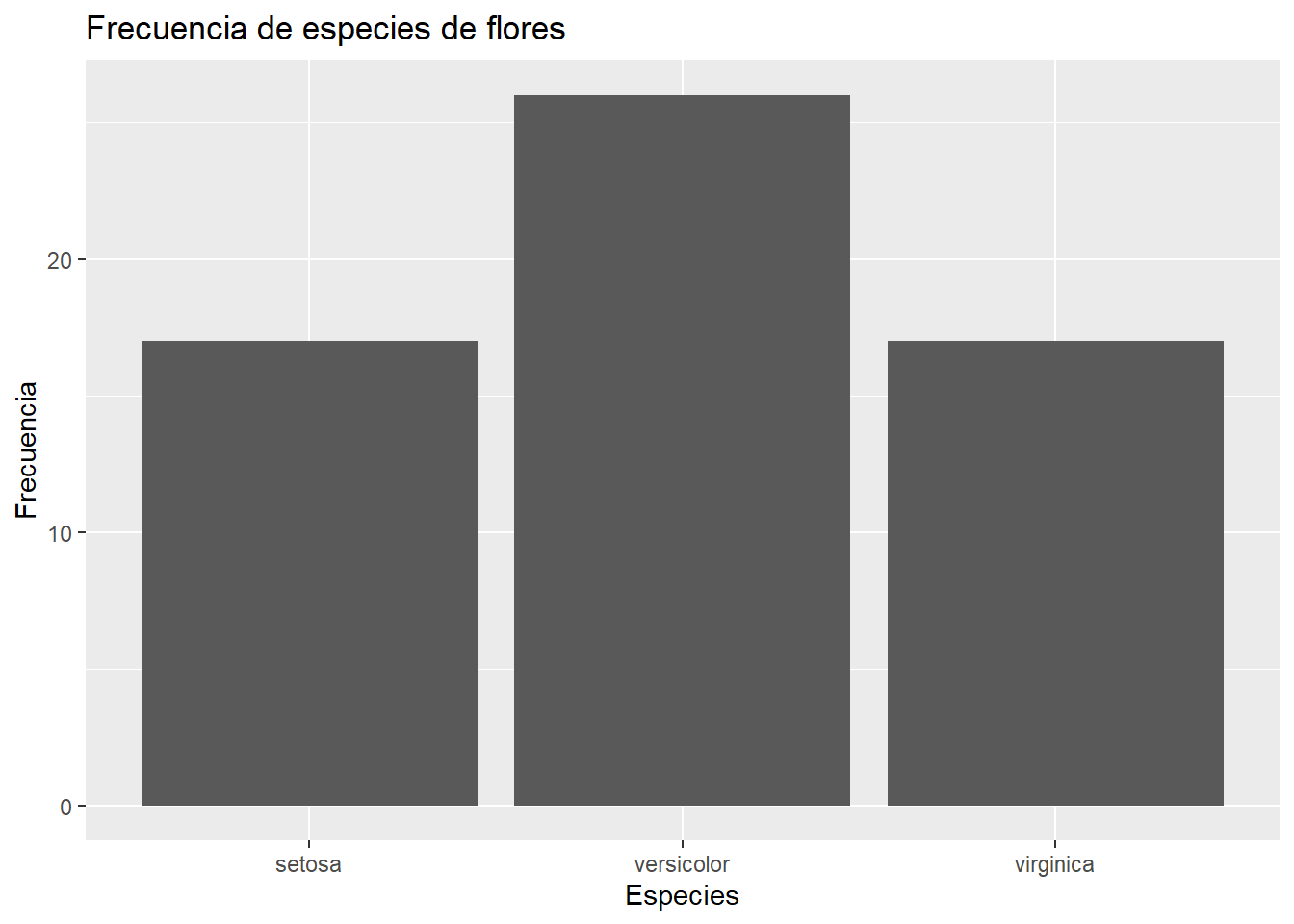
geom_bar() para la frecuencia de las especies de Iris
Vamos a empezar haciendo un par de cambios:
Cambiar el color de las barras y el tema.
Utilizar barras horizontales: esto suele ayudar mucho a la lectura de este tipo de gráfico, sobre todo cuando tenemos muchas categorías o tienen nombres largos. Para ello podemos o bien utilizar
y = Speciesocoord_flip()(siendo este segundo el más común para invertir los ejes).
iris_sample |>
ggplot(aes(x = Species)) +
geom_bar(fill = "#98B6B1") +
coord_flip() +
labs(
x = NULL,
y = "Frecuencia"
) +
theme_minimal()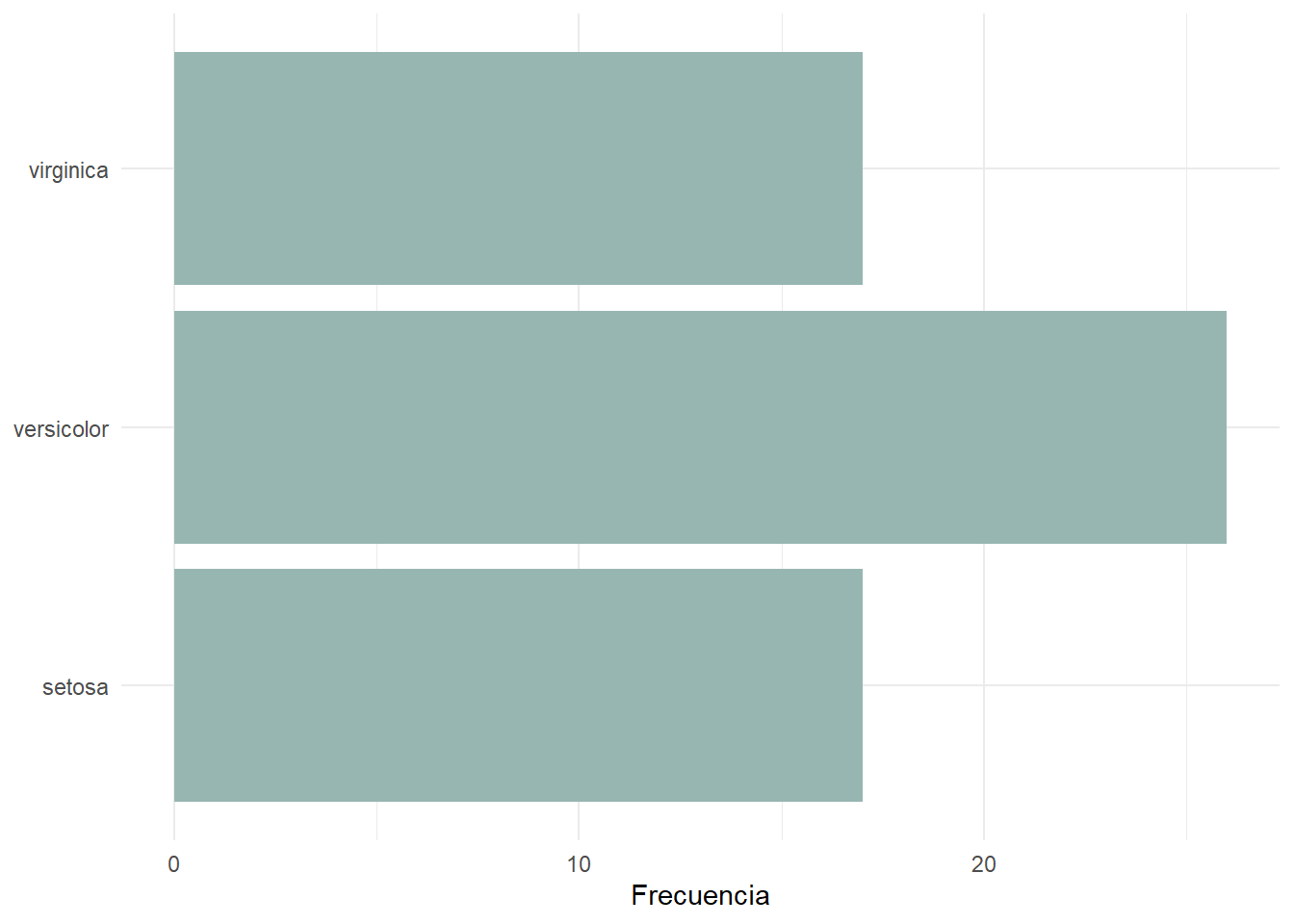
En siguiente lugar, cuando se utilizan gráficos de barras, debemos ordenar las barras siguiendo un orden lógico, que será prácticamente siempre según el tamaño de las barras. Para ello, vamos a utilizar la función fct_infreq() del paquete forcats para ordenar las barras según la frecuencia de las especies.
iris_sample |>
ggplot(
aes(x = fct_infreq(Species))
) +
geom_bar(fill = "#98B6B1") +
coord_flip() +
labs(
x = NULL,
y = "Frecuencia"
) +
theme_minimal()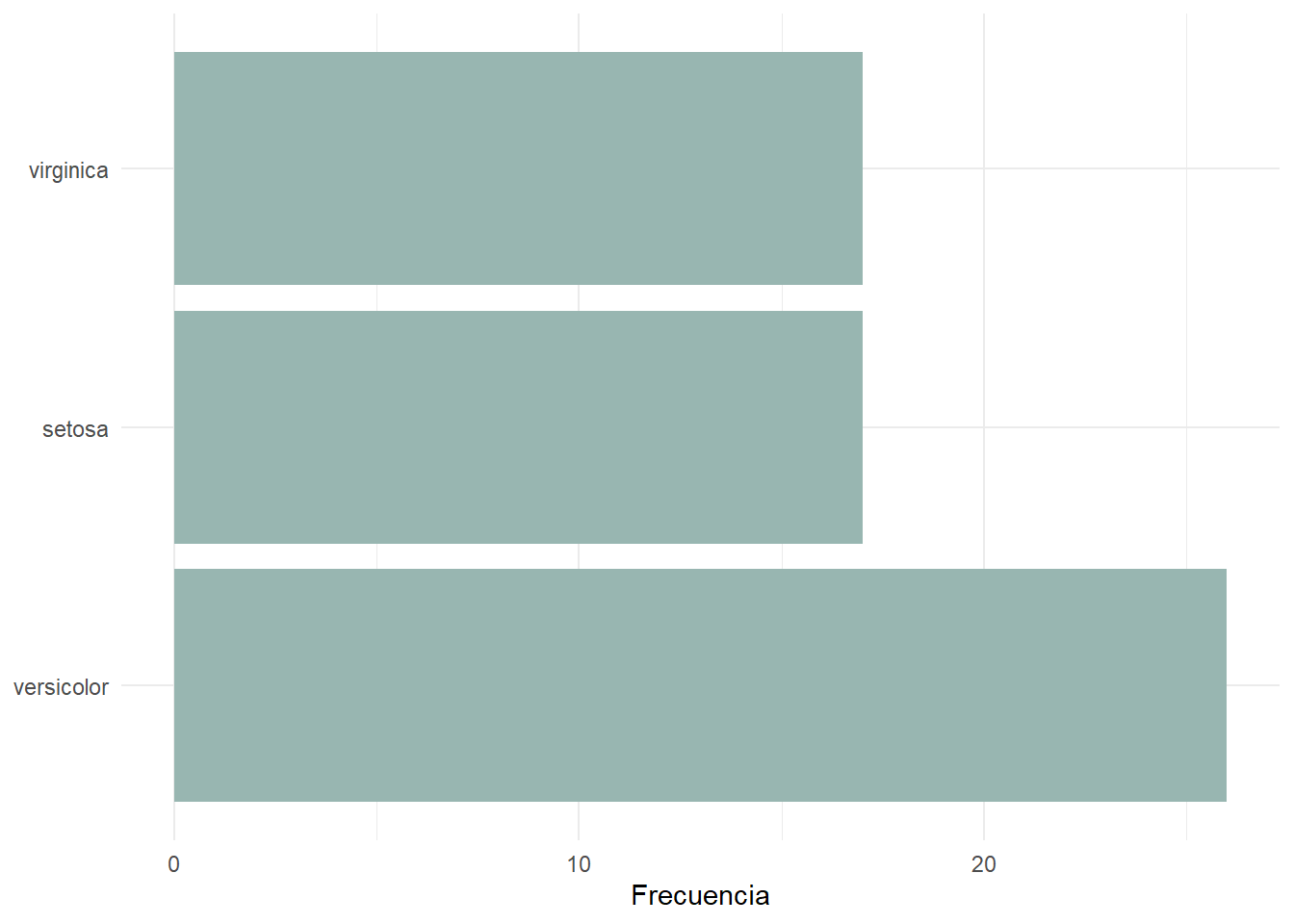
Aunque esto pueda ser lo que queramos, normalmente querremos ordenar de mayor a menor. Para ello, podemos añadir fct_rev() al final de la función, que invierte los niveles de la variable.
iris_sample |>
ggplot(
aes(
x = fct_infreq(Species) |> fct_rev()
)
) +
geom_bar(fill = "#98B6B1") +
coord_flip() +
labs(
x = NULL,
y = "Frecuencia"
) +
theme_minimal()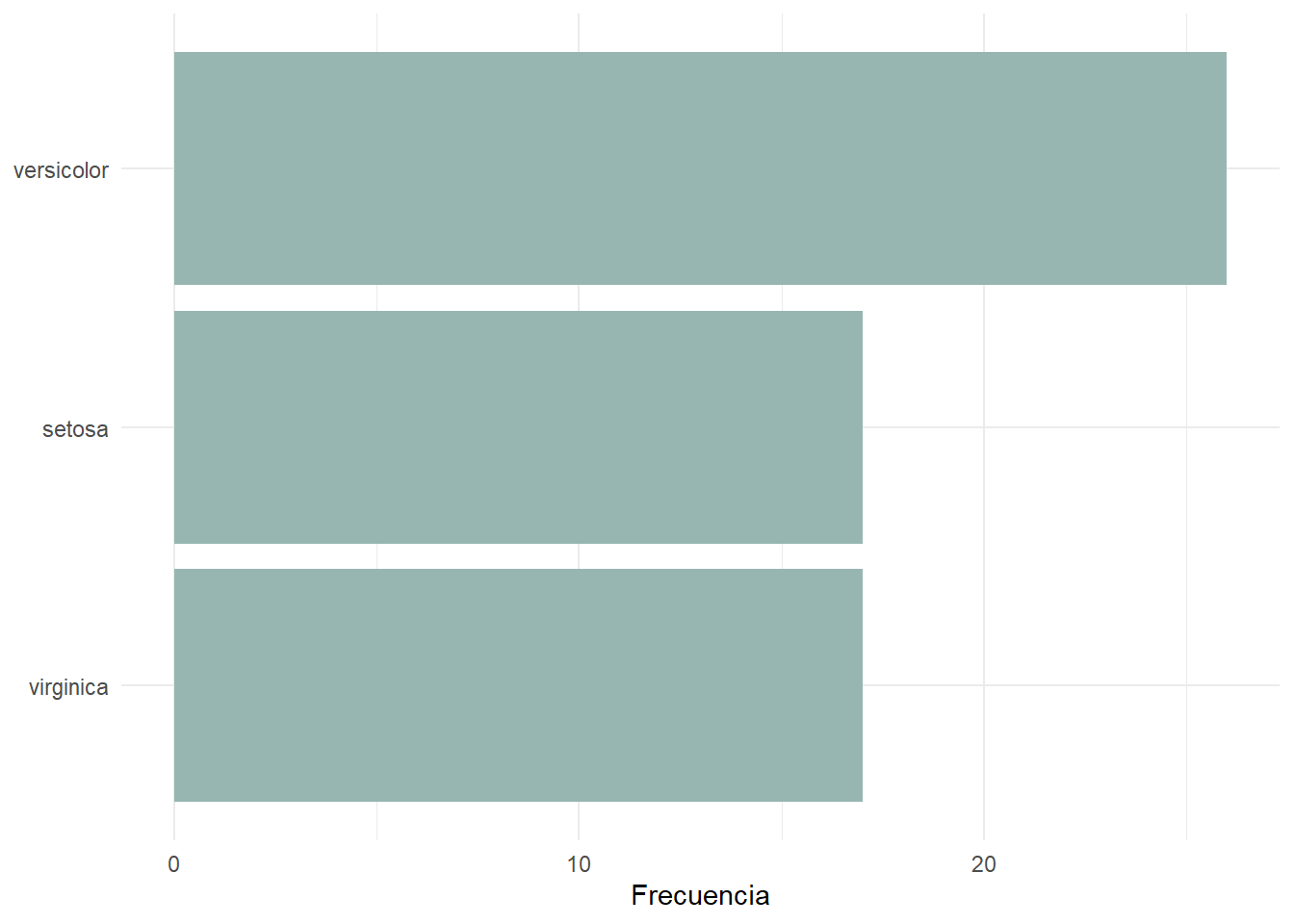
Para finalizar, vamos a cambiar el tamaño de las barras. De verdad es necesario que las barras sean tan gruesas? Normalmente, cuanto más finas sean las barras, más fácil será compararlas. Para ello, vamos a añadir width = 0.4 a geom_bar().
iris_sample |>
ggplot(
aes(
x = fct_infreq(Species) |> fct_rev()
)
) +
geom_bar(fill = "#98B6B1", width = 0.4) +
coord_flip() +
labs(
x = NULL,
y = "Frecuencia"
) +
theme_minimal()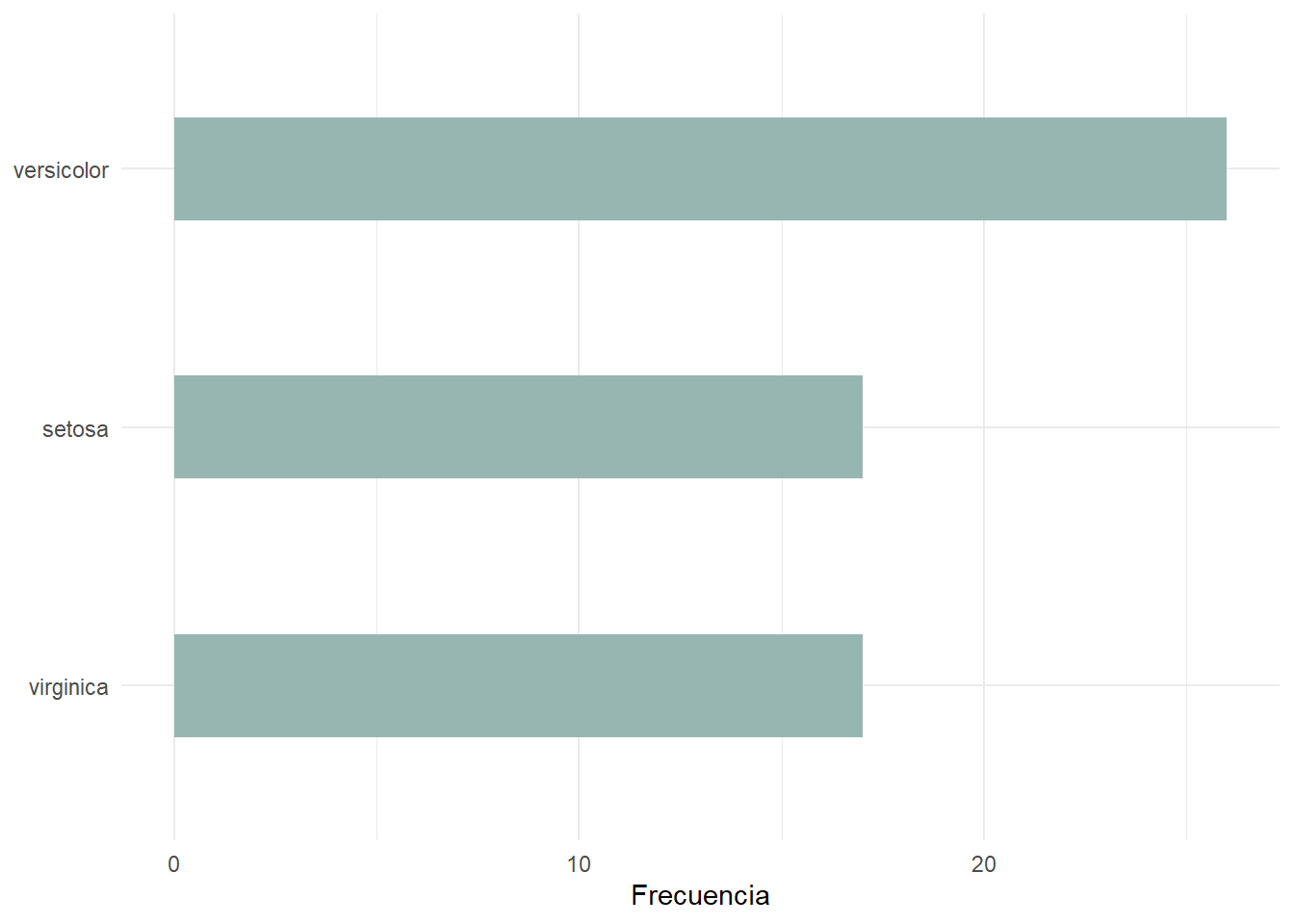
Este sería el resultado final. Todavía se pueden hacer más mejoras, como utilizar mejores etiquetas del eje Y, y otros ajustes de diseño. Pero eso será cuestión de otro capítulo.
6.2.3 Ejercicio 10
Vamos a practicar lo aprendido con un ejercicio. Utiliza los datos de inventario para generar un gráfico de barras que muestre la frecuencia de árboles por parcela siguiendo las buenas prácticas que acabamos de ver.
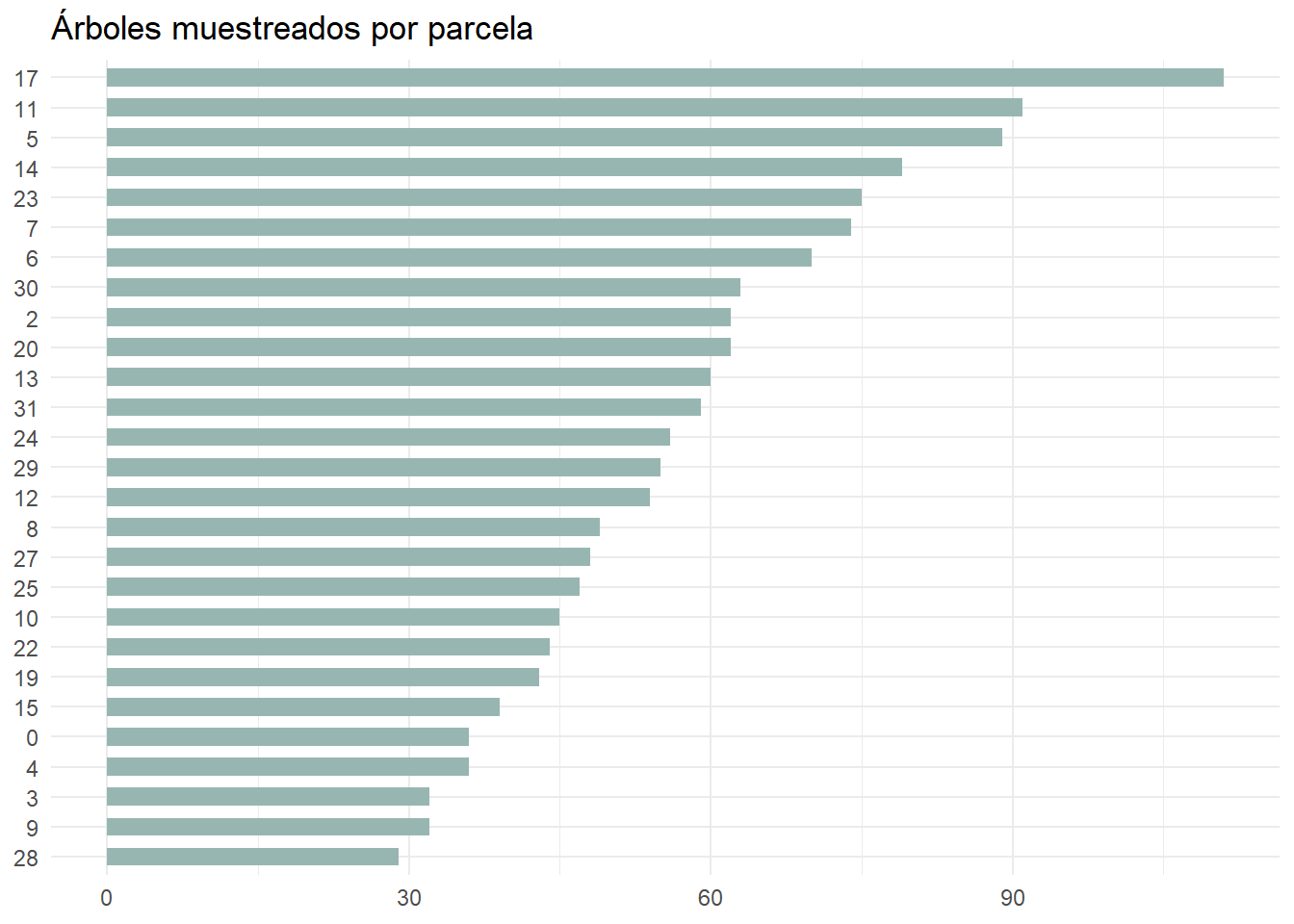
inventario_tbl |>
ggplot(
aes(
x = fct_infreq(id_plots) |> fct_rev()
)
) +
geom_bar(fill = "#98B6B1", width = 0.6) +
coord_flip() +
labs(
title = "Árboles muestreados por parcela",
x = NULL,
y = NULL
) +
theme_minimal()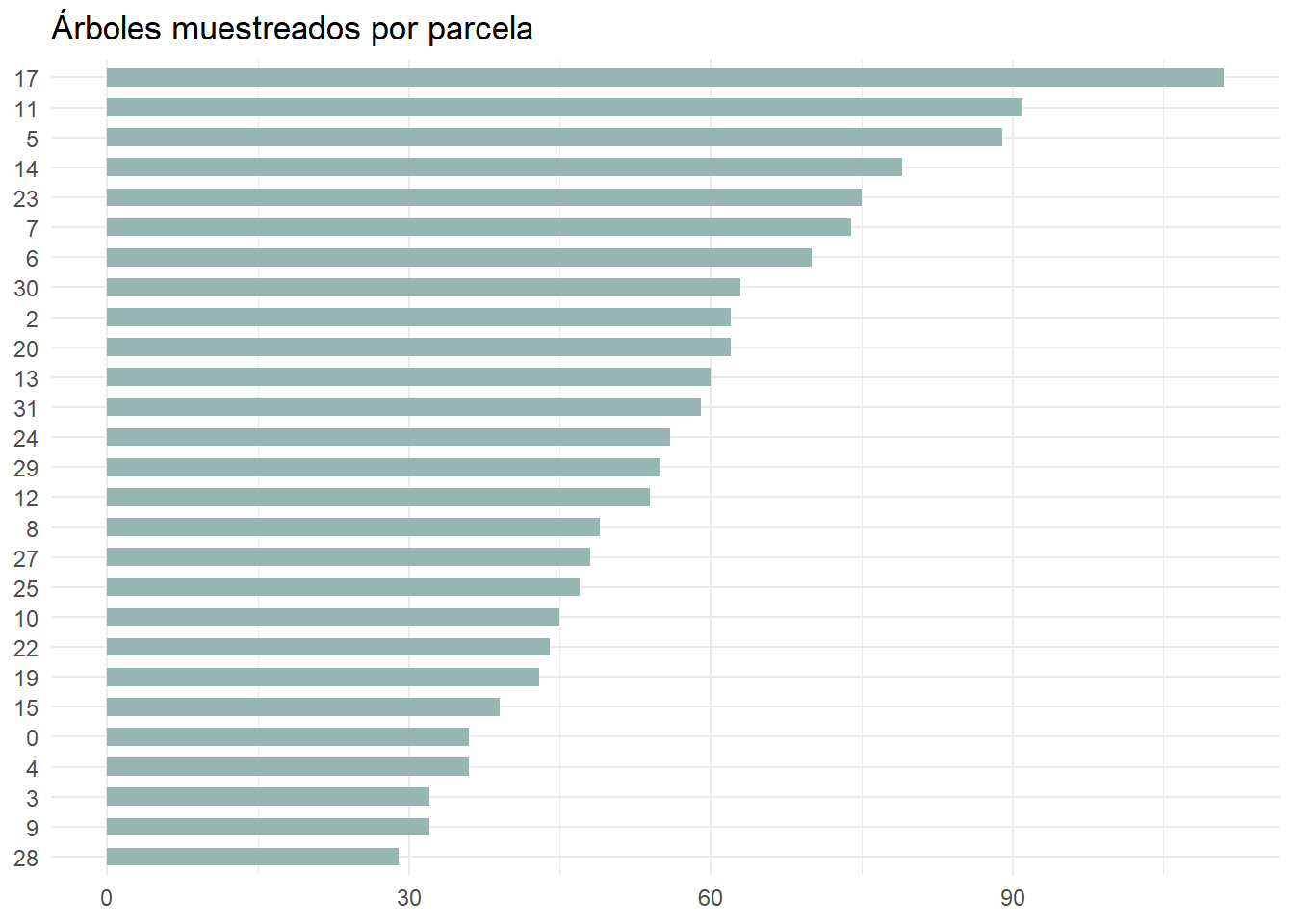
6.3 Gráfico de líneas
El gráfico de líneas es una de las formas más comunes de visualizar cambios en una variable numérica a lo largo del tiempo. En este caso, vamos a utilizar el dataset de gapminder para comparar la evolución de la esperanza de vida de algunos países europeos. Para ello, vamos a utilizar la función geom_line().
gapminder |>
filter(country %in% c("Spain", "Germany", "France", "Italy", "Portugal")) |>
ggplot(aes(x = year, y = lifeExp, color = country)) +
geom_line(
linewidth = 1
) +
labs(
x = NULL,
y = "Esperanza de vida",
color = NULL
) +
scale_color_viridis_d() +
theme_minimal()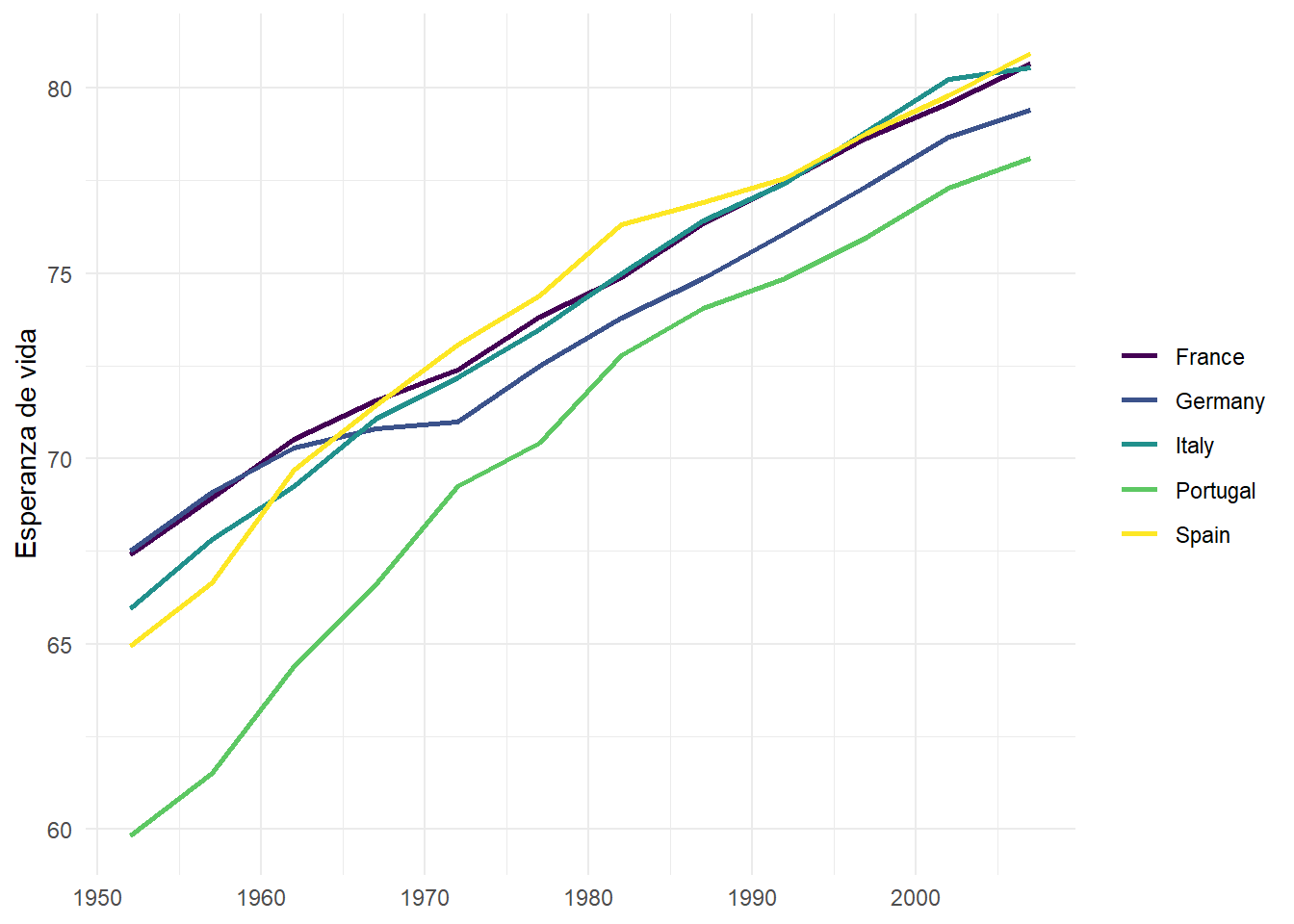
6.3.1 Spaguetti plot
El spaghetti plot es un tipo de gráfico de líneas en el que se representan muchas líneas en un mismo gráfico de forma que no nos permite ver ninguna tendencia en los datos. El siguiente gráfico es un ejemplo de spaghetti plot:
gapminder |>
ggplot(aes(x = year, y = lifeExp, color = continent, group = country)) +
geom_line() +
labs(
x = NULL,
y = "Esperanza de vida",
color = NULL
) +
theme_minimal()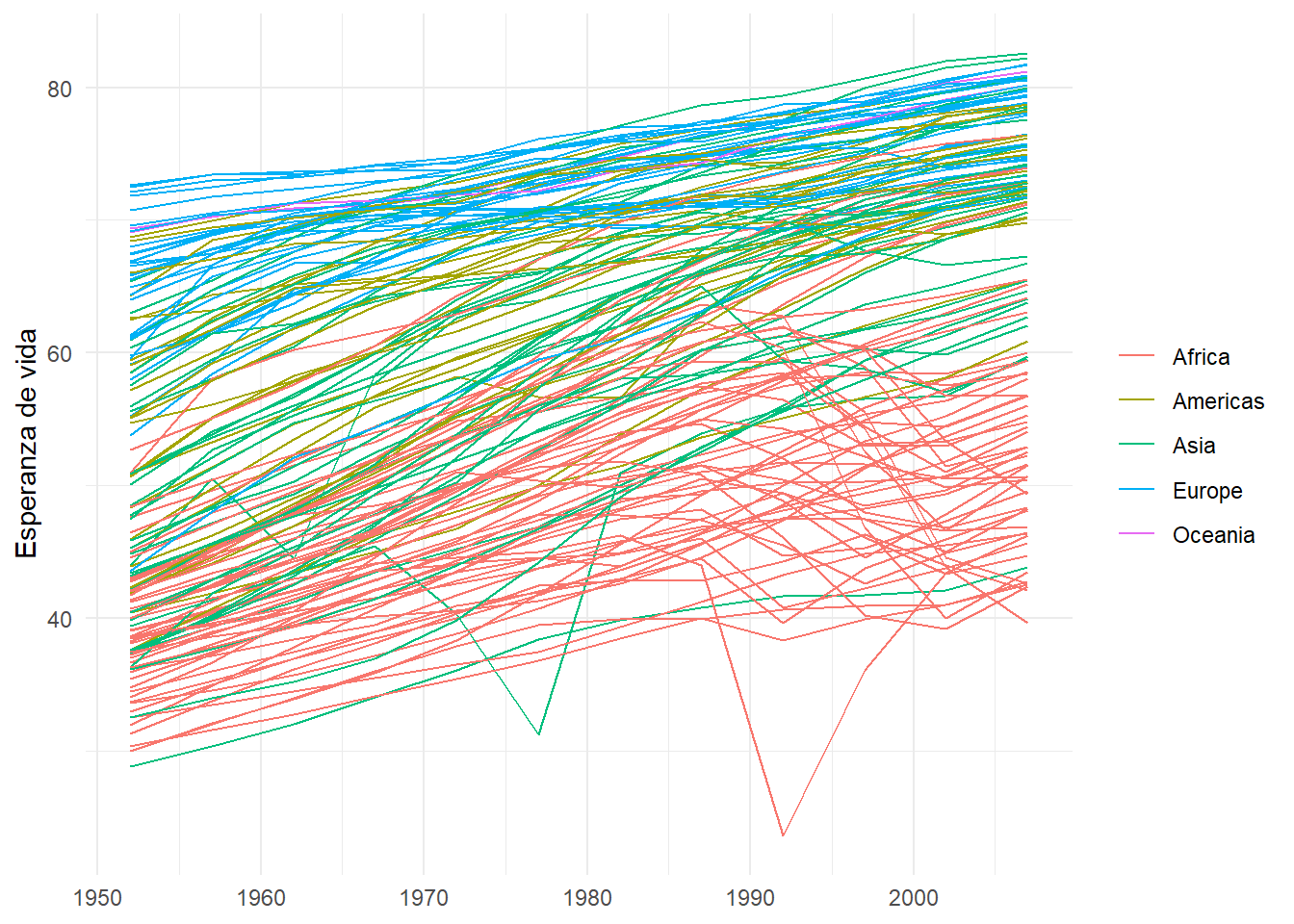
Fíjate que añadimos la estética group = country para que cada país tenga su propia línea (en Figura 6.11 no fue necesario porque ya estábamos mapeando la variable a la estética color). Este gráfico es algo que debes evitar. A partir de unas 6-7 líneas, deberías considerar presentar tus datos de otra forma.
Los gráficos de líneas son una geometría conjunta, lo que quiere decir que cada línea es un solo objeto geométrico. Los gráficos de puntos por lo contrario, son geometrías individuales, ya que cada observación tiene su propia representación. En las geometrías conjuntas dibujamos una geometría por cada grupo, lo que se traduce en una sola línea para cada país en este caso. Otro ejemplo de geometría conjunta es el boxplot:
Un boxplot es básicamente la distribución de una sola variable numérica:
gapminder |>
ggplot(aes(y = lifeExp)) +
geom_boxplot()
Pero si la agrupamos por continente, tendremos un boxplot por cada valor distinto de esa variable:
gapminder |>
ggplot(aes(y = lifeExp, group = continent)) +
geom_boxplot()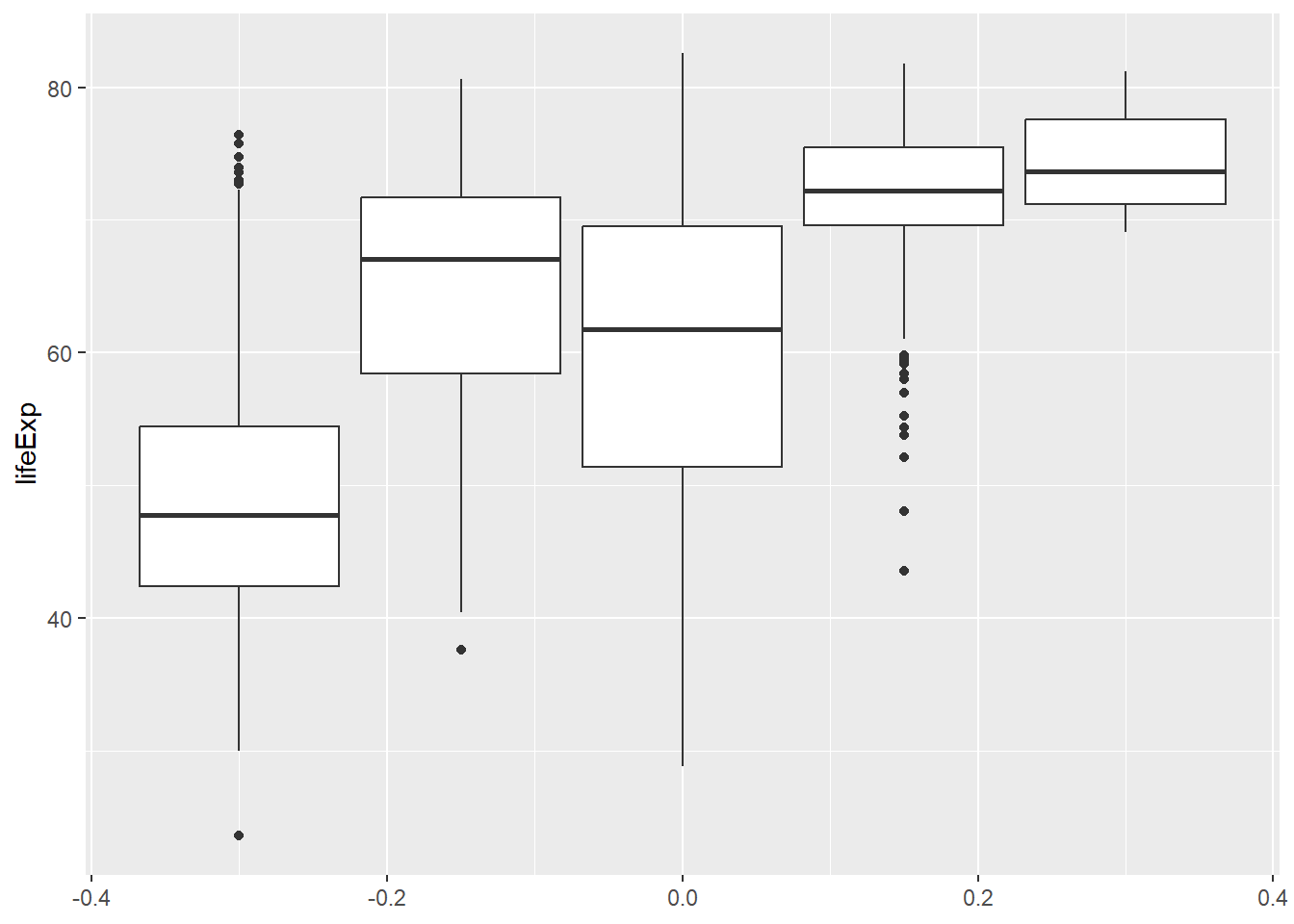
No obstante, al utilizar la estética x, se genera un grupo automáticamente por cada valor de la variable y además añade las etiquetas al eje:
gapminder |>
ggplot(aes(y = lifeExp, x = continent)) +
geom_boxplot()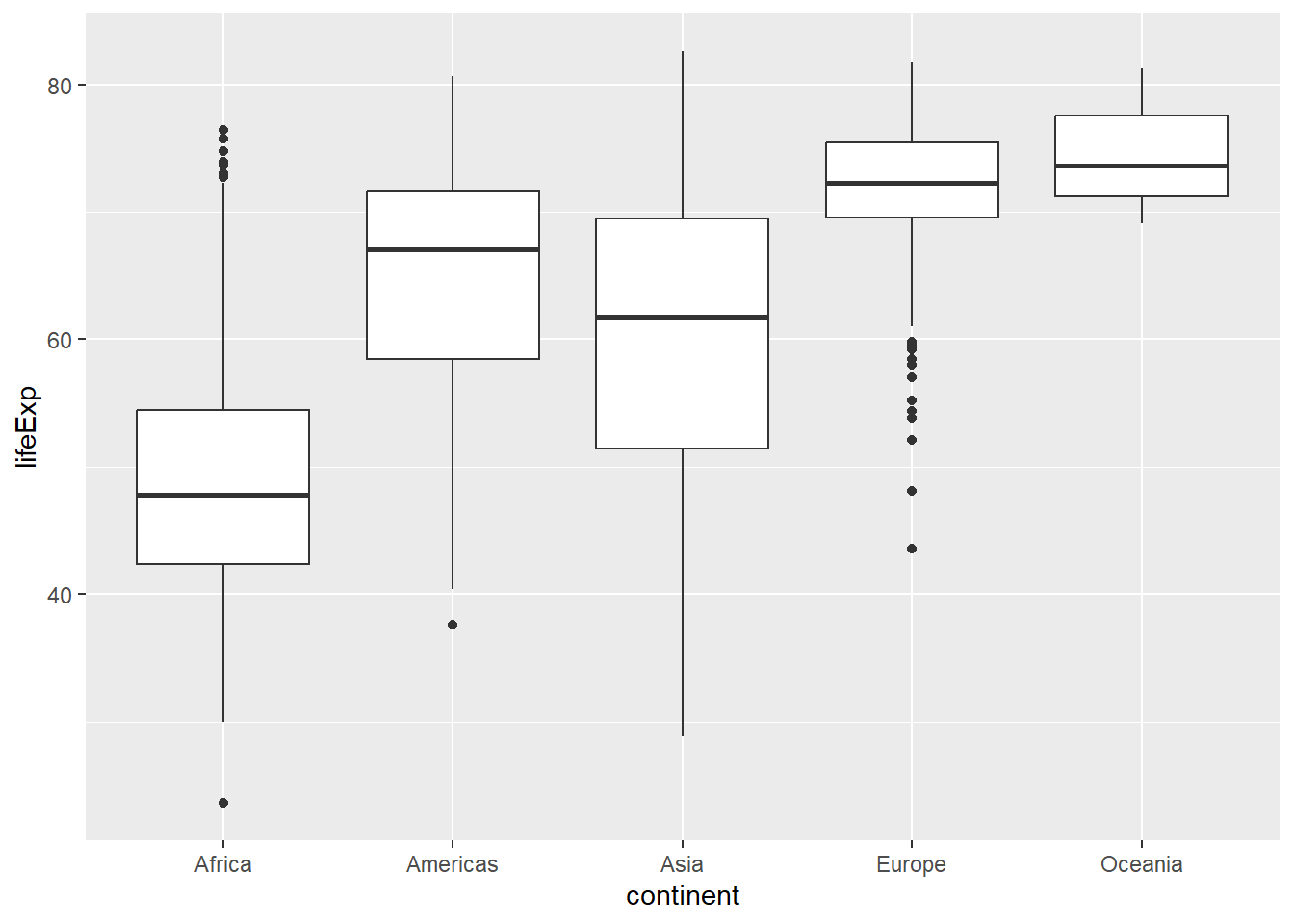
6.3.2 Solución spaghetti plot
La primera solución, es hacer que las líneas sean grises, de forma que no destaquen tanto y hacer visible únicamente la que nos interesa enseñar al público. Por ejemplo, vamos a destacar solamente aquellos países cuyo PIB ha decrecido desde 1952 hasta 2007.
Para ello, seleccionamos las columnas que necesitamos, luego filtramos los dos años que queremos comparar, expandimos la tabla para poder calcular la diferencia y finalmente extraemos los países cuya diferencia sea inferior a 0:
## Filtrar datos
countries_vec <- gapminder |>
select(country, year, lifeExp) |>
filter(
year %in% c(1952, 2007)
) |>
pivot_wider(
names_from = year,
names_prefix = "year_",
values_from = lifeExp
) |>
mutate(
diff = year_2007 - year_1952
) |>
filter(
diff < 0
) |>
pull(country) |>
as.character()
## Ver países
countries_vec[1] "Swaziland" "Zimbabwe" Una vez tenemos estos países, vamos a generar el gráfico destacando solamente estos dos:
gapminder |>
ggplot(
aes(x = year, y = lifeExp, color = continent, group = country)
) +
geom_line(color = "grey80") +
geom_line(
aes(x = year, y = lifeExp),
data = gapminder |> filter(country %in% countries_vec),
color = "#BC3908",
lwd = 1
) +
labs(
x = NULL,
y = "Esperanza de vida",
color = NULL,
title = "La mayoría de países aumentaron su esperanza de vida entre 1952 y 2007. \nSwaziland y Zimbabwe no"
) +
theme_minimal()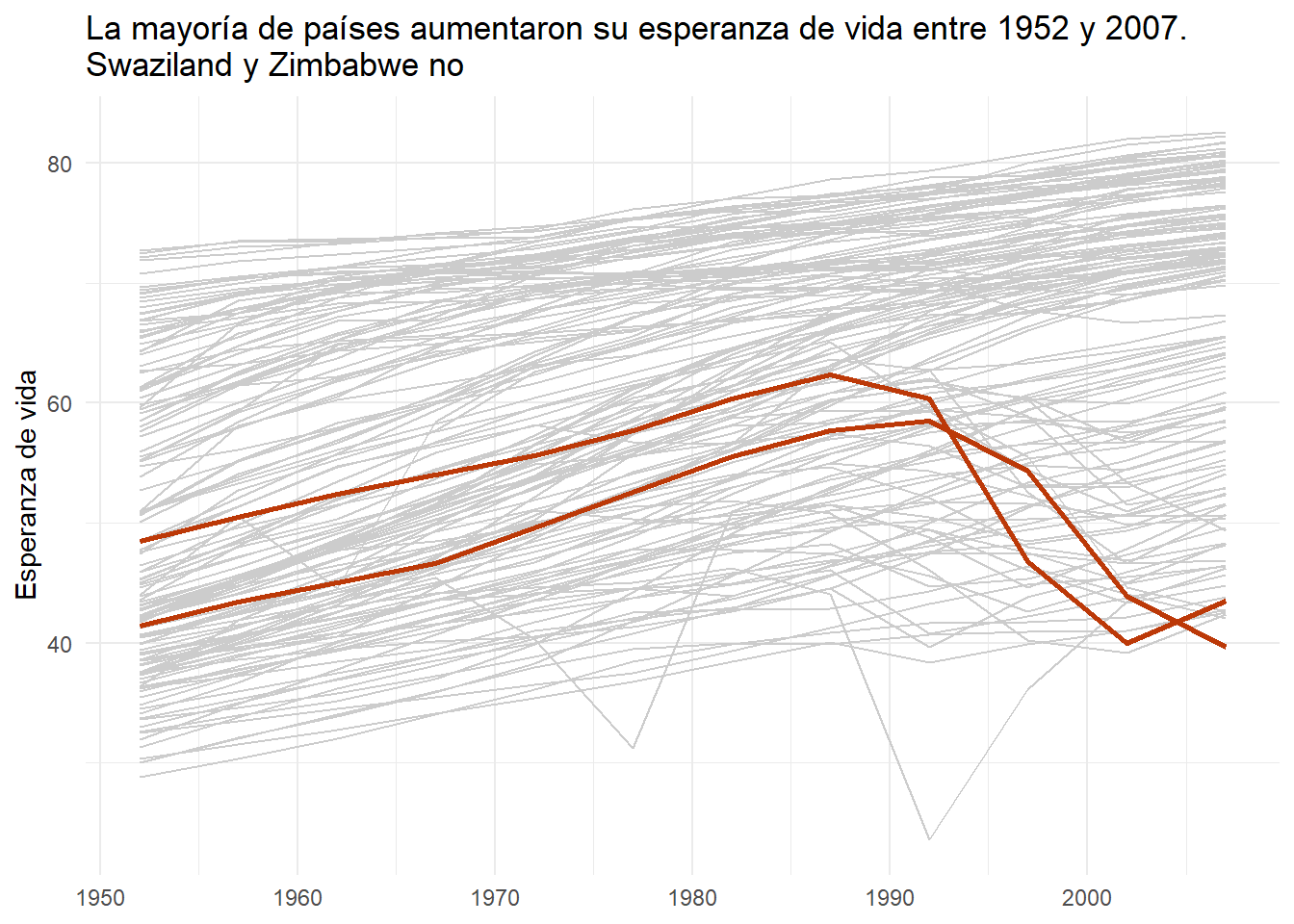
En este caso, fíjate que aunque tengamos un spaguetti plot, estamos resaltando que nuestro mensaje solamente se encuentra en dos líneas, y por lo tanto puede ser un gráfico útil.
Todavía podemos mejorar este gráfico diciendo qué línea representa a cada país. Para ello, podemos utilizar la función geom_textpath() del paquete geomtextpath. Lo único que tenemos que cambiar es el nombre de la geometría y añadir la estética label:
gapminder |>
ggplot(
aes(x = year, y = lifeExp, color = continent, group = country)
) +
geom_line(color = "grey80") +
geom_textpath(
aes(x = year, y = lifeExp, label = country),
data = gapminder |> filter(country %in% countries_vec),
color = "#BC3908",
lwd = 1
) +
labs(
x = NULL,
y = "Esperanza de vida",
color = NULL,
title = "La mayoría de países aumentaron su esperanza de vida entre 1952 y 2007. \nSwaziland y Zimbabwe no"
) +
theme_minimal()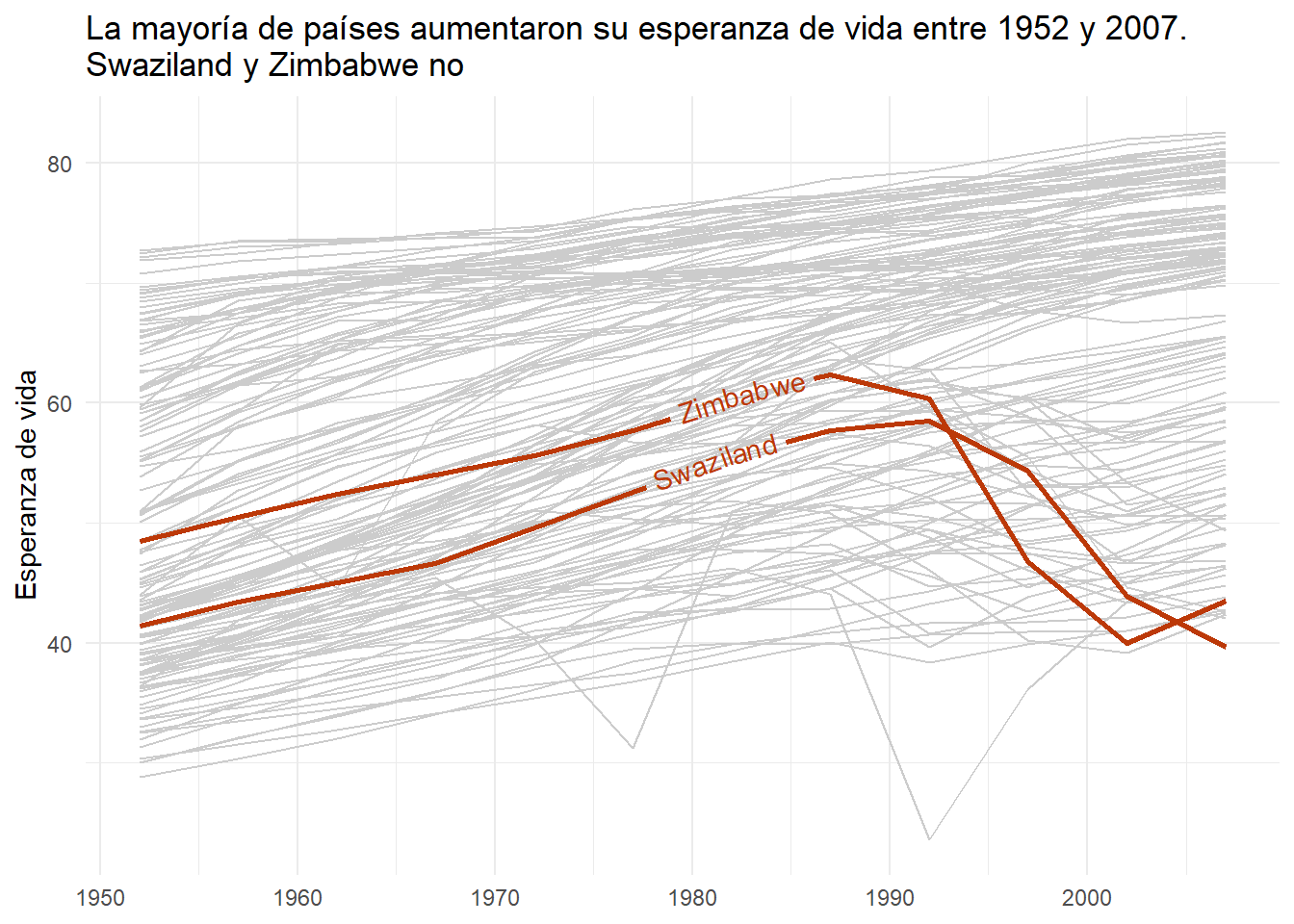
Y con esto ya tenemos una visualización mucho mejor que la inicial.
6.3.3 Ejercicio 11
Crear un gráfico de líneas donde se vea la evolución del PIB per cápita de los países del mundo (excepto los países de África), destacando solamente aquellos cuyo PIB per cápita se haya reducido entre 1952 y 2007.
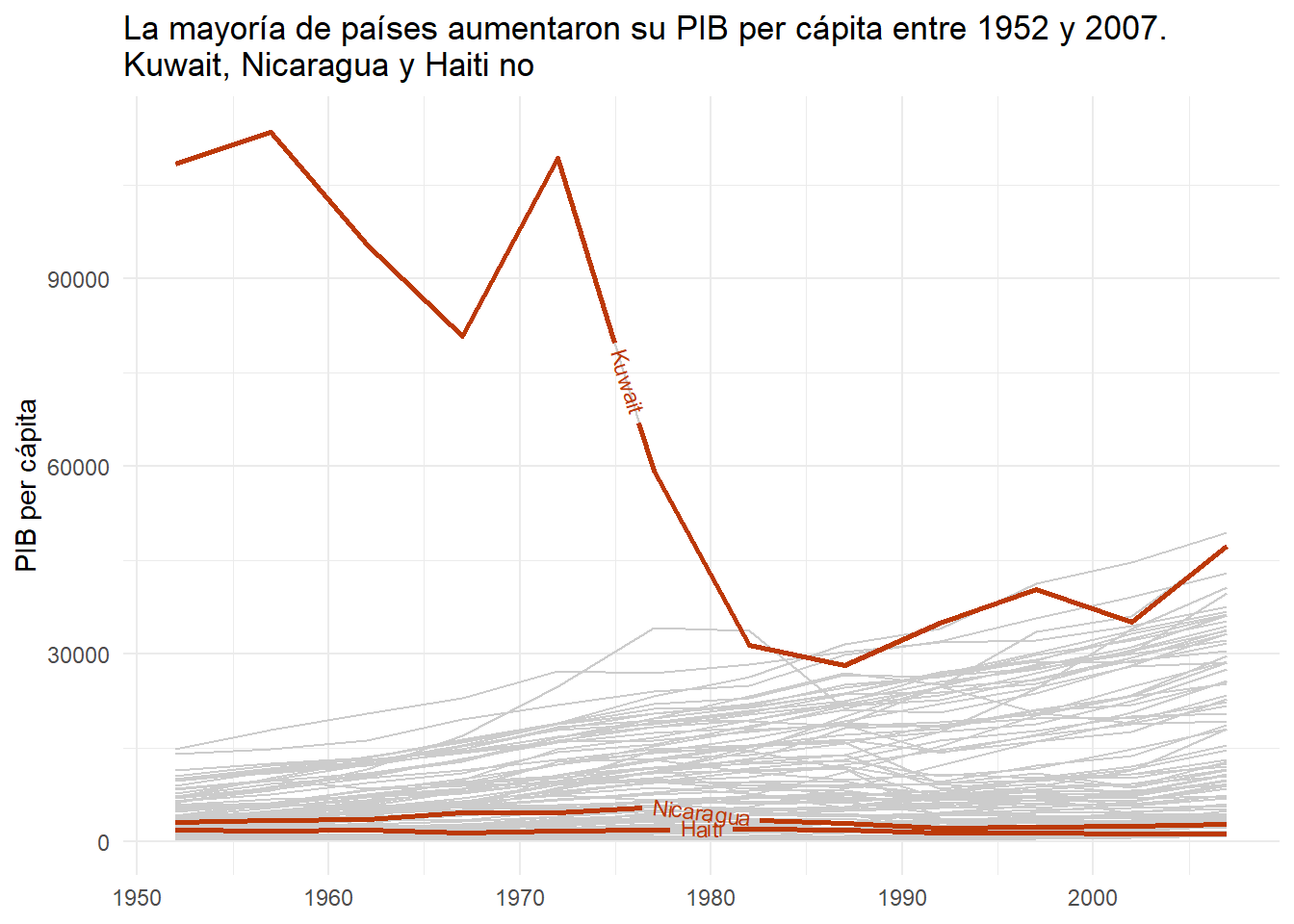
En el siguiente bloque de código se muestra como filtrar los países cuyo PIB per cápita ha disminuido entre 1952 y 2007. Utiliza estos datos para generar el gráfico de líneas.
Escribe aquí el código para generar el gráfico:
gapminder |>
filter(continent != "Africa") |>
ggplot(
aes(x = year, y = gdpPercap, color = country, group = country)
) +
geom_line(color = "grey80") +
geom_textpath(
aes(x = year, y = gdpPercap, label = country),
data = gapminder |> filter(country %in% countries_vec),
color = "#BC3908",
lwd = 1,
size = 3
) +
labs(
x = NULL,
y = "PIB per cápita",
color = NULL,
title = "La mayoría de países aumentaron su PIB per cápita entre 1952 y 2007. \nKuwait, Nicaragua y Haiti no"
) +
theme_minimal()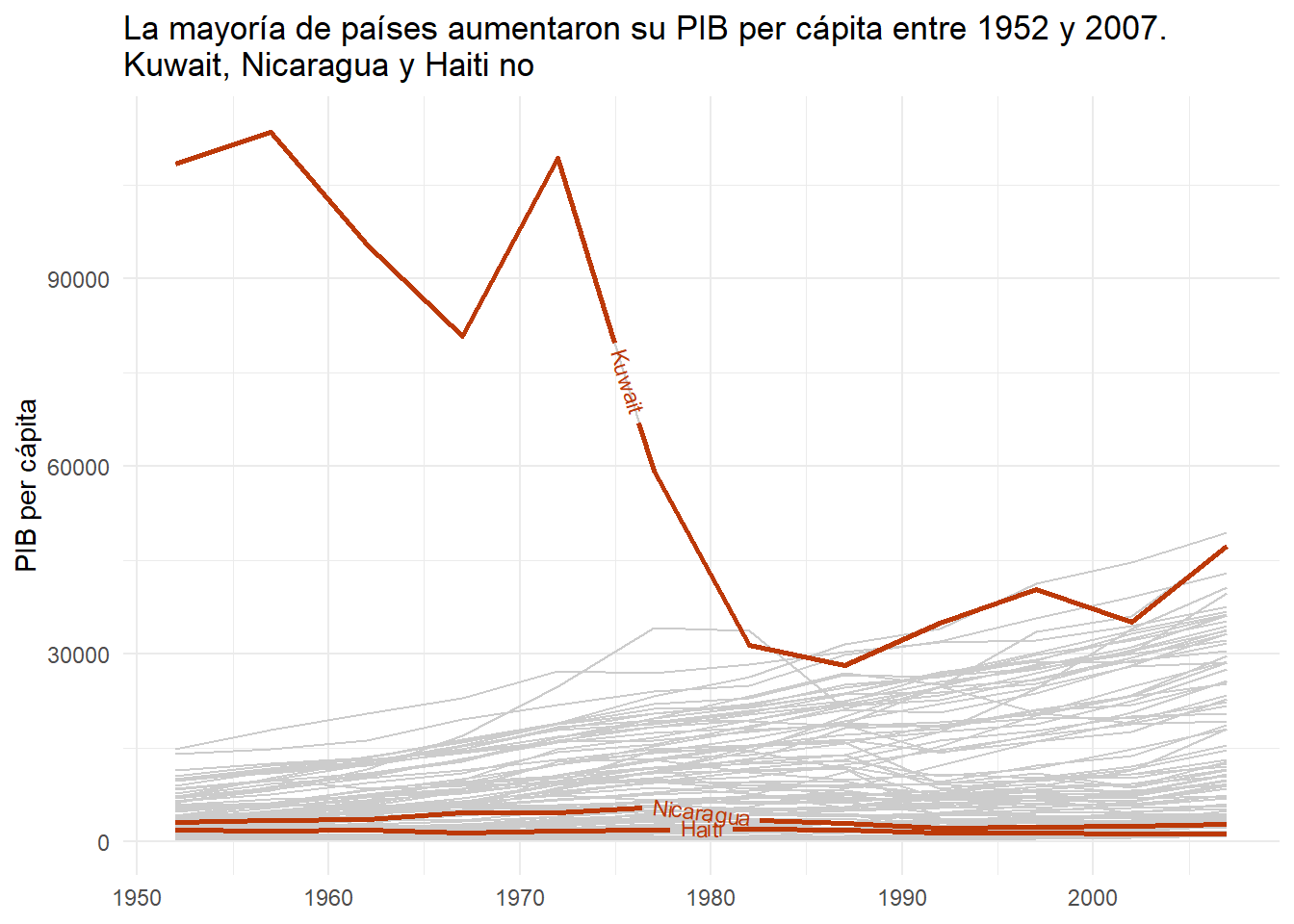
6.4 Resumen
En este capítulo hemos aprendido a generar gráficos de comparación utilizando geom_bar() y geom_col() para gráficos de barras y geom_line() para gráficos de líneas. Hemos visto cómo utilizar el argumento position para posicionar las barras y cómo evitar el spaghetti plot.