4 Gráficos de distribución
Los gráficos de distribución son una forma de visualizar la distribución de los datos. En este tipo de gráficos, se muestra la frecuencia de los valores de una variable o de un conjunto de variables. Los gráficos de distribución son útiles para identificar patrones en los datos, como la presencia de valores atípicos, la simetría de la distribución, la presencia de múltiples modas, entre otros. Generalmente, los gráficos de distribución se utilizan para visualizar una sola variable numérica aunque en la Figura 1 se muestra que también es posible visualizar dos variables numéricas mediante el uso de gráficos de dispersión (scatter plot).
En este capítulo, veremos los siguientes tipos de gráficos de distribución:
Histogramas (histogram)
Gráficos de densidad (density plot)
Gráficos de cajas (box plot)
Gráficos de violín (violin plot)
Los gráficos de dispersión los veremos dentro del capítulo de gráficos de relación.
En este capítulo vamos a trabajar con dos datasets:
iris: se utilizará para los ejemplos utilizados en las explicaciones (ver Tipos de visualización).inventario: serán los datos que utilizarán los alumnos para los ejercicios propuestos (ver Sección 2.2).
Para comenzar, vamos a cargar los paquetes necesarios y a leer los datos que utilizaremos en este capítulo.
4.1 Objetivos
Al final de este capítulo, serás capaz de:
4.2 Histogramas
Los histogramas son una forma de visualizar la distribución de una variable numérica. En un histograma, los valores de la variable se agrupan en intervalos y se muestra la frecuencia de los valores en cada intervalo. Los histogramas son útiles para identificar la forma de la distribución de los datos, la presencia de valores atípicos y la presencia de múltiples modas.
Para crear un histograma en ggplot2, utilizamos la función geom_histogram(). Tiene dos argumentos de gran importancia:
bins: número de intervalos en los que se agruparán los datos. Si no se especifica, ggplot2 utilizará 30 intervalos.binwidth: ancho de los intervalos. Si se especifica, ggplot2 calculará el número de intervalos automáticamente.
Estos dos argumentos son mutuamente excluyentes. Si se especifica bins, ggplot2 ignorará binwidth.
Vamos a ver la diferencia entre estos dos argumentos viendo la distribución de la longitud de los pétalos de las flores del dataset iris:
Al especificar el número de intervalos lo que hacemos es básicamente indicar el número de barras que queremos generar:
#| standalone: true
#| viewerHeight: 600
## Load packages
library(bslib)
library(ggplot2)
library(glue)
library(shiny)
## UI
ui <- page_sidebar(
sidebar = sidebar(
open = "open",
width = 200,
sliderInput("bins", "Número de intervalos", min = 1, max = 30, value = 15),
),
verbatimTextOutput("code") |> card(),
plotOutput("plot", width = 500) |> card()
)
## Server
server <- function(input, output, session) {
output$code <- renderPrint({
glue(
'ggplot(iris, aes(x = Petal.Length)) +
geom_histogram(bins = {input$bins}, fill = "#0073C2FF", color = "white") +
labs(
title = "Distribución de longitud del pétalo",
x = "Longitud (mm)",
y = "Frecuencia"
)'
)
})
## Plot
output$plot <- renderPlot({
ggplot(iris, aes(x = Petal.Length)) +
geom_histogram(bins = input$bins, fill = "#0073C2FF", color = "white") +
labs(
title = "Distribución de longitud del pétalo",
x = "Longitud (cm)",
y = "Frecuencia"
) +
theme_gray(base_size = 8)
}, res = 96)
}
## Run app
shinyApp(ui = ui, server = server)Cuando seleccionamos el ancho del intervalo (binwidth), estamos seleccionando el tamaño del intervalo en las unidades de la variable que estamos evaluando. Por ejemplo, si seleccionamos un ancho de banda de 0.3 para la longitud del pétalo, estamos indicando que cada barra agrupará observaciones de 3 en 3 milímetros. De 0-0.3 tendremos el primer intervalo, de 0.3-0.6 el segundo, y así sucesivamente.
#| standalone: true
#| viewerHeight: 600
## Load packages
library(bslib)
library(ggplot2)
library(glue)
library(shiny)
## UI
ui <- page_sidebar(
sidebar = sidebar(
open = "open",
width = 200,
sliderInput("bins", "Ancho del intervalo", min = 0.1, max = 2, value = .2, step = .1),
),
verbatimTextOutput("code") |> card(),
plotOutput("plot", width = 500) |> card()
)
## Server
server <- function(input, output, session) {
output$code <- renderPrint({
glue(
'
ggplot(iris, aes(x = Petal.Length)) +
geom_histogram(binwidth = {input$bins}, fill = "#0073C2FF", color = "white") +
labs(
title = "Distribución de longitud del pétalo",
x = "Longitud (mm)",
y = "Frecuencia"
)'
)
})
## Plot
output$plot <- renderPlot({
ggplot(iris, aes(x = Petal.Length)) +
geom_histogram(binwidth = input$bins, fill = "#0073C2FF", color = "white") +
labs(
title = "Distribución de longitud del pétalo",
x = "Longitud (mm)",
y = "Frecuencia"
) +
theme_gray(base_size = 8)
}, res = 96)
}
## Run app
shinyApp(ui = ui, server = server)Los códigos hexadecimales son una forma de representar colores en HTML y CSS. En R, podemos utilizarlos para cambiar el color de los gráficos. En este caso, el color #0073C2FF representa un azul claro. Puedes utilizar generadores de colores online como este para elegir un color.
Un histograma es básicamente esto. Para el color de relleno utilizamos el argumento fill y para el color del contorno utilizamos el argumento color, y este patrón seguirá siendo el mismo para los otros tipos de gráficos de ggplot2.
También te habrás dado cuenta que hemos añadido una función nueva que es labs(). Esta función nos permite añadir etiquetas al gráfico como:
title: título del gráfico.subtitle: subtitulo del gráfico.x: título del eje x.y: título del eje y.caption: pie de figura.
Si bien es cierto que los histogramas son una forma de visualizar la distribución de una sola variable, también podemos crear histogramas para comparar la distribución de una variable numérica entre diferentes grupos. Esto puede ser muy conveniente, ya que si nos fijamos en las figuras anteriores, podemos ver que si indicamos el número de intervalos adecuado sigue una distribución bimodal.
Vamos a ver qué pasa si comparamos la distribución de la longitud de los pétalos de las flores del dataset iris entre las diferentes especies de flores. Para ello, utilizamos el argumento fill en la función aes() para indicar la variable categórica que queremos comparar:
iris |>
ggplot(
aes(x = Petal.Length, fill = Species)
) +
geom_histogram(bins = 30, color = "white") +
labs(
title = "Distribución de longitud del pétalo por especie",
subtitle = "La especie I. setosa tiene una longitud de pétalo menor que I. versicolor e I. virginica",
x = "Longitud (mm)",
y = "Frecuencia",
caption = "Autor: Adrián Cidre"
) +
theme_minimal()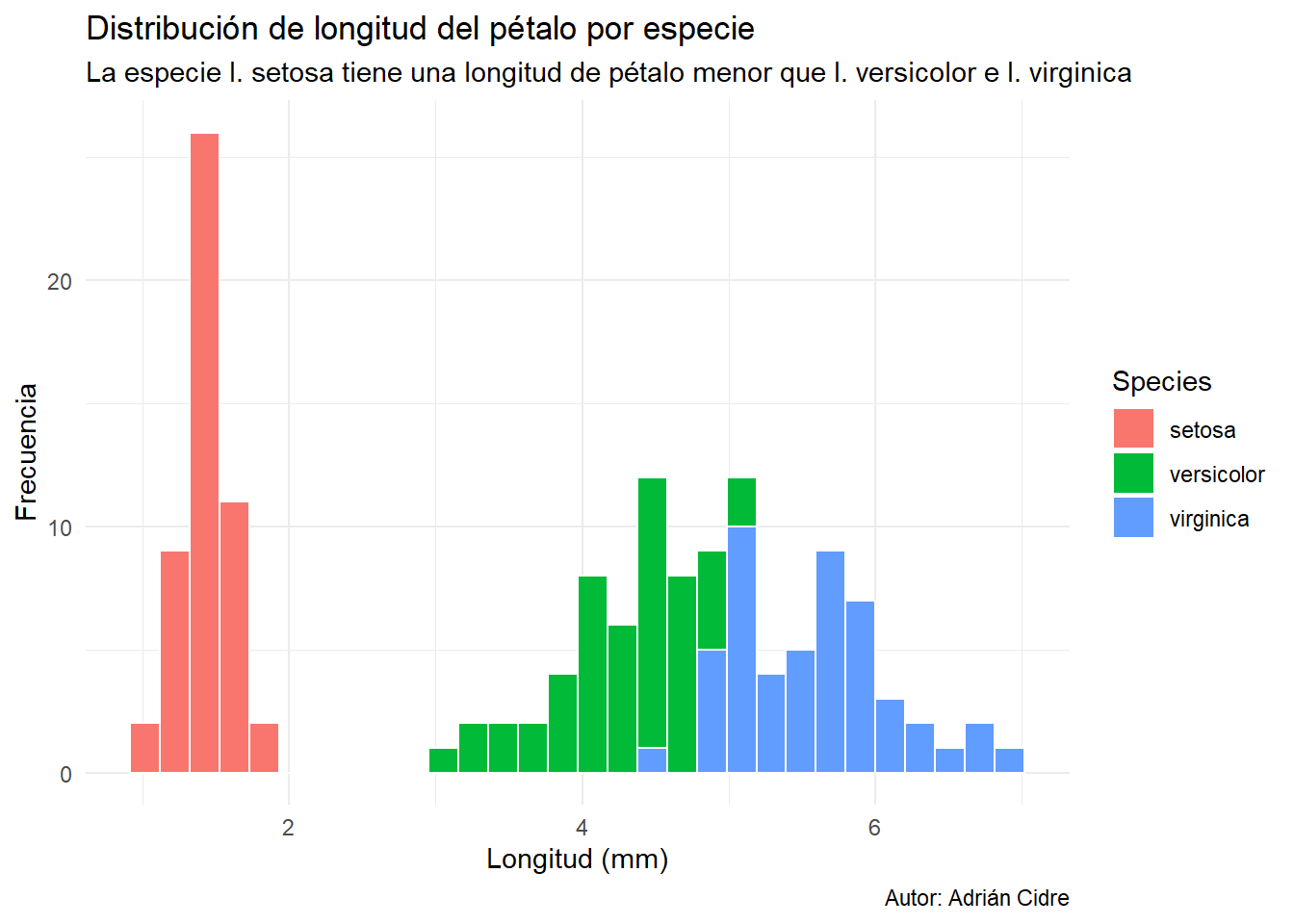
Ahá 🤔! Gracias a utilizar una estética más podemos ver que la distribución no es bimodal, si no que son distribuciones de especies de flores distintas. En esencia, añadir una estética más puede ser visto como añadir una dimensión más al gráfico.
A partir de ahora vamos a ir añadiendo nuevas funciones y argumentos a nuestros gráficos. No te preocupes si no entiendes todo a la primera, poco a poco iremos viendo cómo se utilizan y para qué sirven. En este caso hemos añadido theme_minimal() que nos permite cambiar el tema base del gráfico. Existen una serie de temas predefinidos que empiezan por theme_*().
4.3 Gráficos de densidad
Los gráficos de densidad son una forma de visualizar la distribución de una variable numérica. A diferencia de los histogramas, los gráficos de densidad no agrupan los datos en intervalos, sino que muestran la estimación de densidad kernel de los datos. Los gráficos de densidad son útiles para identificar la forma de la distribución de los datos, ya que son una versión suavizada de los histogramas.
Para crear un gráfico de densidad en ggplot2, utilizamos la función geom_density(). Básicamente, se va a generar una línea que nos va a indicar la densidad de probabilidad de los datos. Como es una línea, tiene una serie de estéticas que podemos modificar a continuación:
#| standalone: true
#| viewerHeight: 600
## Load packages
library(bslib)
library(ggplot2)
library(glue)
library(shiny)
## UI
ui <- page_sidebar(
sidebar = sidebar(
open = "open",
width = 200,
selectInput(
inputId = "linetype_input",
label = "Linetype",
choices = c("solid", "dashed", "dotted",
"dotdash", "longdash", "twodash"),
selected = "solid"
),
sliderInput(
inputId = "linewidth_input",
label = "Linewidth",
min = 0,
max = 4,
value = 1,
step = .5
),
checkboxInput(
inputId = "fill_input",
label = "Rellenar?",
value = FALSE
)
),
verbatimTextOutput("code") |> card(),
plotOutput("plot", width = 500) |> card()
)
## Server
server <- function(input, output, session) {
output$code <- renderPrint({
if (input$fill_input) {
glue(
'ggplot(iris, aes(x = Petal.Length)) +
geom_density(
color = "darkred",
fill = "gray30",
linetype = "{input$linetype_input}",
linewidth = {input$linewidth_input}
) +
labs(
title = "Distribución de longitud del pétalo",
x = "Longitud (mm)",
y = "Probabilidad (%)"
) +
theme_bw(base_size = 8)'
)
} else {
glue(
'ggplot(iris, aes(x = Petal.Length)) +
geom_density(
color = "darkred",
linetype = "{input$linetype_input}",
linewidth = {input$linewidth_input}
) +
labs(
title = "Distribución de longitud del pétalo",
x = "Longitud (mm)",
y = "Probabilidad (%)"
) +
theme_bw()'
)
}
})
## Plot
output$plot <- renderPlot({
ggplot(iris, aes(x = Petal.Length)) +
geom_density(
color = "darkred",
linetype = input$linetype_input,
linewidth = input$linewidth_input,
fill = if (input$fill_input) "gray30" else NA
) +
labs(
title = "Distribución de longitud del pétalo",
x = "Longitud (mm)",
y = "Probabilidad (%)"
) +
theme_bw(base_size = 8)
}, res = 96)
}
## Run app
shinyApp(ui = ui, server = server)4.3.1 Ejercicio 1
Finalmente, al igual que con los histogramas, podemos comparar la distribución de la longitud del pétalo entre las diferentes especies de flores del dataset iris. Te atreves a intentar añadir la parte del código que falta? El resultado debería ser el indicado en la Figura 4.2:
Intenta replicar este gráfico en la pestaña “Ejercicio”
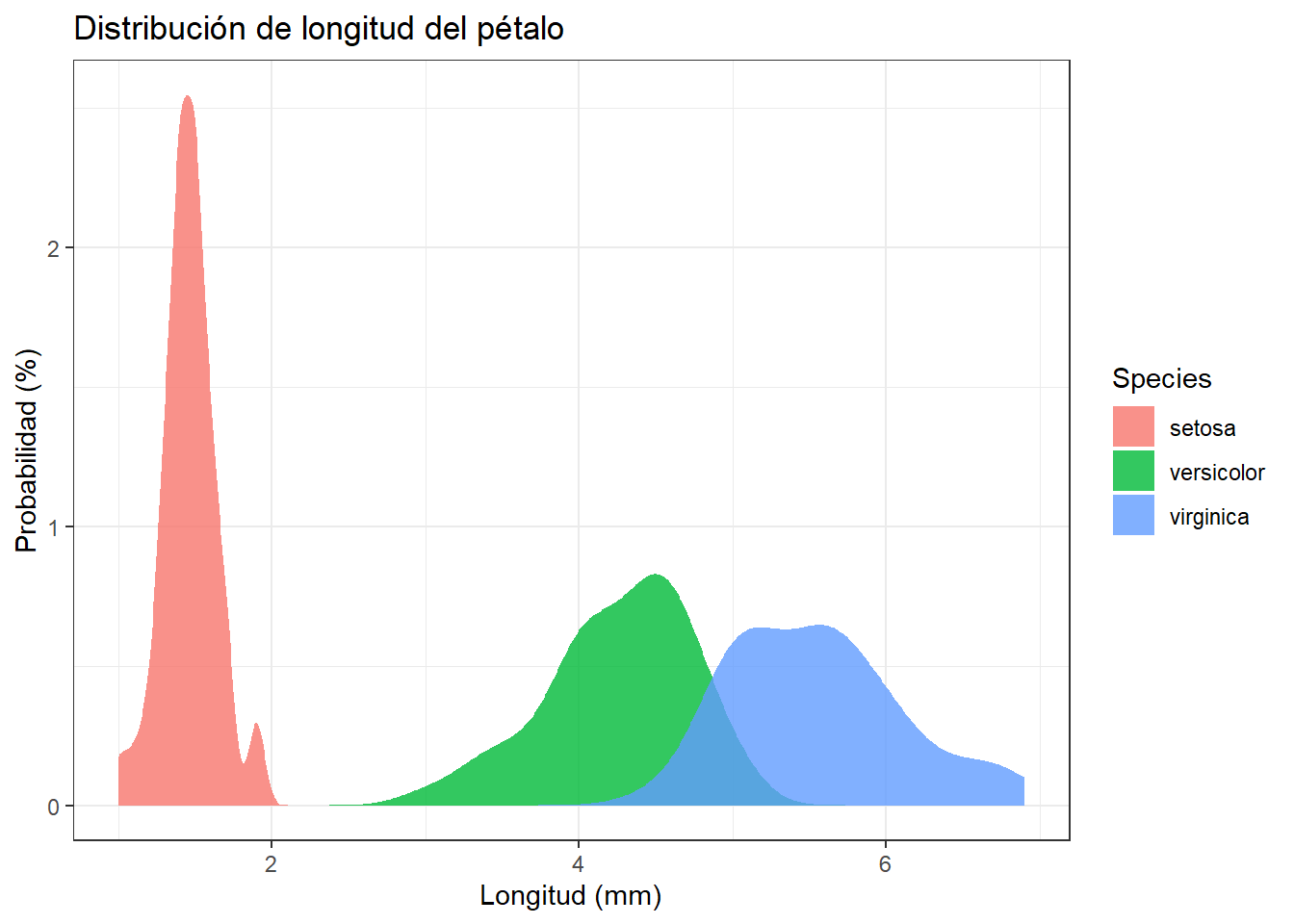
En total hay que añadir tres elementos:
Transparencia (necesaria para poder ver la superposición de densidades)
Eliminar color de contorno
Crear un gráfico de densidad por especie dentro del mismo gráfico
El argumento aes(fill = Species) también se puede introducir en la función ggplot().
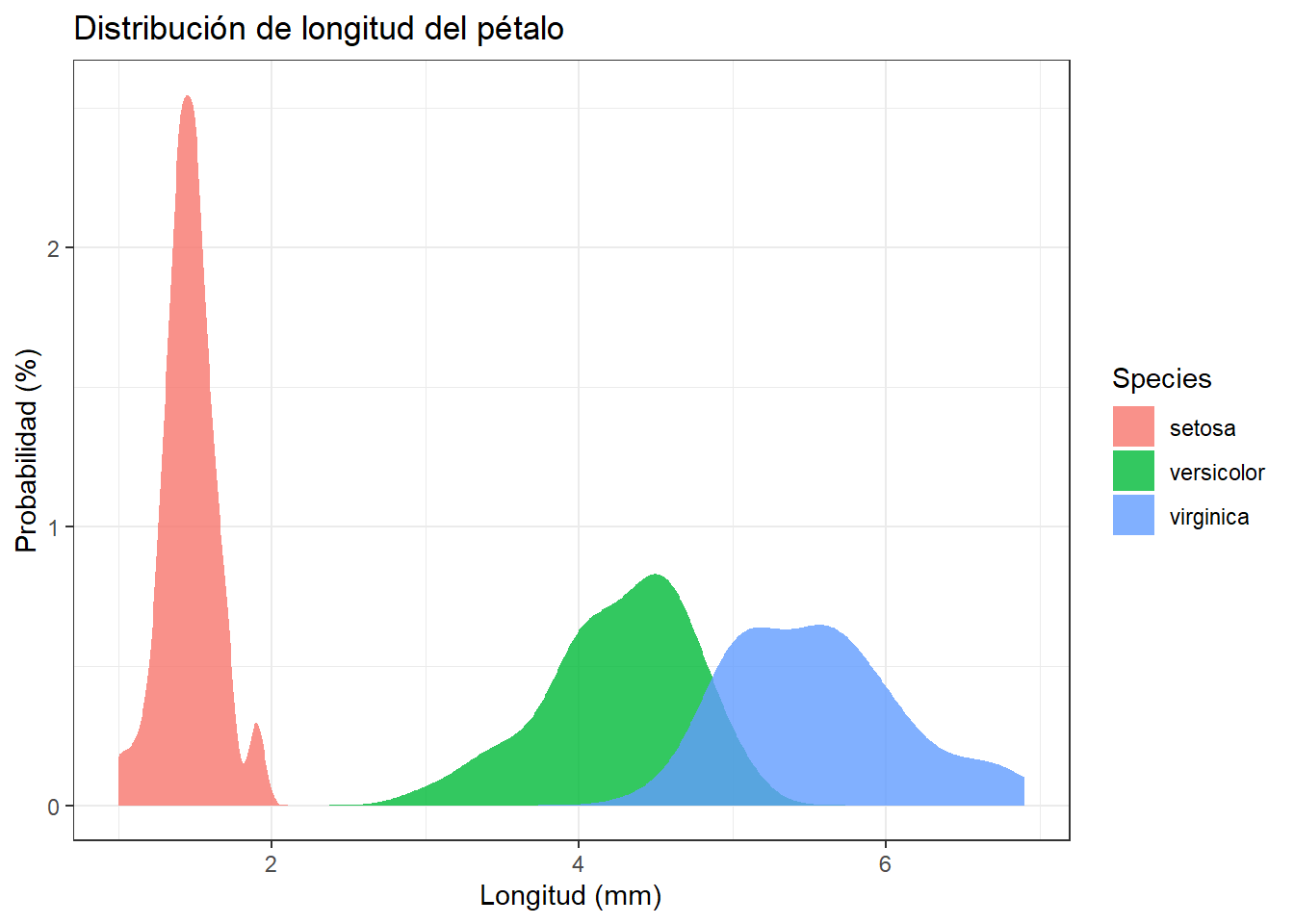
4.3.2 Ejercicio 2
En los siguientes ejercicios vamos a trabajar con los datos de inventario. Vamos a empezar cargando los datos, convertirlos a tibble y vamos a ver de nuevo su estructura:
El ejercicio consiste en generar un histograma de la distribución diamétrica (en centímetros), además generando un gráfico por especie. Utiliza el siguiente bloque de código y practica todo lo que hemos visto hasta ahora:
El siguiente código es una de muchas opciones.
inventario_tbl |>
ggplot(
aes(x = dbh_mm / 10, fill = nombre_ifn)
) +
geom_histogram(
bins = 25,
color = "snow"
) +
labs(
title = "Distribución diamétrica por especie",
x = "Diámetro (cm)",
y = "Frecuencia",
fill = "Especie"
) +
theme_minimal()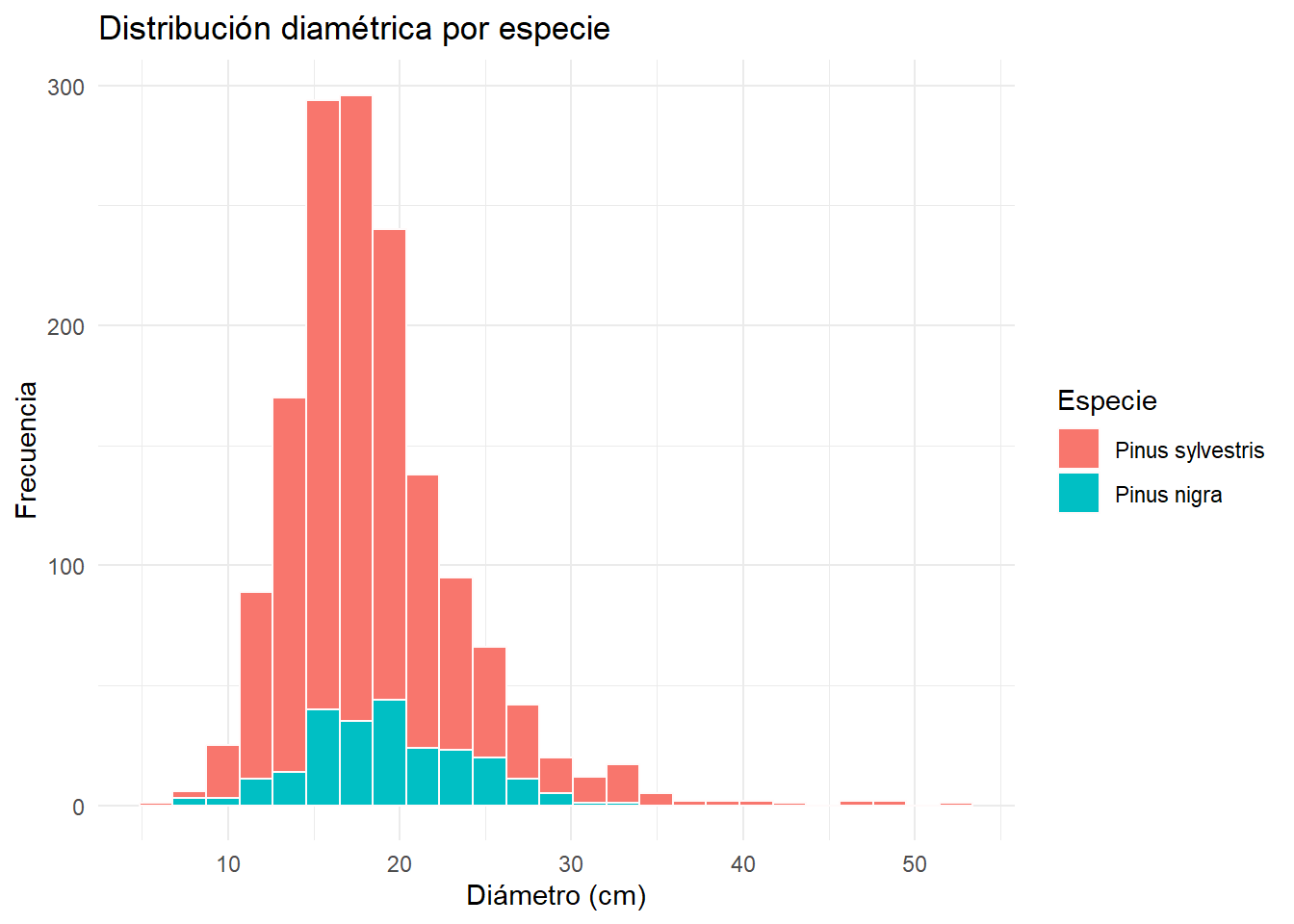
En la Figura 4.4 hemos añadido el argumento fill dentro de la función labs(). Cuando utilizamos una estética como color, fill, shape… dentro de aes(), podemos utilizar el nombre de esta estética dentro de labs() para modificar el título de la leyenda.
4.3.3 Ejercicio 3
Generar un gráfico de densidad para la altura de los árboles por especie.
El siguiente código es una de muchas opciones.
inventario_tbl |>
ggplot(
aes(x = height_m, fill = nombre_ifn)
) +
geom_density(
alpha = .7
) +
labs(
title = "Distribución de alturas por especie",
x = "Altura (m)",
y = "Probabilidad (%)",
fill = "Especie"
) +
theme_minimal()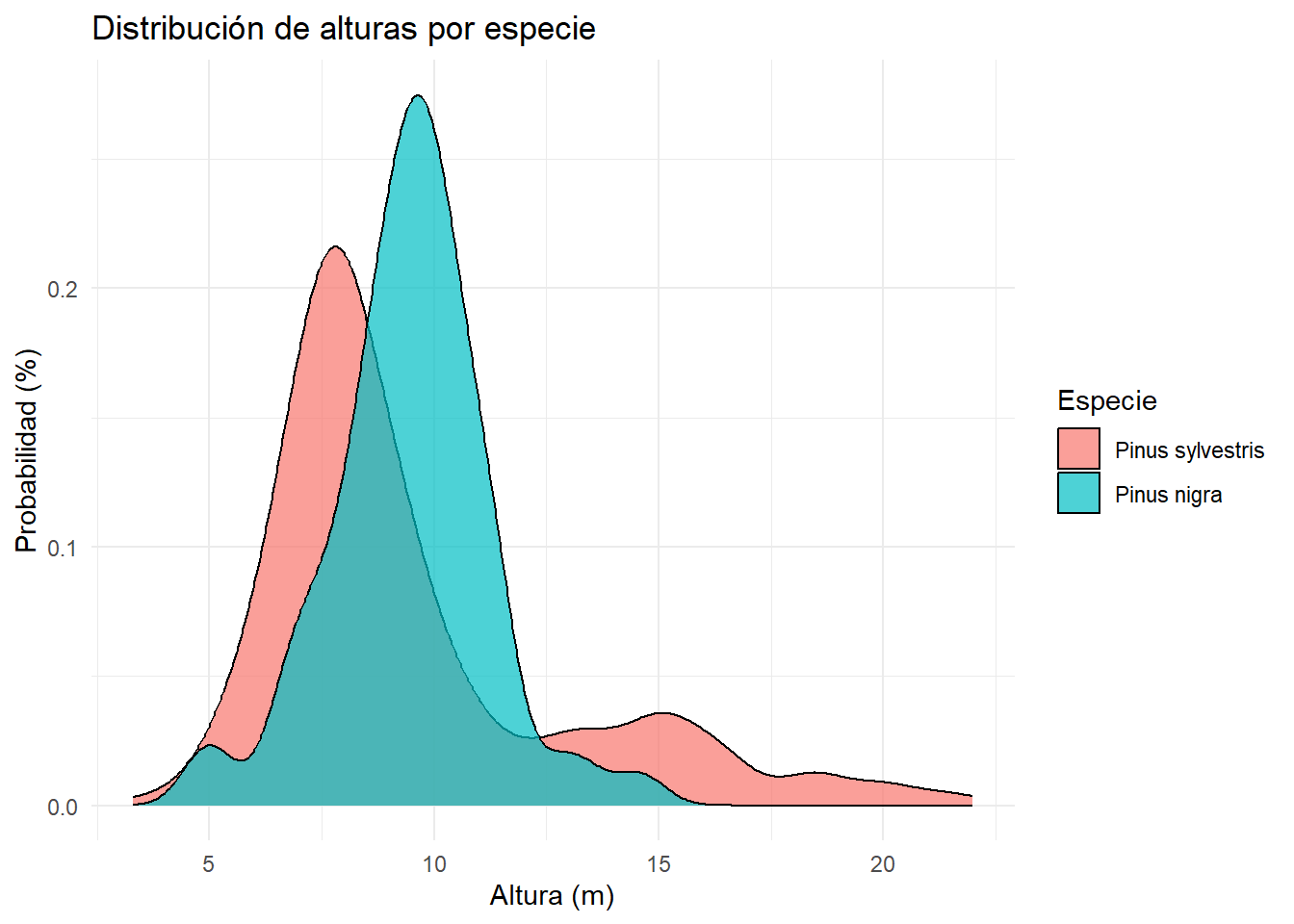
4.3.4 Extra - Añadir líneas
Algo común es añadir líneas a los gráficos que representen algún valor importante como la media o la mediana. En esta breve sección vamos a ver como añadir estas dos líneas a un histograma.
Vamos a empezar con un histograma de la distribución diamétrica de P. sylvestris:
inventario_tbl |>
filter(nombre_ifn == "Pinus sylvestris") |>
ggplot(
aes(x = dbh_mm)
) +
geom_histogram(
color = "snow",
fill = "#0073C2FF"
) +
theme_bw()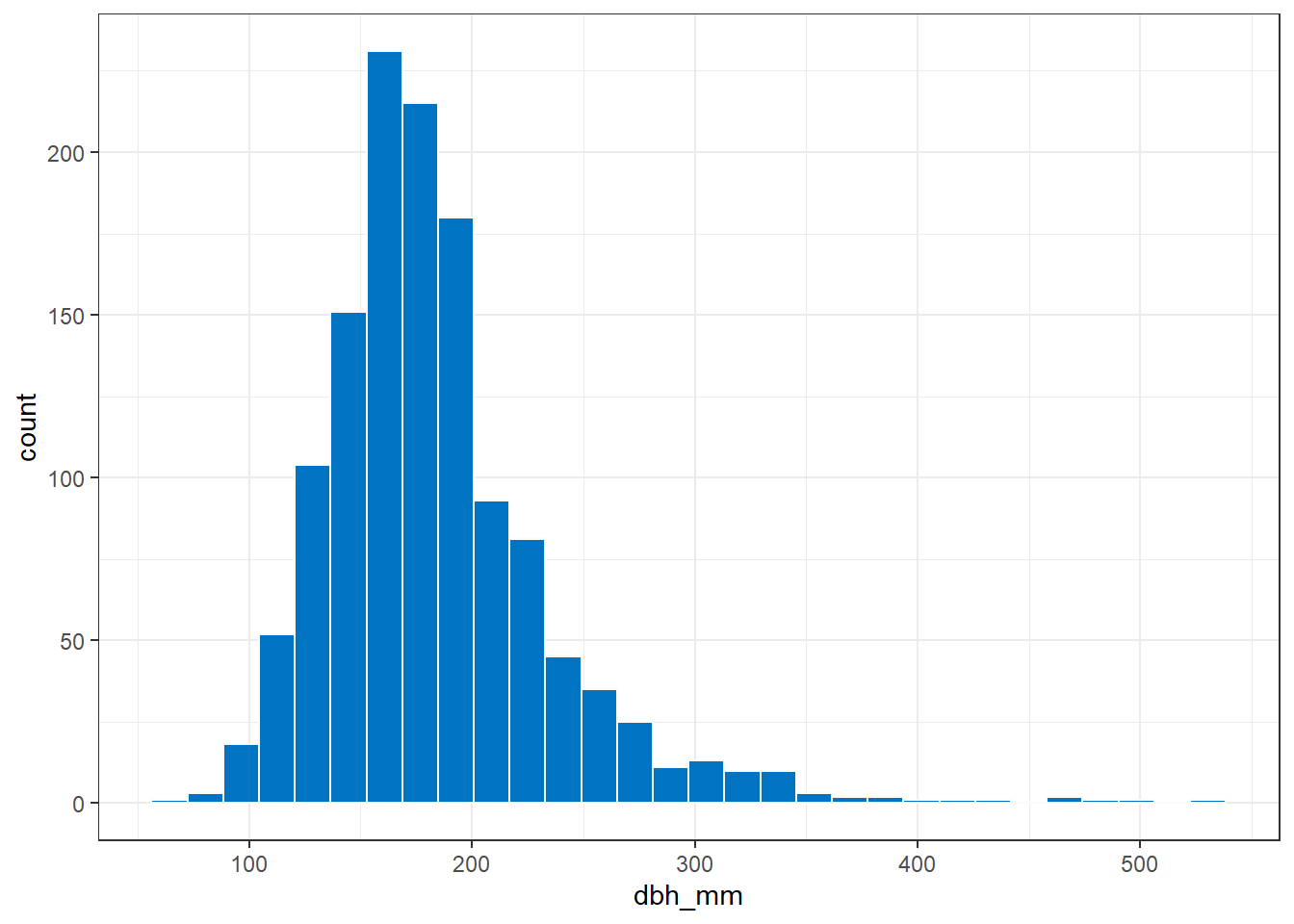
La idea es añadir una línea vertical que nos señale donde se encuentran la media y la mediana. Para ello, tenemos la función geom_vline(). El argumento más importante es:
-
xintercept: valor en el eje x donde se va a situar la línea.
El resto de argumentos pueden consultarse en la documentación de la función, y serán los comunes a geometrías de línea: color, linewidth, linetype…
## Filtrar datos de Pinus sylvestris
## Crear columna de diámetro en cm
psylvestris_tbl <- inventario_tbl |>
filter(nombre_ifn == "Pinus sylvestris") |>
mutate(
dbh_cm = dbh_mm / 10
)
## Gráfico
psylvestris_tbl |>
ggplot(
aes(x = dbh_cm)
) +
geom_histogram(
color = "snow",
fill = "#0073C2FF",
alpha = .7
) +
geom_vline(
aes(xintercept = mean(psylvestris_tbl$dbh_cm, na.rm = TRUE)),
color = "darkred",
size = 1
) +
geom_vline(
xintercept = median(psylvestris_tbl$dbh_cm, na.rm = TRUE),
color = "darkorange",
size = 1
) +
labs(
title = "Distribución diamétrica de Pinus sylvestris",
x = "Diámetro (cm)",
y = "Frecuencia"
) +
theme_bw()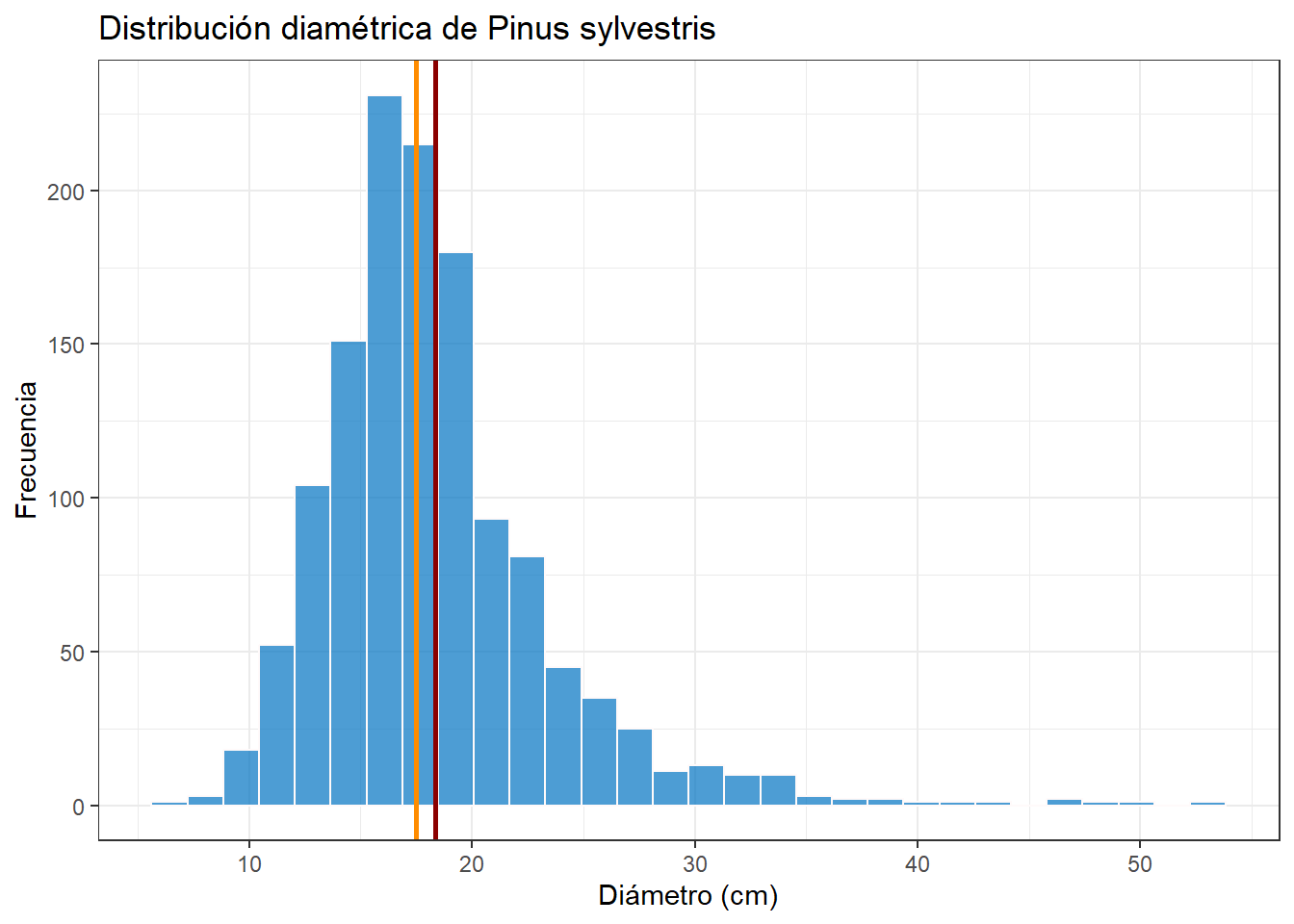
Como solamente utilizamos un valor que generamos con mean() y median(), no es necesario utilizar aes() en geom_vline(). Se muestran ambas opciones para mostrar que es posible utilizar cualquiera de las dos opciones.
4.4 Boxplot
Los boxplot (gráficos de cajas o bigotes) son una forma de visualizar la distribución de una variable numérica. En un gráfico de cajas, se muestra un resumen de la distribución de los datos, incluyendo la mediana, los cuartiles y los valores atípicos. Los gráficos de cajas son útiles para identificar la presencia de valores atípicos y la simetría de la distribución.
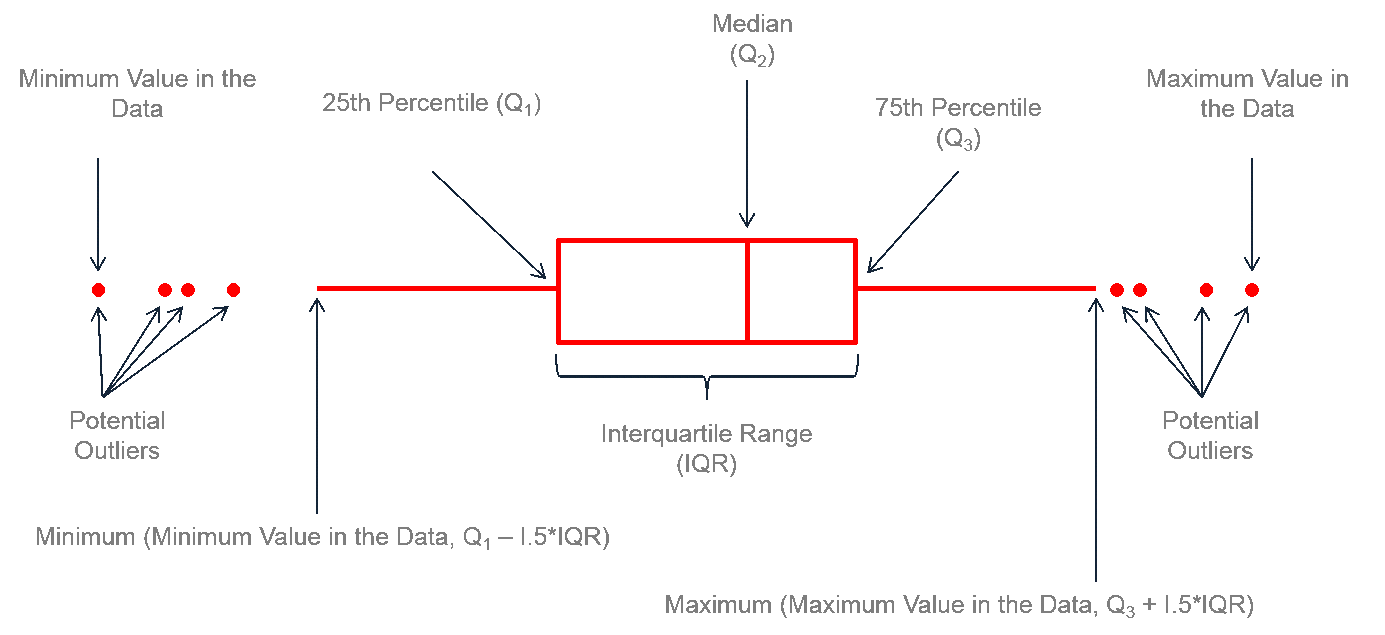
Aunque es un gráfico que nos da un resumen estadístico muy bueno, es un gráfico que nunca se debe utilizar solo. Un boxplot nos está mostrando cinco valores principales: mínimo, primer cuartil, mediana, tercer cuartil y máximo. Sin embargo, no sabemos nada del resto de valores. Fíjate en los siguientes boxplot:
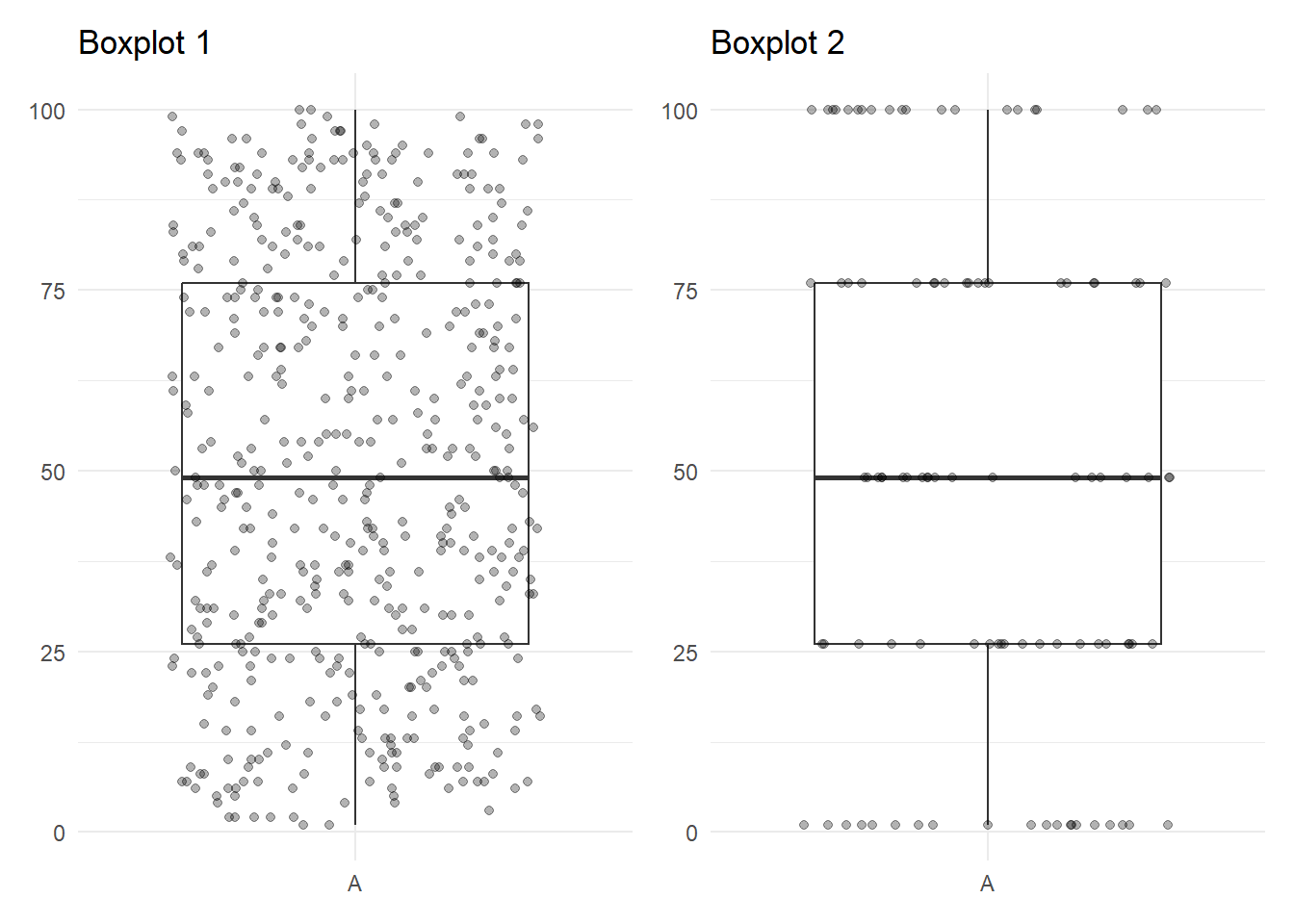
Ambos gráficos tienen exactamente la misma forma, pero como puedes ver en los puntos, los datos son muy distintos. Es por ello que se suelen utilizar variantes del boxplot o el boxplot combinado con otras geometrías como el violin plot.
Una vez vista esta debilidad de los boxplot, vamos a generar uno para la distribución de la longitud de los pétalos del dataset de iris. En este caso, va a ser el primer gráfico de distribución donde utilicemos ambas estéticas de los ejes x e y.
La función geom_boxplot() tiene un montón de argumentos que podemos modificar. Los outliers se representan como puntos, y por ende, podemos modificar todo aquello relacionado con ellos con argumentos que empiezan por outlier.*. Por ejemplo, outlier.shape, outlier.size, outlier.color…
base_boxplot <- iris |>
ggplot(
aes(x = Species, y = Petal.Length)
) +
geom_boxplot(
fill = "orangered",
alpha = .4,
outlier.shape = 21,
outlier.size = 3,
outlier.color = "black",
varwidth = TRUE
) +
labs(
title = "Distribución de la longitud del pétalo por especie",
x = "Especie",
y = "Longitud (mm)"
) +
theme_minimal()
base_boxplot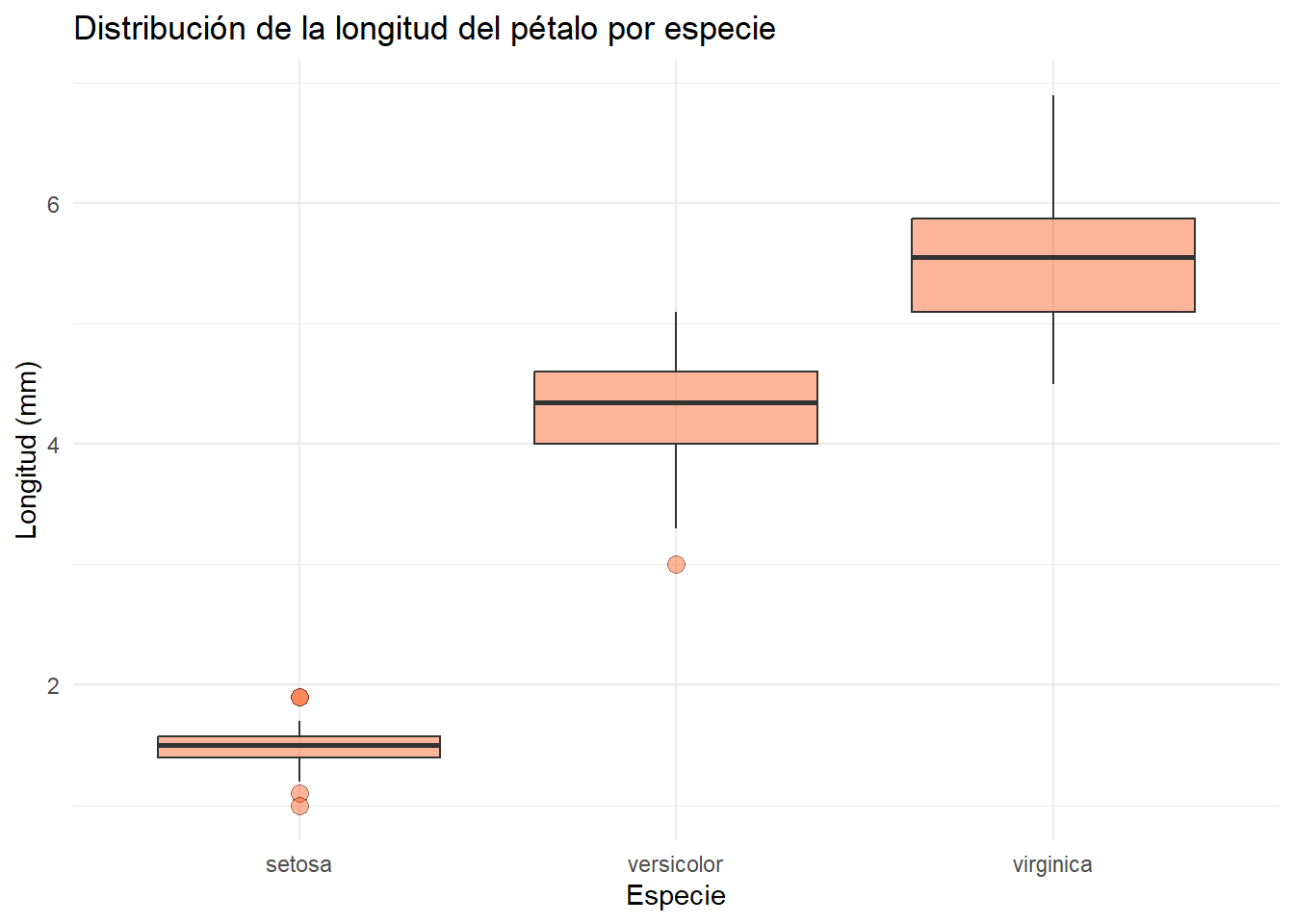
Hemos guardo el gráfico en un objeto llamado base_boxplot para poder añadir más elementos en la siguiente sección.
4.4.1 Boxplot + Jitter
Para añadir la distribución de los datos en un boxplot, podemos utilizar la función geom_point():
base_boxplot +
geom_point()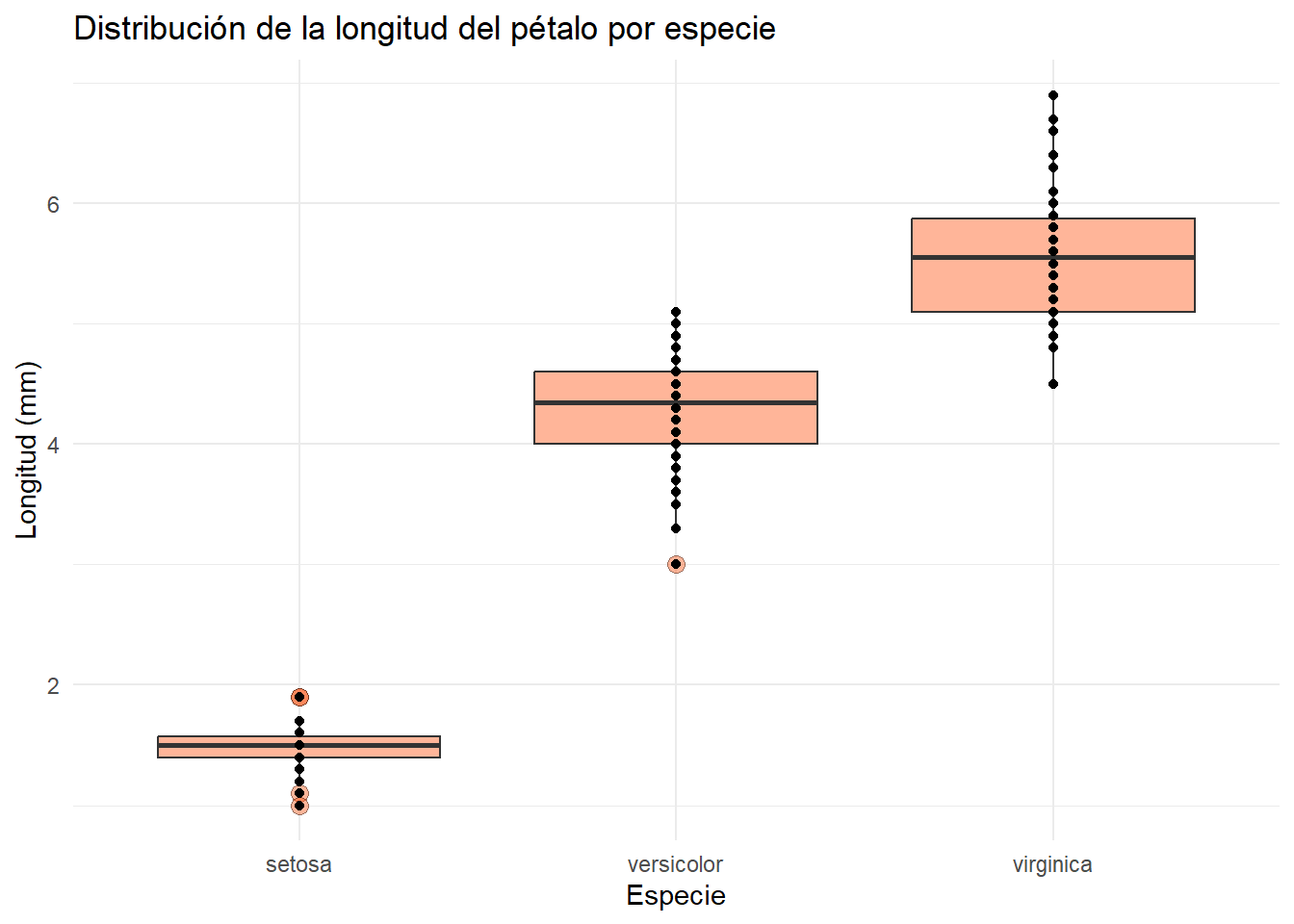
Sin embargo, como puedes ver, los puntos están superpuestos. Para evitar esto, podemos utilizar la función position_jitter() dentro del argumento position que nos permite añadir un poco de ruido a los puntos para que no se superpongan. Esto significa que los puntos tendrán un determinando porcentaje (0-1) de variación en el eje x con el argumento width y en el eje y con el argumento height. Utiliza la siguiente herramienta para ver como funciona:
#| standalone: true
#| viewerHeight: 600
## Load packages
library(bslib)
library(ggplot2)
library(glue)
library(shiny)
## UI
ui <- page_sidebar(
sidebar = sidebar(
open = "open",
width = 200,
sliderInput("width_j", "Width", min = 0, max = 1, value = .5, step = .1),
sliderInput("height_j", "Height", min = 0, max = 1, value = .5, step = .1)
),
verbatimTextOutput("code") |> card(),
plotOutput("plot", width = 500) |> card()
)
## Server
server <- function(input, output, session) {
output$code <- renderPrint({
glue(
'
base_boxplot +
geom_point(
position = position_jitter(
width = {input$width_j},
height = {input$height_j}
),
alpha = .7
)'
)
})
## Plot
output$plot <- renderPlot({
ggplot(iris, aes(x = Species, y = Petal.Length)) +
geom_boxplot(
fill = "orangered",
alpha = .4,
outlier.shape = 21,
outlier.size = 3,
outlier.color = "black",
varwidth = TRUE
) +
labs(
title = "Distribución de la longitud del pétalo por especie",
x = "Especie",
y = "Longitud (mm)"
) +
theme_minimal() +
geom_point(
position = position_jitter(
width = {input$width_j},
height = {input$height_j}
),
alpha = .7
) +
theme_gray(base_size = 8)
}, res = 96)
}
## Run app
shinyApp(ui = ui, server = server)Si ambos son igual a 0, significa que no se añade ruido. si aumentamos width, veremos que los datos se mantienen en sus valores originales según la variable de longitud del pétalo, pero se mueven aleatoriamente a lo largo del eje x. De este modo podemos ver mejor la distribución. No obstante, esto es recomendable solamente en variables categóricas para que los puntos no estén unos encima de otros. En variables numéricas no tiene sentido ya que estamos modificando los datos. Es decir, en este ejemplo height debe ser igual a 0.
Si utilizamos un valor igual o superior a 0.5 los puntos de distintas categorías se superpondrán.
Como esta geometría es muy común, ggplot2 tiene la función geom_jitter() que es un atajo para geom_point(position = position_jitter()):
base_boxplot +
geom_jitter(height = 0, width = .2)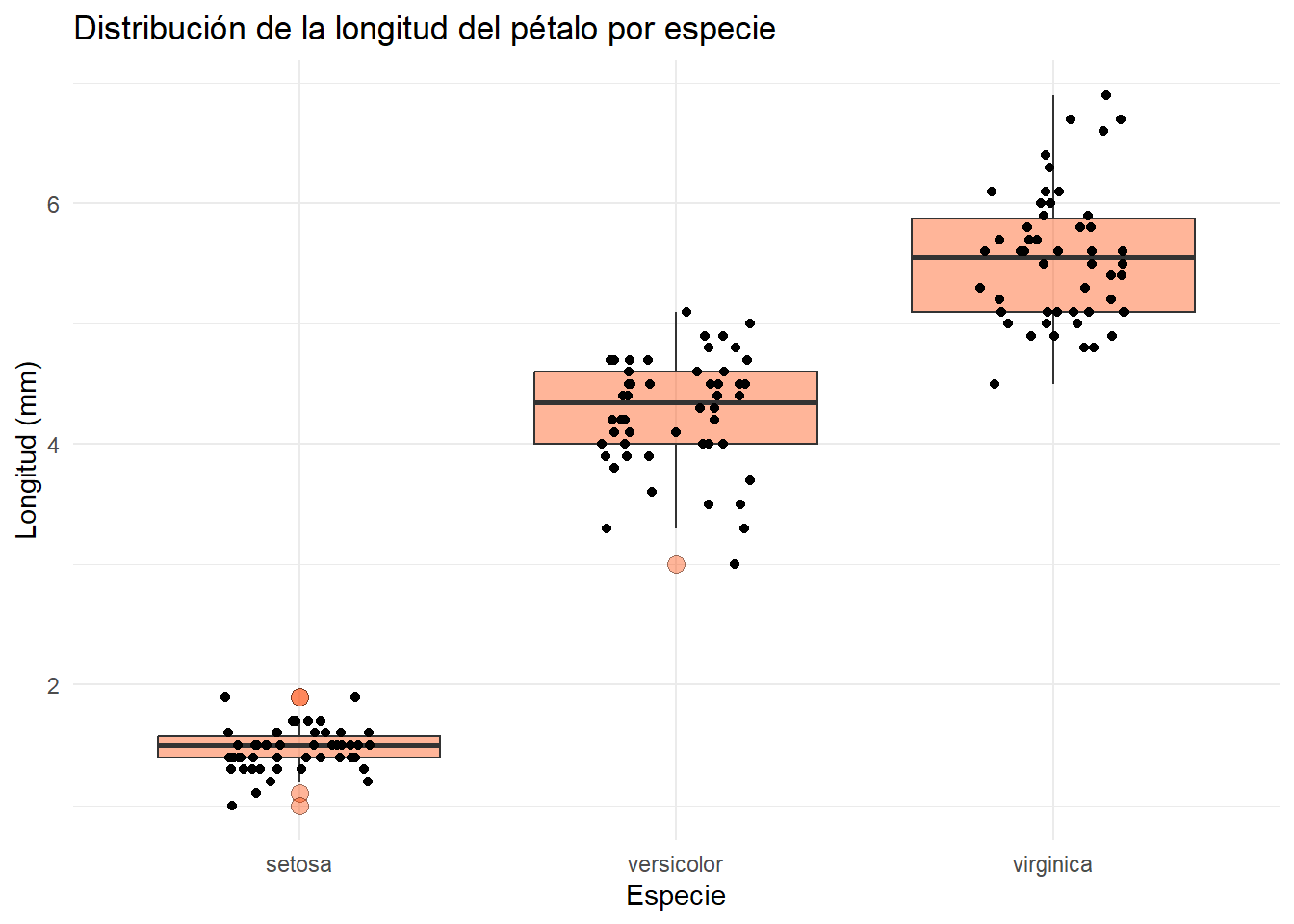
4.4.2 Ejercicio 4
Generar un boxplot de la distribución diamétrica por especie. Además, añadir la distribución de los puntos. Para practicar, utiliza la documentación de geom_boxplot() para modificar distintos argumentos.
El siguiente código es una de muchas opciones.
## Crear boxplot
inventario_tbl |>
ggplot(
aes(x = nombre_ifn, y = dbh_mm / 10)
) +
geom_boxplot(
fill = "#82BE1F",
outlier.shape = 21,
outlier.size = 3,
outlier.fill = "#E121DB",
varwidth = TRUE,
width = .5
) +
geom_jitter(
color = "#7D9E69",
height = 0,
width = .4,
alpha = .3
) +
labs(
title = "Distribución diamétrica por especie",
x = "Especie",
y = "Diámetro (cm)"
) +
theme_minimal()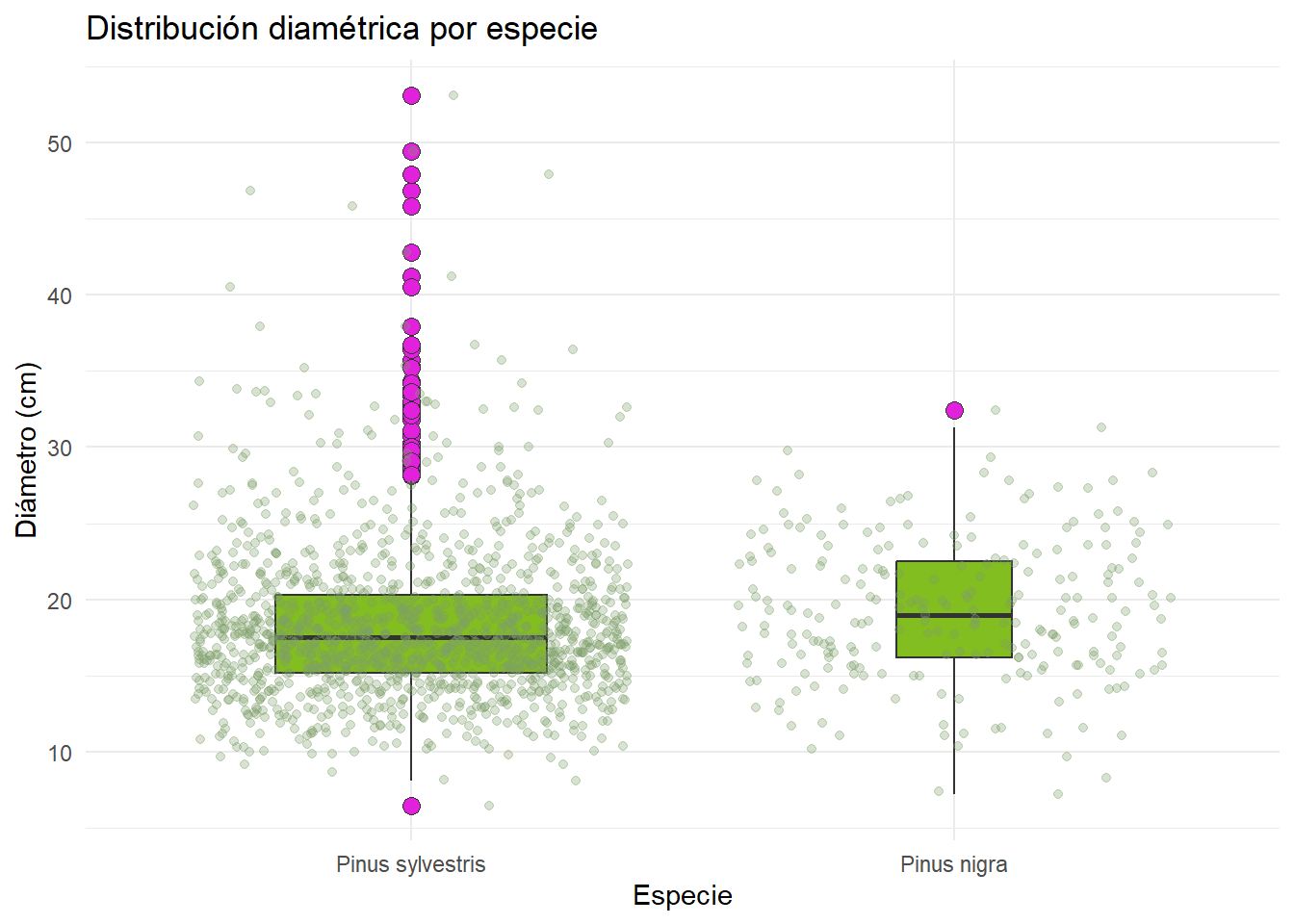
4.4.3 Extra - Añadir media
También es posible añadir la localización de la media mediante un punto en un boxplot. Para ello, utilizamos la función geom_point():
base_boxplot +
geom_point()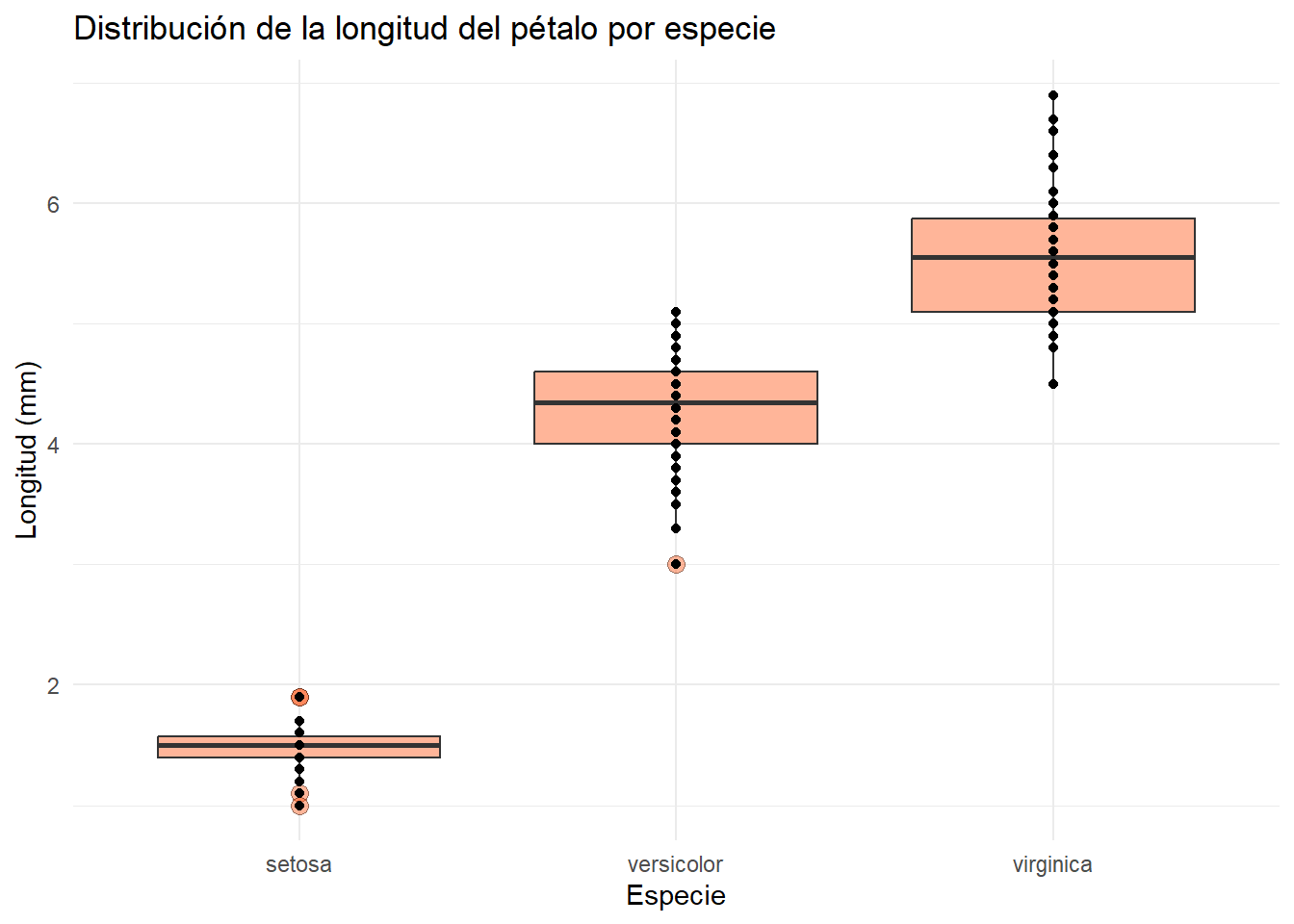
Bueeeno 😅… Recuerdas cuándo hablábamos de las transformaciones estadísticas en Sección 2.4? Pues por defecto geom_point() utiliza stat = "identity", que quería decir que no se aplica ninguna transformación, y por lo tanto \(f(x) = x\). Será ggplot2 tan mágico que nos dejará decir que realice una transformación estadística en la que convierta los puntos a la media? Sí, pero debemos utilizar la transformación estadística summary, y elegir una función de resumen con el argumento fun. En realidad, podemos añadir varias funciones que puedes probar aquí:
#| standalone: true
#| viewerHeight: 600
## Load packages
library(bslib)
library(ggplot2)
library(glue)
library(shiny)
## UI
ui <- page_sidebar(
sidebar = sidebar(
open = "open",
width = 200,
selectInput(
inputId = "fun_input",
label = "Función",
choices = c("min", "max", "mean", "median", "quantile")
)
),
verbatimTextOutput("code") |> card(),
plotOutput("plot", width = 500) |> card()
)
## Server
server <- function(input, output, session) {
output$code <- renderPrint({
glue(
'
base_boxplot +
geom_point(
stat = "summary",
fun = {input$fun_input},
shape = 4,
size = 3,
color = "red"
)'
)
})
## Plot
output$plot <- renderPlot({
ggplot(iris, aes(x = Species, y = Petal.Length)) +
geom_boxplot(
fill = "orangered",
alpha = .4,
outlier.shape = 21,
outlier.size = 3,
outlier.color = "black",
varwidth = TRUE
) +
labs(
title = "Distribución de la longitud del pétalo por especie",
x = "Especie",
y = "Longitud (mm)"
) +
theme_minimal() +
geom_point(
stat = "summary",
fun = {input$fun_input},
shape = 4,
size = 3,
color = "red"
) +
theme_gray(base_size = 8)
}, res = 96)
}
## Run app
shinyApp(ui = ui, server = server)Cualquier función que se pueda aplicar a un vector numérico, se puede añadir dentro del argumento fun, y esto incluye funciones personalizadas.
Si quieres ver las opciones del argumento shape, puedes consultar la documentación de la función points().

4.5 Violin plot
El violin plot es una forma de visualizar la distribución de una variable numérica. A diferencia del boxplot, el violin plot muestra la distribución de los datos de forma más detallada, de forma que no es necesario añadir una capa de puntos jitter para tener una idea de la distribución de los datos.
base_violin <- iris |>
ggplot(
aes(x = Species, y = Petal.Length)
) +
geom_violin(
fill = "#0073C2FF",
color = "white"
) +
labs(
title = "Distribución de la longitud del pétalo por especie",
x = "Especie",
y = "Longitud (mm)"
) +
theme_minimal()
base_violin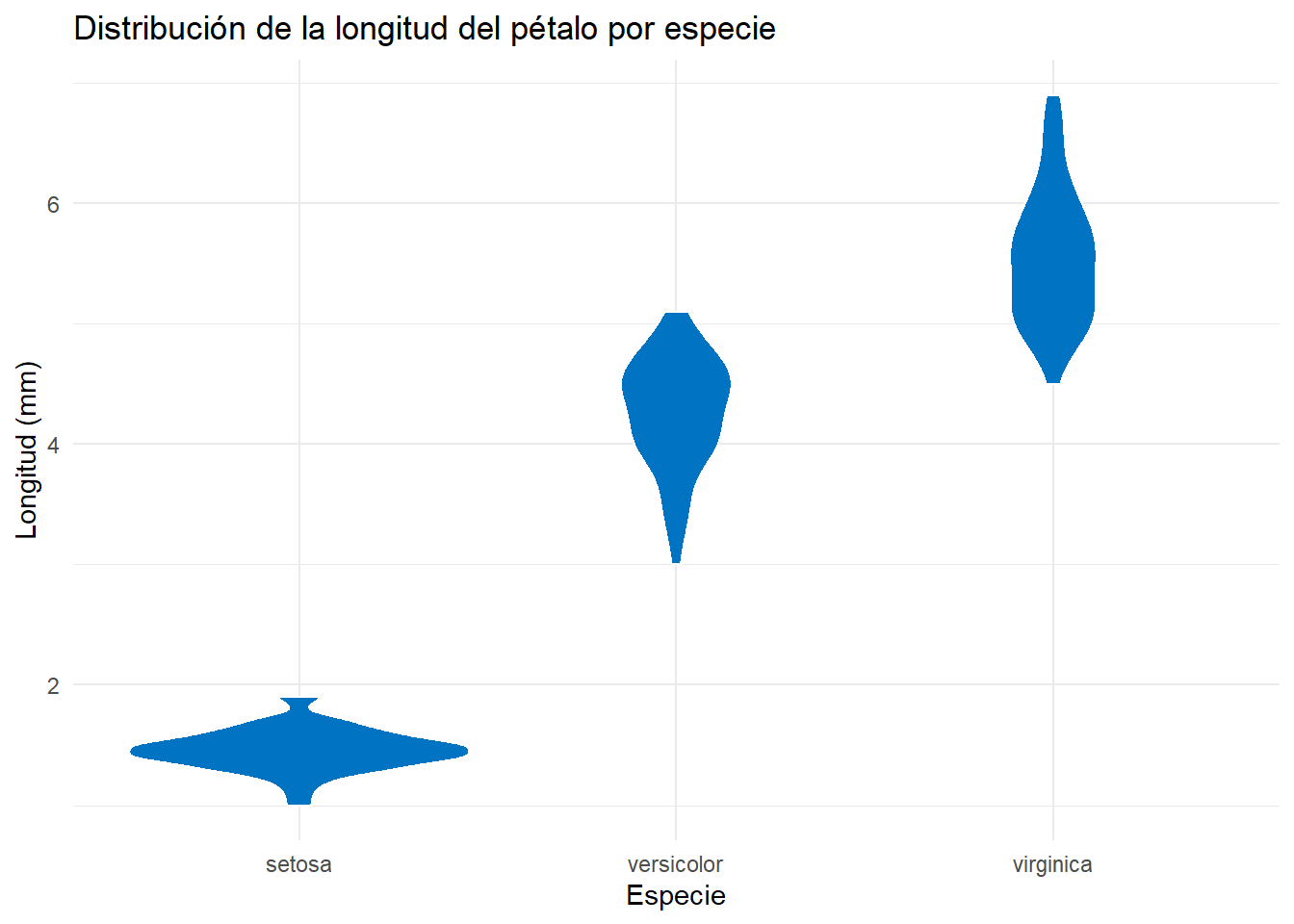
En la Figura 4.15 vemos que los gráficos son más o menos anchos. Cuanto más anchos, más datos hay en esa zona. Para tener una idea de lo que significa, podemos añadir una capa de puntos y así entenderlo mejor:
base_violin +
geom_jitter(
alpha = .5,
height = 0
) 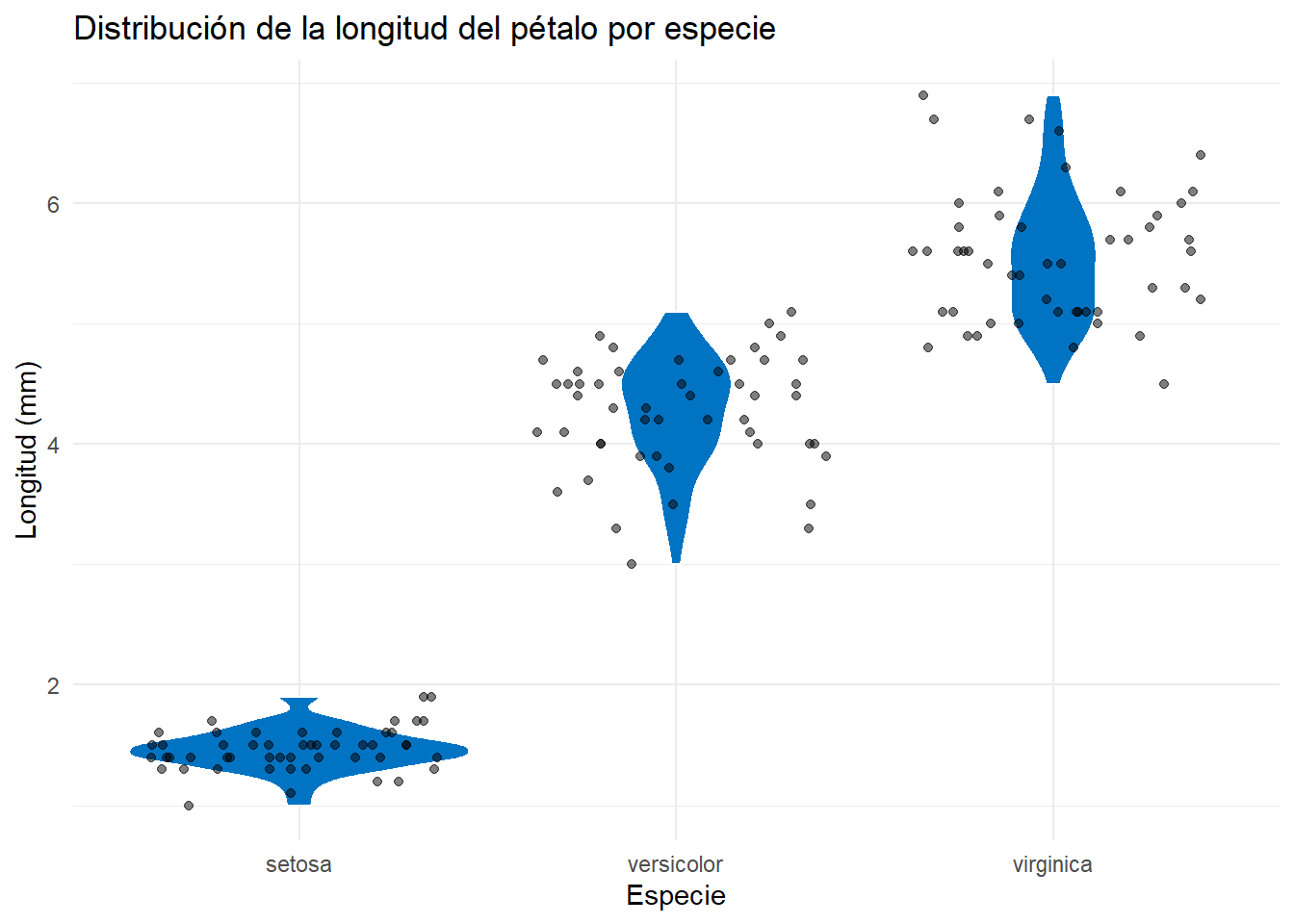
geom_jitter()
Como puedes ver, los puntos se distribuyen en función de la anchura del violin plot. Si la anchura es mayor, significa que hay más datos en esa zona.
Opciones interesantes para modificar el violin plot son:
trim: si esFALSE, el violin plot se extenderá hasta los valores extremos de los datos. Si esTRUE(por defecto), se extenderá hasta el valor más extremo que no sea un valor atípico.scale: si esarea(por defecto), el área de cada violin es proporcional al número de observaciones. Si escount, el ancho de cada violin es proporcional al número de observaciones.draw_quantiles: si esTRUE, se dibujarán los cuantiles del 25%, 50% y 75% en el violin plot.
iris |>
ggplot(
aes(x = Species, y = Petal.Length)
) +
geom_violin(
fill = "#0073C2FF",
color = "white",
trim = TRUE,
scale = "area",
draw_quantiles = c(.25, .5, .75),
) +
labs(
title = "Distribución de la longitud del pétalo por especie",
x = "Especie",
y = "Longitud (mm)"
) +
theme_minimal()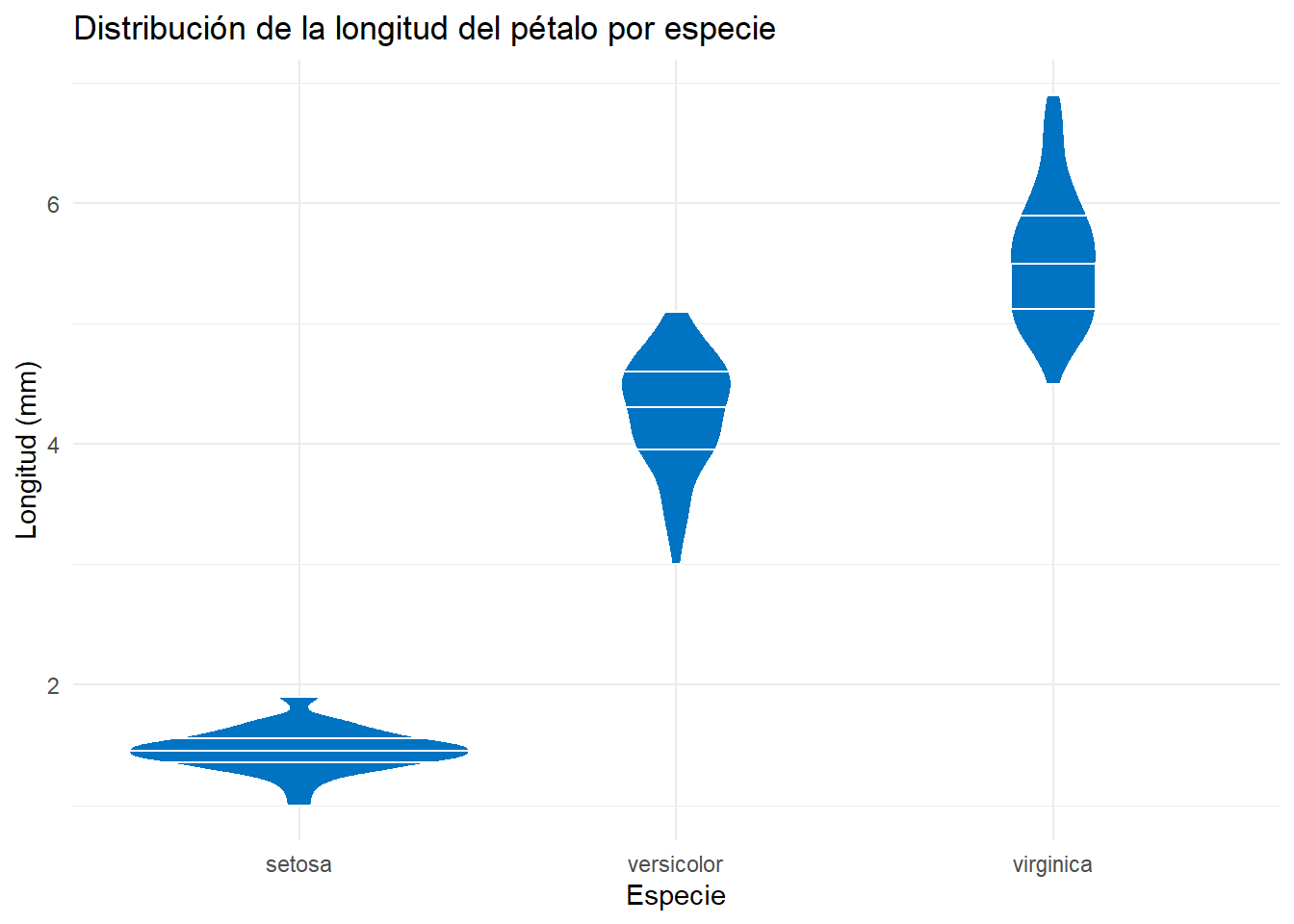
4.5.1 Ejercicio 5
Generar un violin plot de la distribución diamétrica por especie de inventario_tbl. Además, añadir una capa de puntos para ver la distribución de los datos. Visualizar la diferencia entre scale = "area" y scale = "count" y quedarse con el que te parezca más adecuado (en la pestaña “Resultado” se explica cuál es la mejor opción).
El resultado de este ejercicio lo utilizaremos en Sección 4.5.2, así que guarda el violin plot en un objeto llamado violin_ej5_gg.
El siguiente código es una de muchas opciones.
Con scale = "count", vemos que de P. sylvestris tenemos muchos más datos. Si utilizamos scale = "area, esto no lo sabemos. Por lo tanto, es mejor utilizar scale = "count".
## Crear violin plot
violin_ej5_gg <- inventario_tbl |>
ggplot(
aes(x = nombre_ifn, y = dbh_mm / 10)
) +
geom_violin(
fill = "#82BE1F",
color = "transparent",
trim = TRUE,
scale = "count"
) +
labs(
title = "Distribución diamétrica por especie",
x = "Especie",
y = "Diámetro (cm)"
) +
theme_bw()
## Imprimir
violin_ej5_gg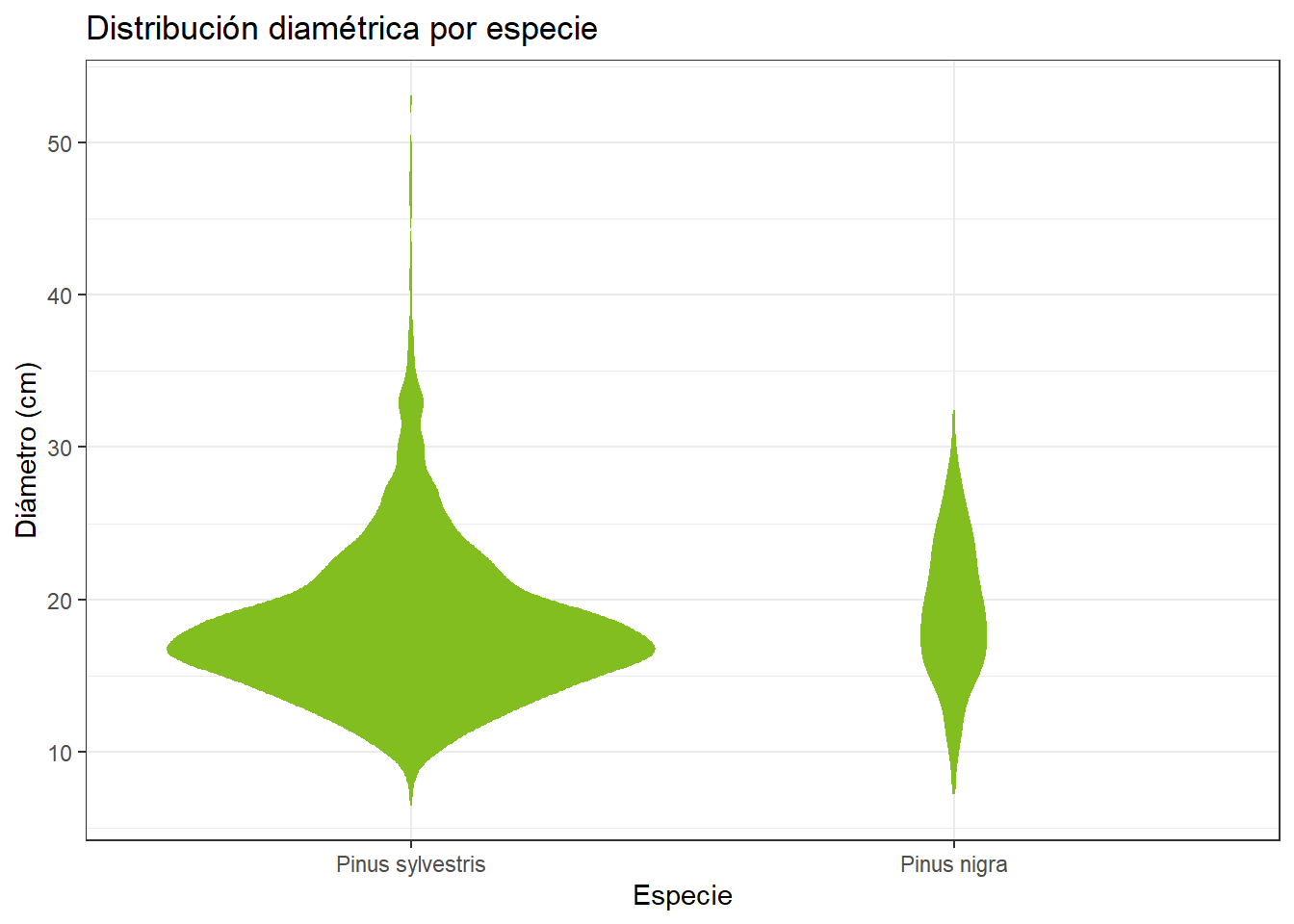
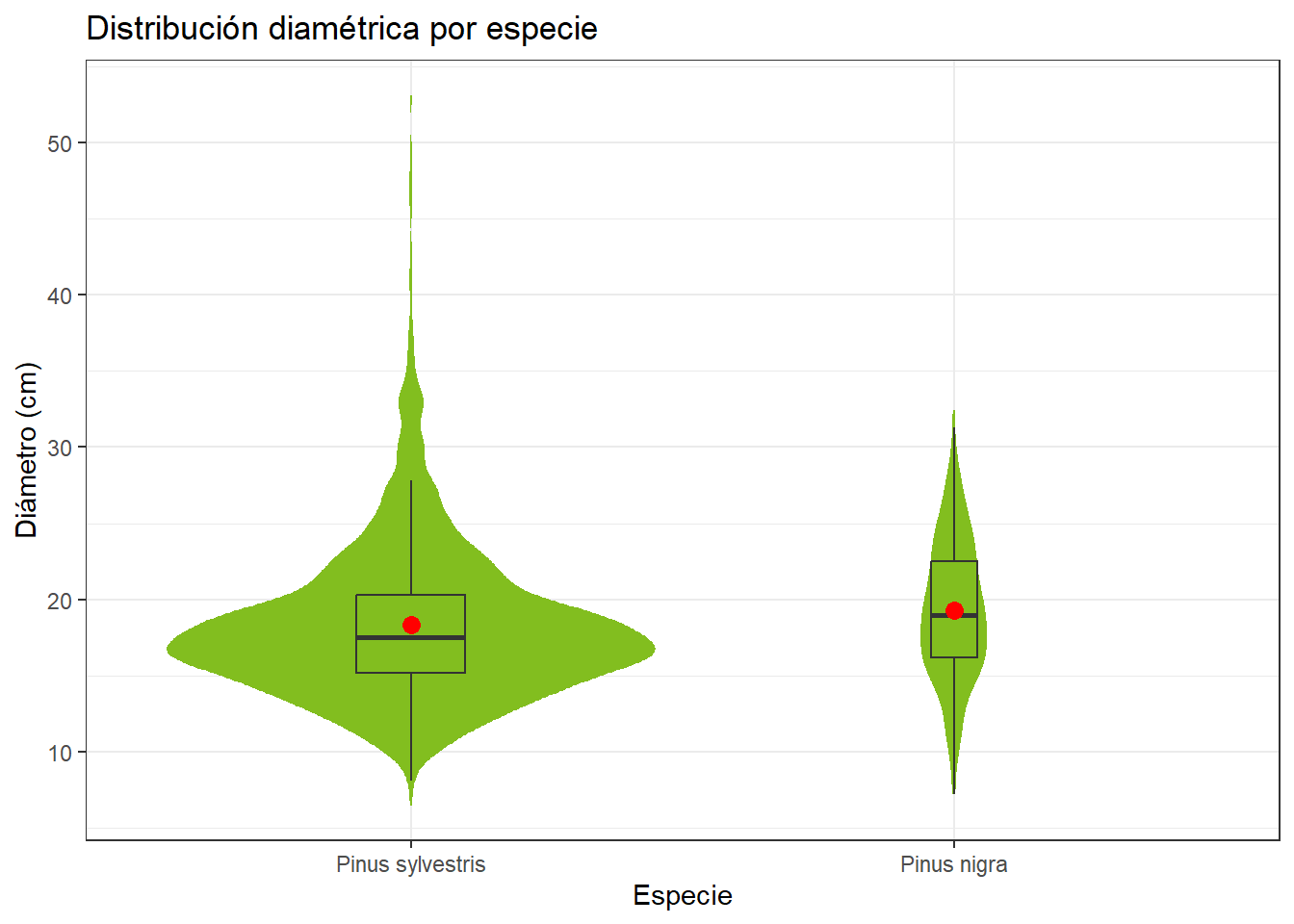
4.5.2 Ejercicio 6
En la Sección 4.5.1 hemos generado un diamétrica por especie que guardamos como violin_ej5_gg. A este gráfico, añadir un boxplot y un punto que represente la media de la distribución.
El siguiente código es una de muchas opciones.
violin_ej5_gg +
geom_boxplot(
fill = "transparent",
outliers = FALSE,
varwidth = TRUE,
width = .2
) +
geom_point(
stat = "summary",
fun = "mean",
shape = 19,
size = 3,
color = "red"
)
Enhorabuena! Has llegado al final de la sección de distribuciones. En la siguiente sección vamos a ver cómo podemos comparar distribuciones entre diferentes grupos.
4.6 Resumen
En esta sección hemos aprendido a visualizar la distribución de una variable numérica utilizando distintos tipos de gráficos. Hemos visto cómo crear histogramas, gráficos de densidad, boxplots y violin plots. Además, hemos aprendido a añadir capas de puntos a los gráficos para ver la distribución de los datos, resúmenes estadísticos como la media y a modificar distintos argumentos de las geometrías.