5 Gráficos de relación
Los gráficos de relación son aquellos que nos permiten visualizar la relación que tienen entre sí dos o más variables. Dentro de los gráficos de relación también se puede denominar gráficos de correlación, y agrupan una familia más grande que la que veíamos en la Figura 1.
En este capítulo veremos los siguientes gráficos de relación:
Gráfico de dispersión (Scatter plot)
Gráfico de burbujas (Bubble plot)
Mapas de calor (Heatmap)
En este capítulo vamos a trabajar con tres datasets:
iris: dataset donde se han medido la longitud y anchura de pétalos y sépalos de 150 flores, además de la especie a la que pertenecen (ver Tipos de visualización).gapminder: dataset con la evolución temporal del desarrollo económico, población y esperanza de vida de los países del mundo (ver Tipos de visualización). Filtraremos solamente los datos del 2002.inventario: dataset con datos de inventario de 27 parcelas en los que se ha medido el DBH, altura y especie (ver Sección 2.2).
Para comenzar, vamos a cargar los paquetes necesarios y a leer los datos que utilizaremos en este capítulo.
5.1 Objetivos
Al final de este capítulo serás capaz de:
Utilizar un tema distinto por defecto
Crear gráficos de dispersión y burbujas
Crear mapas de calor
Crear gráficos de correlación
Añadir texto como geometría a los gráficos
Controlar colores utilizando
scalesMover la leyenda
5.2 Gráficos de dispersión
Antes de empezar, vamos a ver como modificar el tema que viene por defecto en ggplot2, para que no tengamos que añadirlo en cada gráfico que hagamos.
Utilizando la función theme_set() podemos establecer un tema por defecto para todos los gráficos que hagamos en el documento. En este caso, hemos seleccionado el tema theme_classic(), que es uno de los temas más utilizados en ggplot2.
theme_set(
theme_classic()
)Los gráficos de dispersión son una de las formas más comunes de visualizar la relación entre dos variables numéricas. En un gráfico de dispersión, cada punto representa una observación y se coloca en el eje x según el valor de la primera variable y en el eje y según el valor de la segunda variable.
Para crear un gráfico de dispersión en ggplot2 se utiliza la función geom_point(). A continuación, se muestra un ejemplo de cómo crear un gráfico de dispersión utilizando el dataset gapminder relacionando el PIB per cápita con la esperanza de vida, y coloreando los puntos según el continente.
## Crear gráfico
base_scatter_gg <- gapminder_tbl |>
ggplot(
aes(x = gdpPercap, y = lifeExp, color = continent)
) +
geom_point(
size = 2
) +
labs(
x = "PIB per cápita",
y = "Esperanza de vida"
)
## Imprimir
base_scatter_gg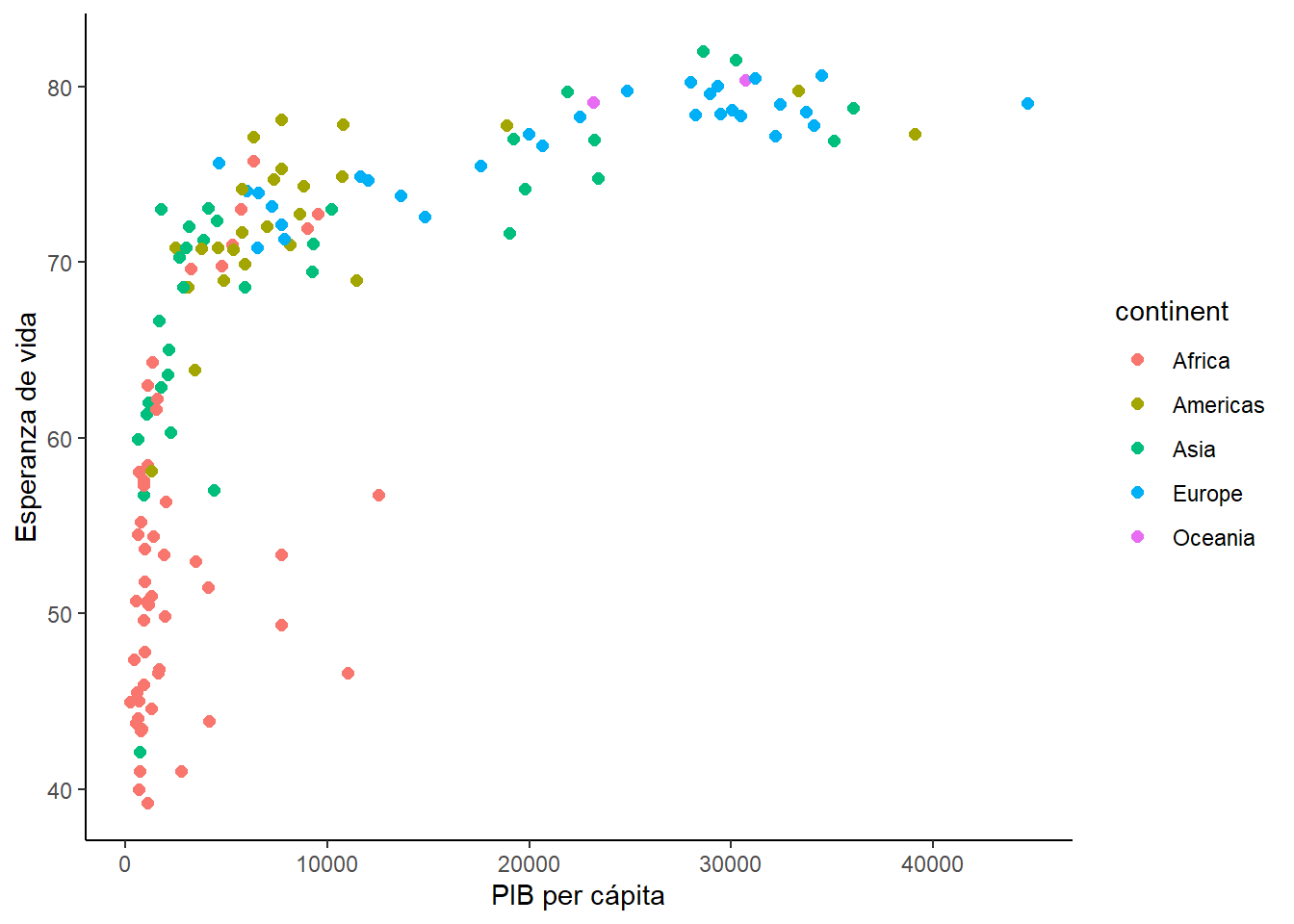
Fíjate que como hemos utilizado theme_set() al principio del documento, no hemos tenido que añadir theme_classic() en el gráfico.
Pues así de sencillo es crear un gráfico de dispersión en ggplot2. Como ya estamos familiarizados con la funcionalidad básica, vamos a aprender a cambiar los colores de los puntos y a mover la leyenda.
Vamos a empezar modificando los colores de cada uno de los continentes para que sean:
África: naranjaAmérica: negroAsia: lilaEuropa: azulOceanía: verde
Si recordáis, en la Sección 3.3 veíamos que las variables numéricas traen por defecto una escala continua (i.e. scale_*_continuous()) y las variables categóricas una escala de discreta (i.e. scale_*_discrete()).
En este caso, queremos cambiar los colores de las especies, y para ello tenemos que modificar la escala a manual con la función scale_color_manual(). A continuación, se muestra el código para cambiar los colores de las especies:
## Crear gráfico
scales_scatter_gg <- base_scatter_gg +
scale_color_manual(
name = "Continente",
values = c("#FF5733", "black", "#A833FF", "#3366FF", "#33FF57")
)
## Imprimir
scales_scatter_gg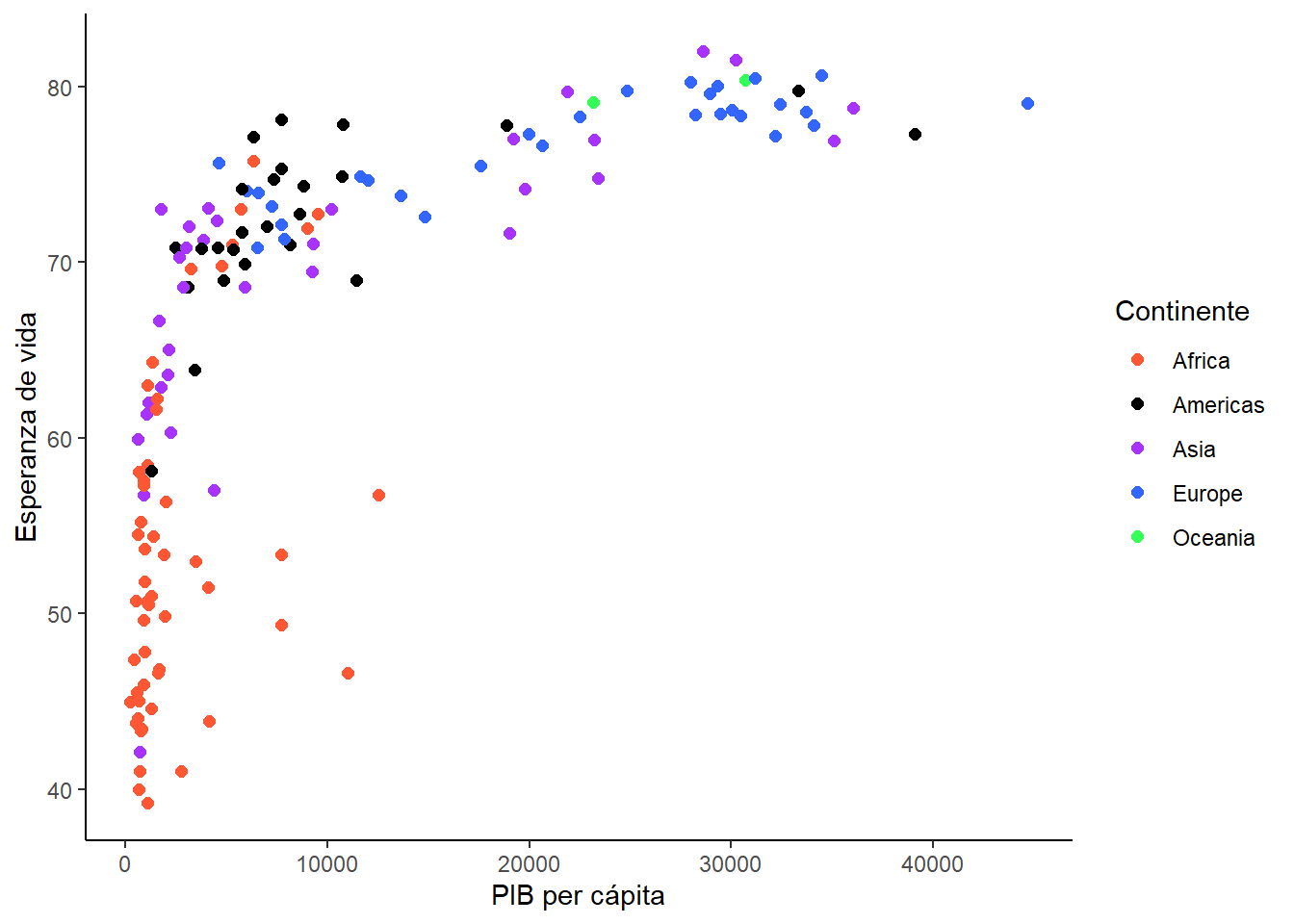
Con el argumento name de las funciones scale* podemos cambiar el nombre de la leyenda, y en values tenemos que especificar un vector con los colores que queremos asignar a cada categoría.
En Figura 5.2 hemos asignado a values un vector de longitud 5 porque tenemos 5 categorías (1 por continente). Si asignamos más colores de los necesarios, la función los ignorará, mientras que si asignamos menos, la función nos dará el error: Insufficient values in manual scale
Lo siguiente que vamos a aprender es a mover la leyenda. Aquí tenemos dos opciones:
Utilizar una posición relativa al gráfico
Utilizar una posición absoluta dentro del gráfico
Vamos a utilizar el método introducido en la versión 3.5.0 de ggplot2 que es el siguiente:
La posición relativa es la más sencilla. La forma recomendable es la siguiente, ya que si tuviéramos más de una leyenda, podríamos controlar la posición de cada una dentro de guides.
Lo que estamos haciendo es: (1) utilizar la función guides; (2) como argumento utilizar el nombre la estética de la leyenda que queremos modificar (color); (3) utilizar la función guide_legend() que tiene muchos argumentos para modificar la leyenda.
#| standalone: true
#| viewerHeight: 600
## Load packages
library(bslib)
library(dplyr)
library(gapminder)
library(ggplot2)
library(glue)
library(shiny)
## UI
ui <- page_sidebar(
sidebar = sidebar(
open = "open",
width = 200,
selectInput(
inputId = "position_input",
label = "Posición",
choices = c("bottom", "top", "left", "right", "inside"),
)
),
verbatimTextOutput("code") |> card(),
plotOutput("plot", width = 500) |> card()
)
## Server
server <- function(input, output, session) {
output$code <- renderPrint({
glue(
'
scales_scatter_gg +
guides(
color = guide_legend(
position = "{input$position_input}"
)
)'
)
})
## Plot
output$plot <- renderPlot({
gapminder |>
filter(year == 2002) |>
ggplot(
aes(x = gdpPercap, y = lifeExp, color = continent)
) +
geom_point(
size = 2
) +
labs(
x = "PIB per cápita",
y = "Esperanza de vida"
) +
scale_color_manual(
name = "Continente",
values = c("#FF5733", "black", "#A833FF", "#3366FF", "#33FF57")
) +
guides(
color = guide_legend(
position = {input$position_input}
)
) +
theme_bw(base_size = 8)
}, res = 96
)
}
## Run app
shinyApp(ui = ui, server = server)Para la posición absoluta, debemos utilizar position = "inside". Una vez hecho esto, debemos modificar el argumento legend.position.inside dentro de la función theme() indicar un vector numérico de longitud 2, donde el primer número indica el % de desplazamiento sobre el eje x desde el origen, mientras que el segundo número indica el % de desplazamiento sobre el eje y. Prueba a cambiar los valores en la siguiente aplicación para entender su funcionamiento:
#| standalone: true
#| viewerHeight: 600
## Load packages
library(bslib)
library(dplyr)
library(gapminder)
library(ggplot2)
library(glue)
library(shiny)
## UI
ui <- page_sidebar(
sidebar = sidebar(
open = "open",
width = 200,
sliderInput(
inputId = "position_input_x",
label = "Posición eje x",
min = 0,
max = 1,
value = 0.5,
step = 0.1
),
sliderInput(
inputId = "position_input_y",
label = "Posición eje y",
min = 0,
max = 1,
value = 0.5,
step = 0.1
)
),
verbatimTextOutput("code") |> card(),
plotOutput("plot", width = 500) |> card()
)
## Server
server <- function(input, output, session) {
output$code <- renderPrint({
glue(
'
scales_scatter_gg +
guides(
color = guide_legend(
position = "inside"
)
) +
theme(
legend.position.inside = c({input$position_input_x}, {input$position_input_y})'
)
})
## Plot
output$plot <- renderPlot({
gapminder |>
filter(year == 2002) |>
ggplot(
aes(x = gdpPercap, y = lifeExp, color = continent)
) +
geom_point(
size = 2
) +
labs(
x = "PIB per cápita",
y = "Esperanza de vida"
) +
scale_color_manual(
name = "Continente",
values = c("#FF5733", "black", "#A833FF", "#3366FF", "#33FF57")
) +
guides(
color = guide_legend(
position = "inside"
)
) +
theme_bw(base_size = 8) +
theme(
legend.position.inside = c(input$position_input_x, input$position_input_y))
}, res = 96
)
}
## Run app
shinyApp(ui = ui, server = server)5.3 Gráficos de burbujas
Los gráficos de burbujas son una extensión de los gráficos de dispersión, donde se añade una tercera variable numérica que se representa mediante el tamaño de los puntos.
En la práctica, si utilizamos las estéticas de color y size, estamos visualizando 4 variables numéricas al mismo tiempo!!
En ggplot2, podemos añadir una tercera variable utilizando la estética size en la función aes(). Al scatter plot anterior, vamos a añadirle como variable de size la población. Como vamos a añadir nuevos elementos, vamos a añadir el código paso a paso:
Empezamos generando un bubble plot añadiendo la variable pop:
## Crear gráfico
bubble_base <- gapminder_tbl |>
ggplot(
aes(x = gdpPercap, y = lifeExp, color = continent, size = pop)
) +
geom_point(
alpha = 0.7
) +
labs(
x = "PIB per cápita",
y = "Esperanza de vida"
) +
scale_color_manual(
name = "Continente",
values = c("#FF5733", "black", "#A833FF", "#3366FF", "#33FF57")
)
## Imprimir
bubble_base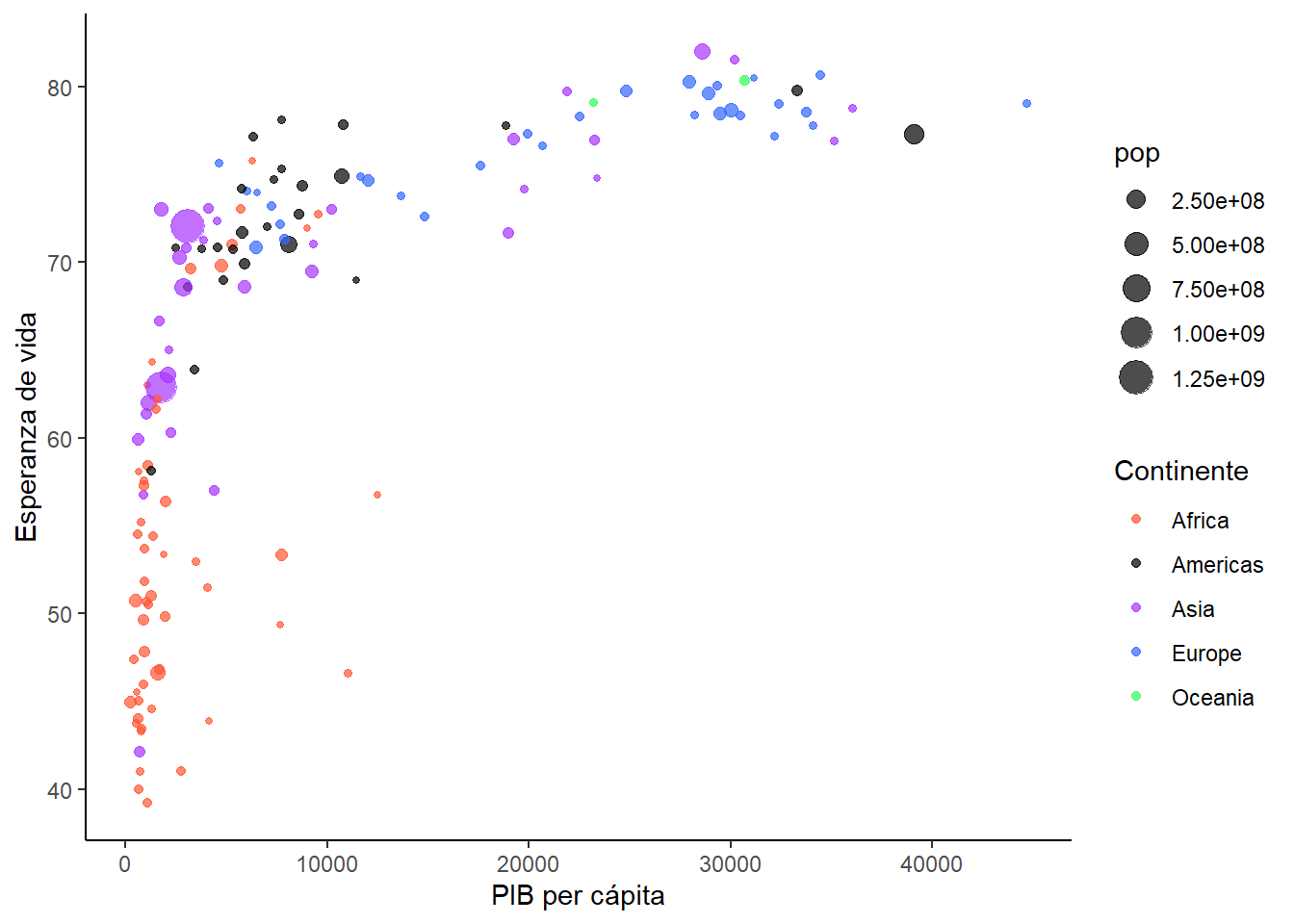
El tamaño de los puntos al igual que el color de los mismos es una estética. Para modificar una estética mapeada a una variable utilizamos las funciones scale_*. Como la estética es size, utilizamos scale_size*(). En el argumento range indicamos el tamaño del punto más pequeño y el tamaño del punto más grande:
## Crear gráfico
bubble_size <- bubble_base +
scale_size(range = c(1, 15))
## Imprimir
bubble_size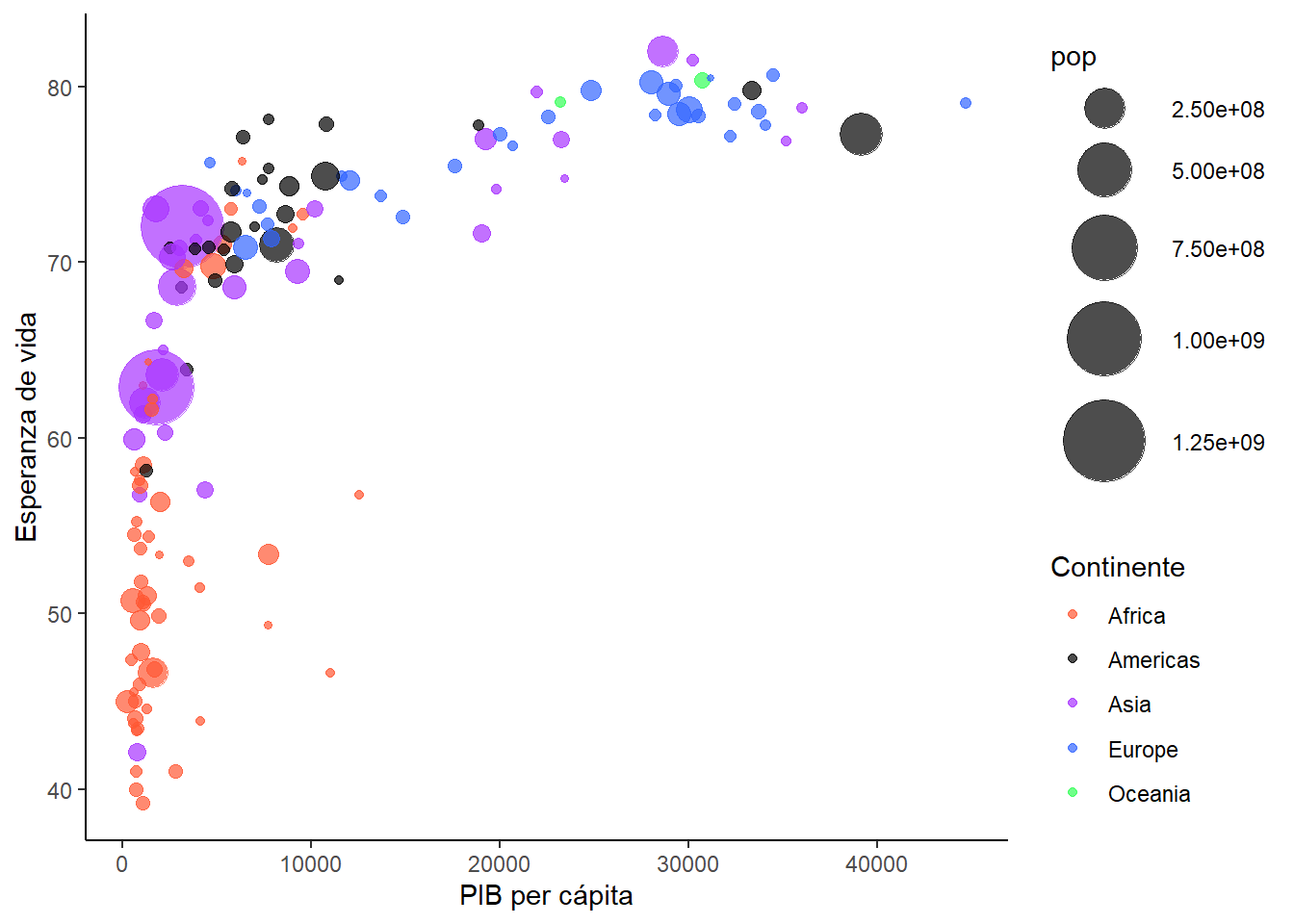
Recuerdas la función guides que vimos antes? Si igualamos una de las estéticas a "none" eliminaremos solamente esa leyenda:
## Crear gráfico
bubble_guides <- bubble_size +
guides(
size = "none"
)
## Imprimir
bubble_guides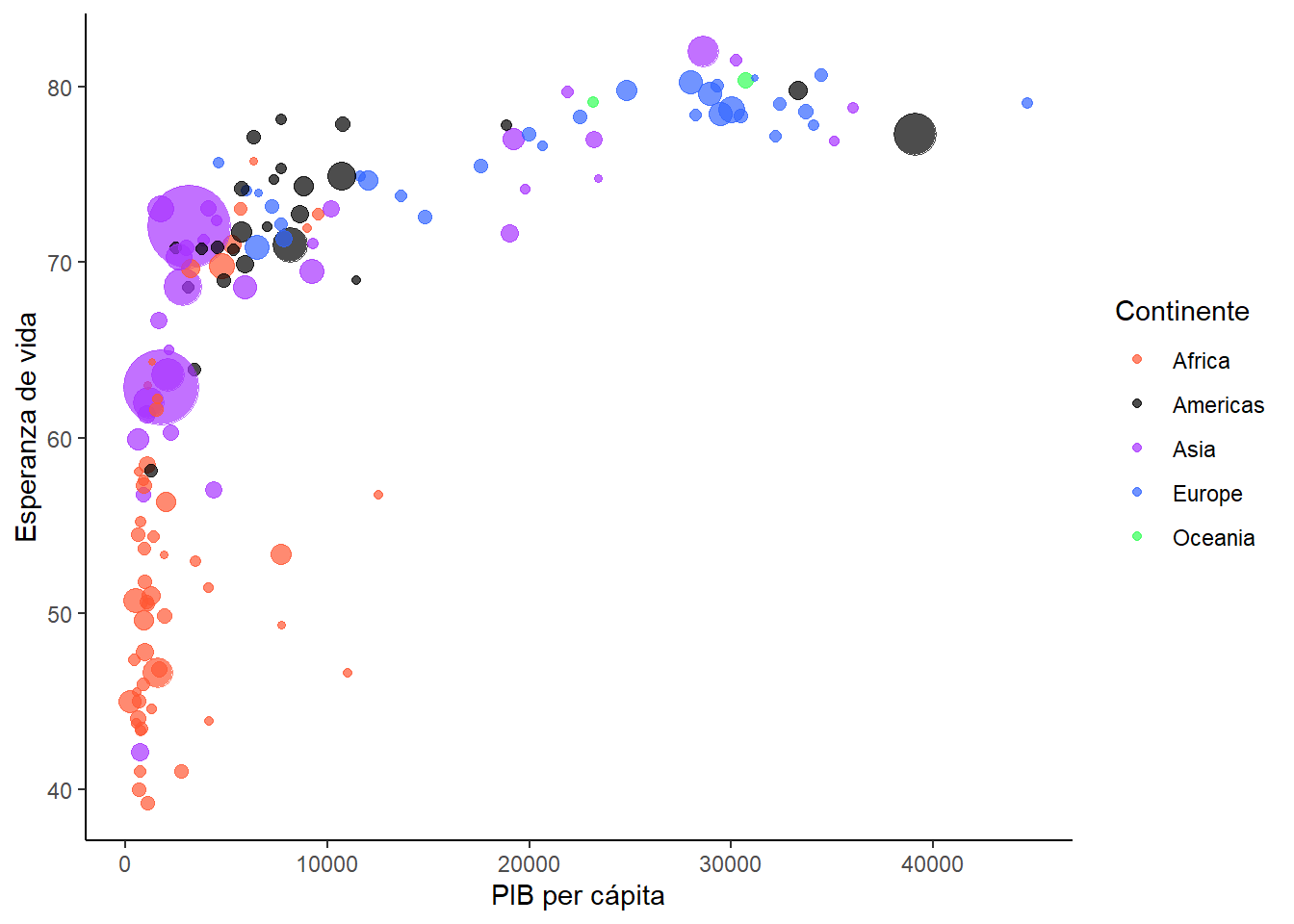
Para terminar, vamos a posicionar la leyenda del continente en la parte inferior derecha del gráfico para aprovechar el espacio:
## Crear gráfico
bubble_final <- bubble_guides +
guides(
color = guide_legend(
position = "inside"
)
) +
theme(
legend.position.inside = c(.9, .2)
)
## Imprimir
bubble_final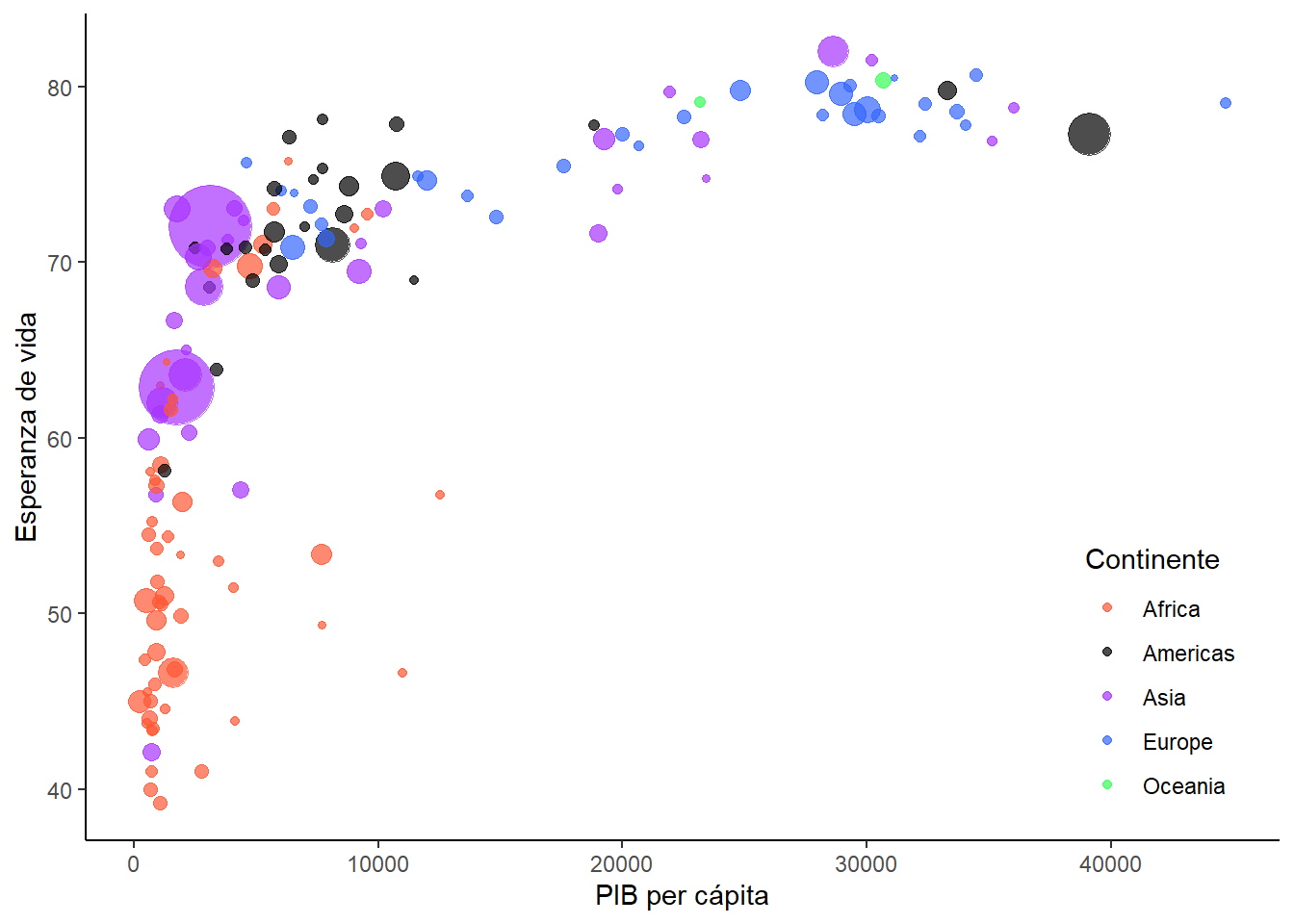
Este gráfico nos muestra que los países con menor PIB per cápita son también aquellos con generalmente menor esperanza de vida y se encuentran principalmente en África.
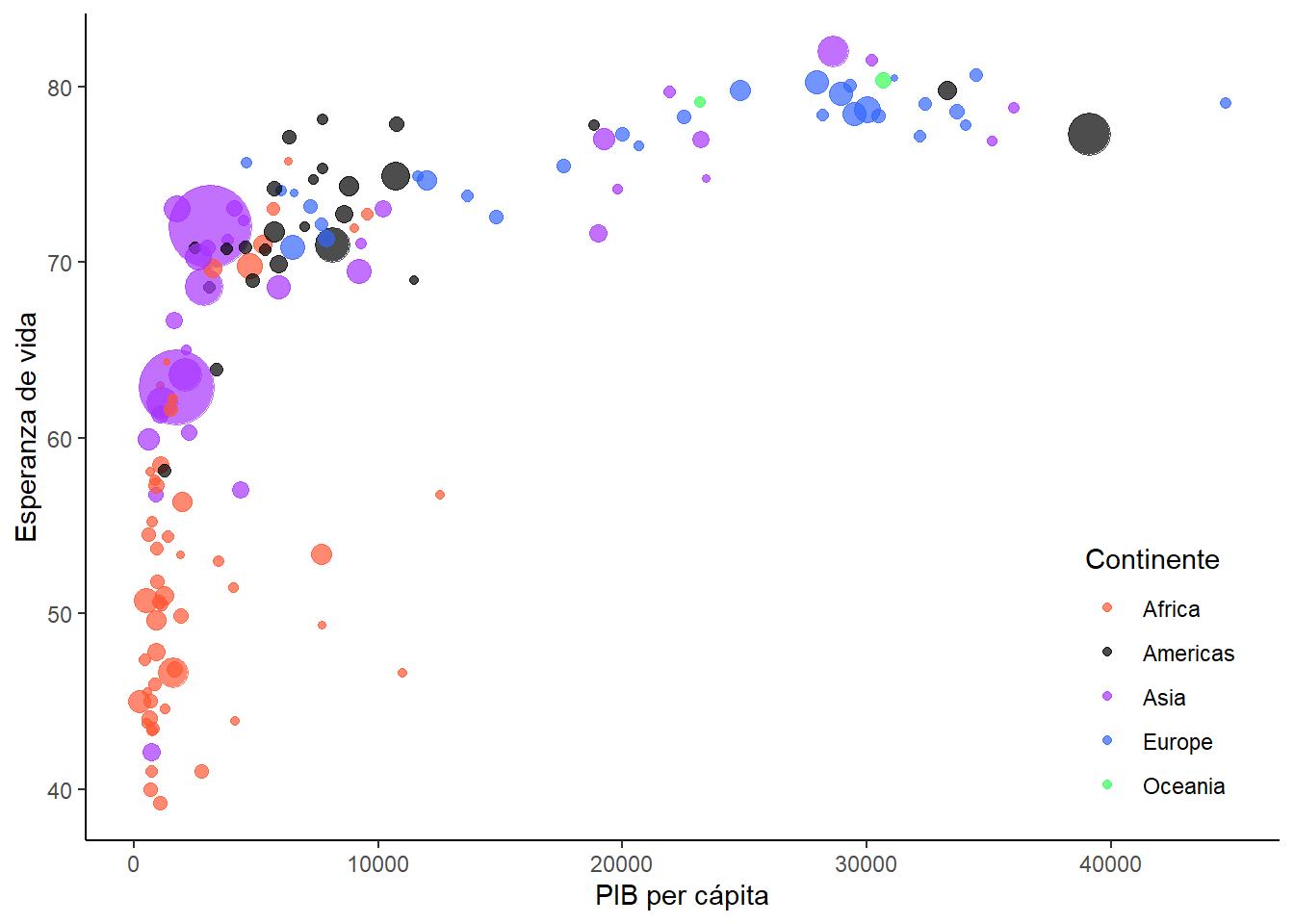
Para terminar, vamos a ver como se vería todo el código en un solo bloque:
gapminder_tbl |>
## Capas
ggplot(
aes(x = gdpPercap, y = lifeExp, color = continent, size = pop)
) +
geom_point(
alpha = 0.7
) +
## Etiquetas
labs(
x = "PIB per cápita",
y = "Esperanza de vida"
) +
## Escalas y guías
scale_color_manual(
name = "Continente",
values = c("#FF5733", "black", "#A833FF", "#3366FF", "#33FF57")
) +
scale_size(range = c(1, 15)) +
guides(
size = "none",
color = guide_legend(
position = "inside"
)
) +
## Temas
theme(
legend.position.inside = c(.9, .2)
) 
Uff 😥… Si es tu primera vez estudiando ggplot2 es posible que te esté explotando la cabeza. No te preocupes!! Es normal que al principio te cueste, pero poco a poco iremos dominándolo juntos😎.
5.3.1 Ejercicio 7
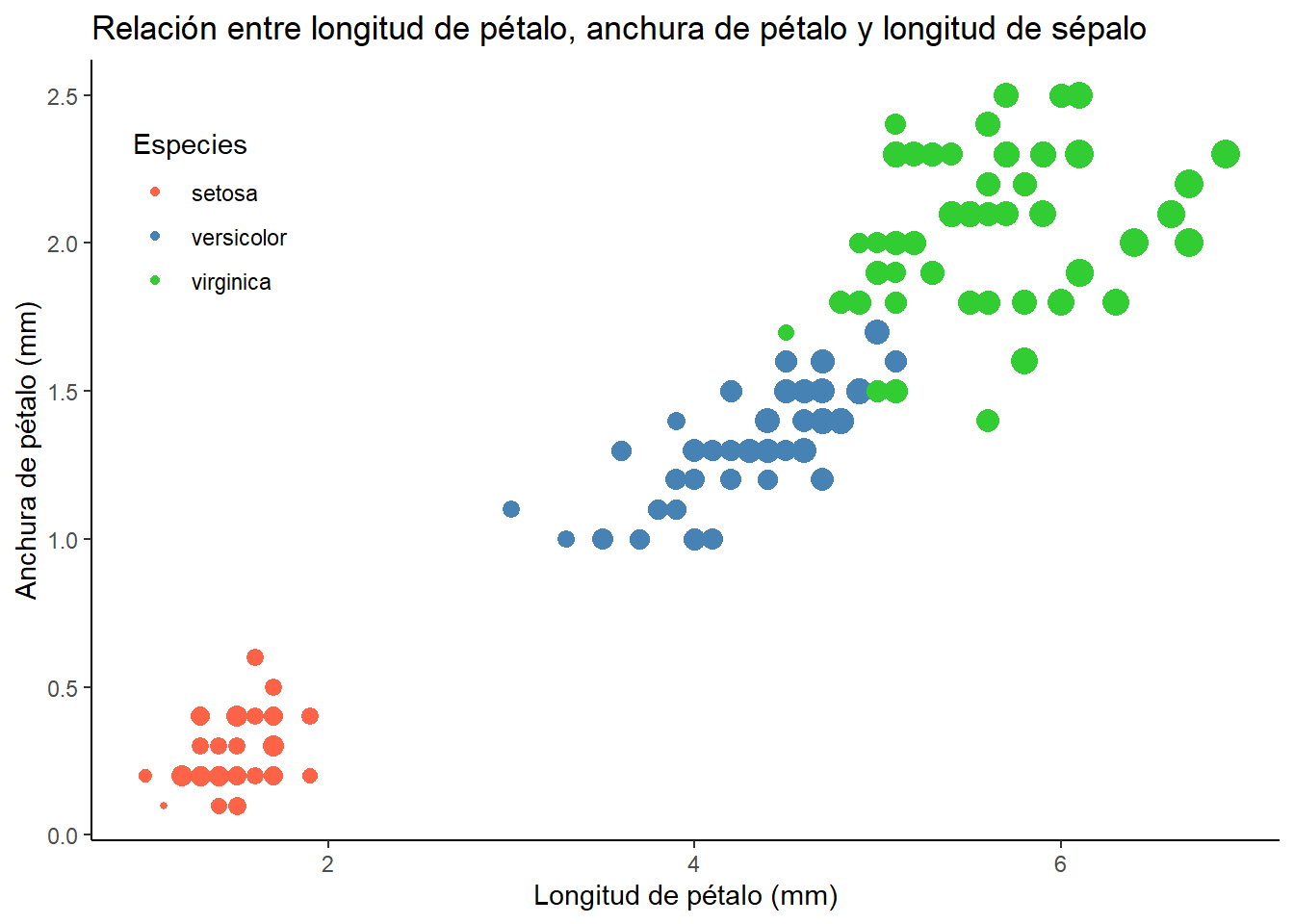
Es hora de ponerse manos a la obra! El objetivo del siguiente ejercicio es replicar el siguiente gráfico con el dataset de iris. Recuerda la estructura de los datos:
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 5.0 | 3.6 | 1.4 | 0.2 | setosa |
| 5.4 | 3.9 | 1.7 | 0.4 | setosa |
Intenta replicar este gráfico en la pestaña “Ejercicio”
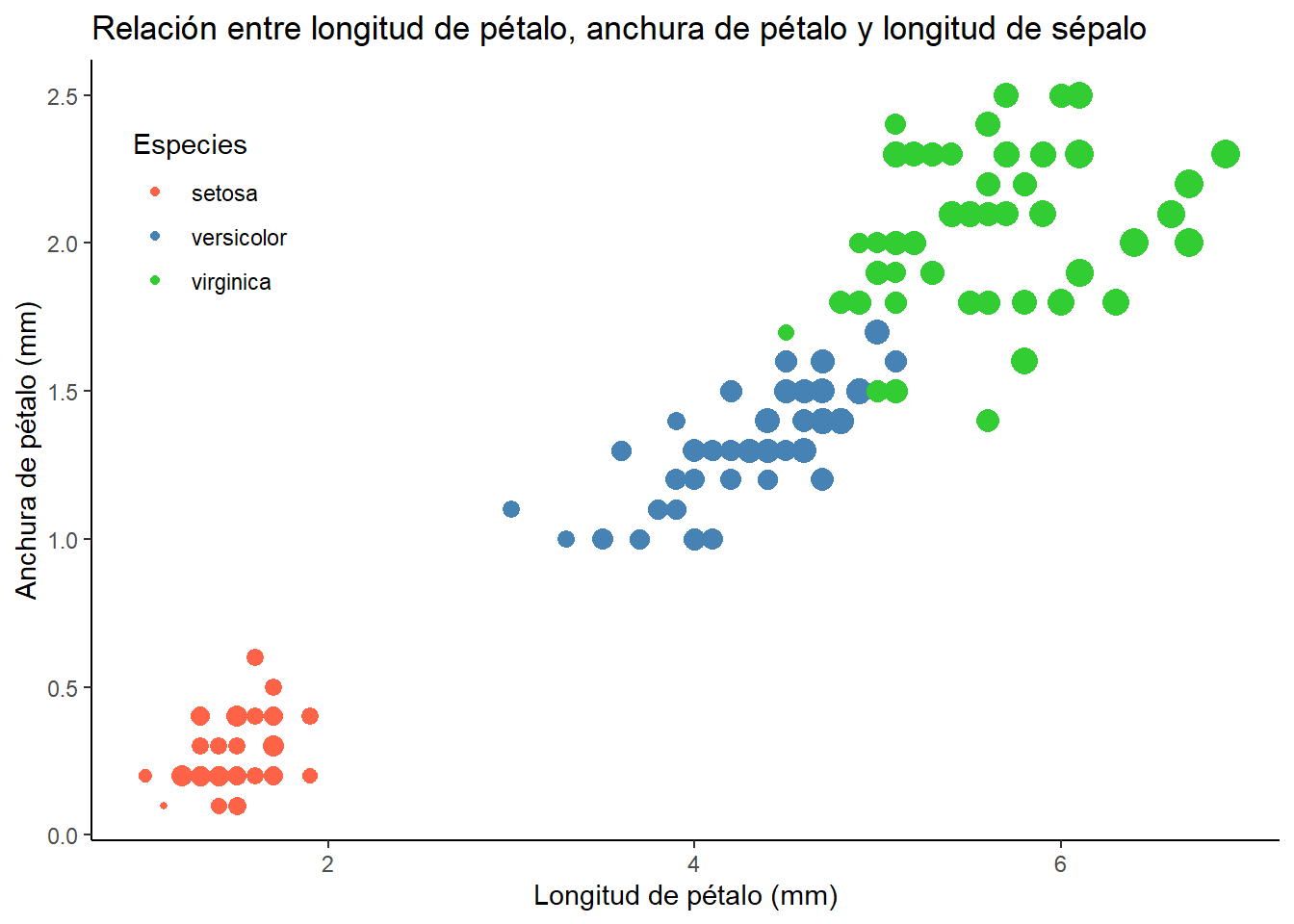
Completar el código:
iris |>
ggplot(
aes(
x = Petal.Length,
y = Petal.Width,
color = Species,
size = Sepal.Length
)
) +
geom_point() +
labs(
title = "Relación entre longitud de pétalo, anchura de pétalo y longitud de sépalo",
x = "Longitud de pétalo (mm)",
y = "Anchura de pétalo (mm)"
) +
scale_color_manual(
name = "Especies",
values = c("#FF6347", "#4682B4", "#32CD32")
) +
scale_size(range = c(1, 5)) +
guides(
size = "none",
color = guide_legend(position = "inside")
) +
theme(
legend.position.inside = c(.1, .8)
)
5.4 Mapas de calor
Dentro de los mapas de calor voy a hacer una clasificación para entender sus dos principales usos:
Mapa de calor clásico: El primero será un mapa de calor donde comparamos el valor de una variable numérica (o una categórica) en función de dos variables categóricas.
Mapa de calor de correlación: El segundo será un mapa de calor donde comparamos la correlación entre las variables numéricas de un dataset.
Esta nomenclatura es propia y no tiene por qué ser la misma que se utiliza en la literatura.
5.4.1 Mapa de calor clásico
Los mapas de calor son una forma de visualizar la relación entre las categorías de dos variables categóricas y una variable numérica (o otra categórica). Las categorías de las variables categóricas se representan en los ejes x e y, y la variable numérica se representa mediante el color de las celdas.
Existen tres funciones en ggplot2 que nos permiten crear mapas de calor: geom_tile(), geom_raster() y geom_rect().
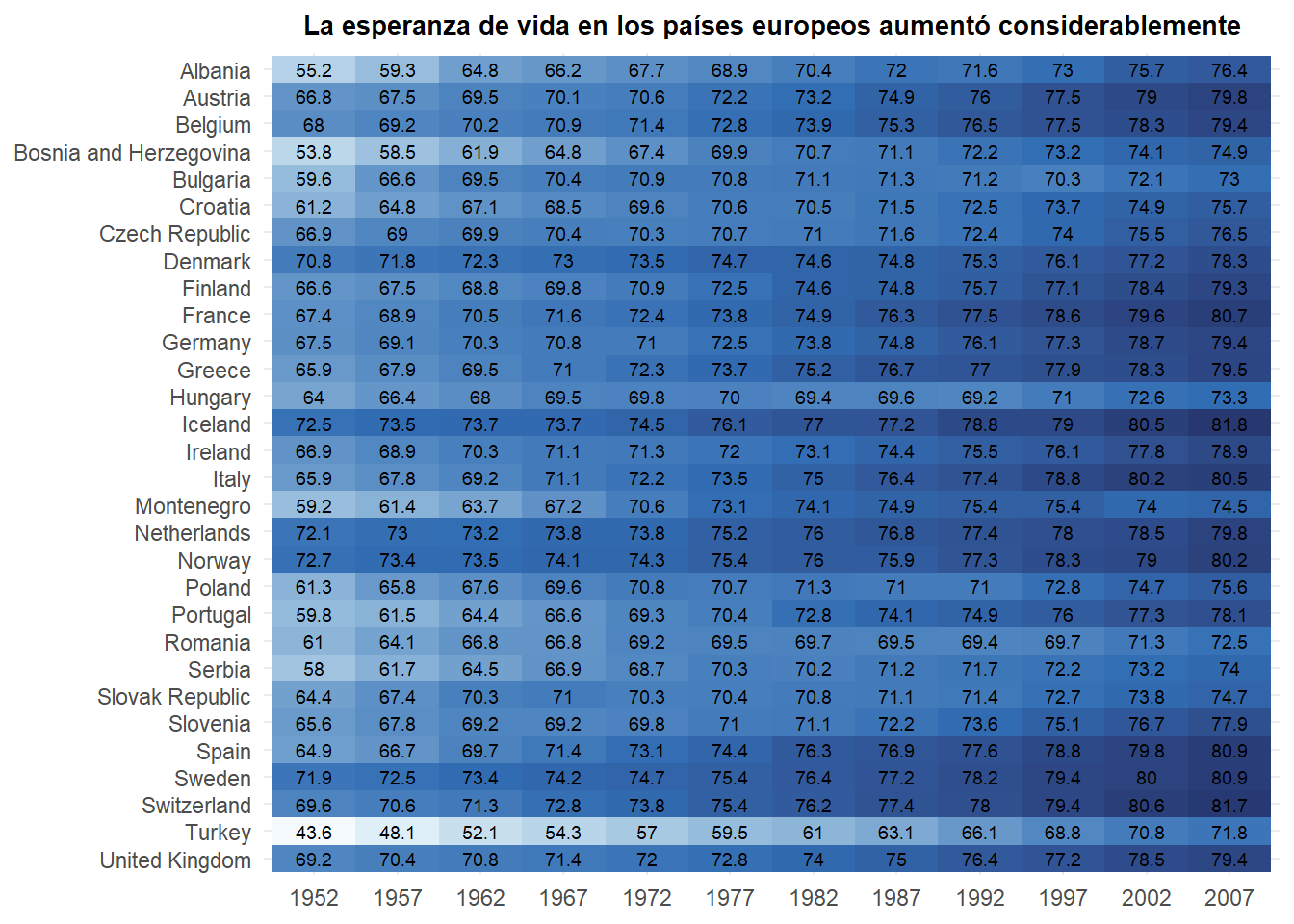
Vamos a ver la evolución de la esperanza de vida en los países de Europa a lo largo de los años. Para ello, vamos a utilizar el dataset gapminder y filtrar los datos de Europa:
Para crear el primer heatmap vamos a utilizar la función geom_tile(). En el eje x utilizamos los años, en el eje y los países europeos, y como esta geometría dibuja polígonos, los coloreamos con la estética fill:
gapminder |>
filter(continent == "Europe") |>
## Crear gráfico
ggplot(
aes(x = year, y = country, fill = lifeExp)
) +
geom_tile() +
labs(
x = NULL,
y = NULL,
fill = "Esperanza de vida"
)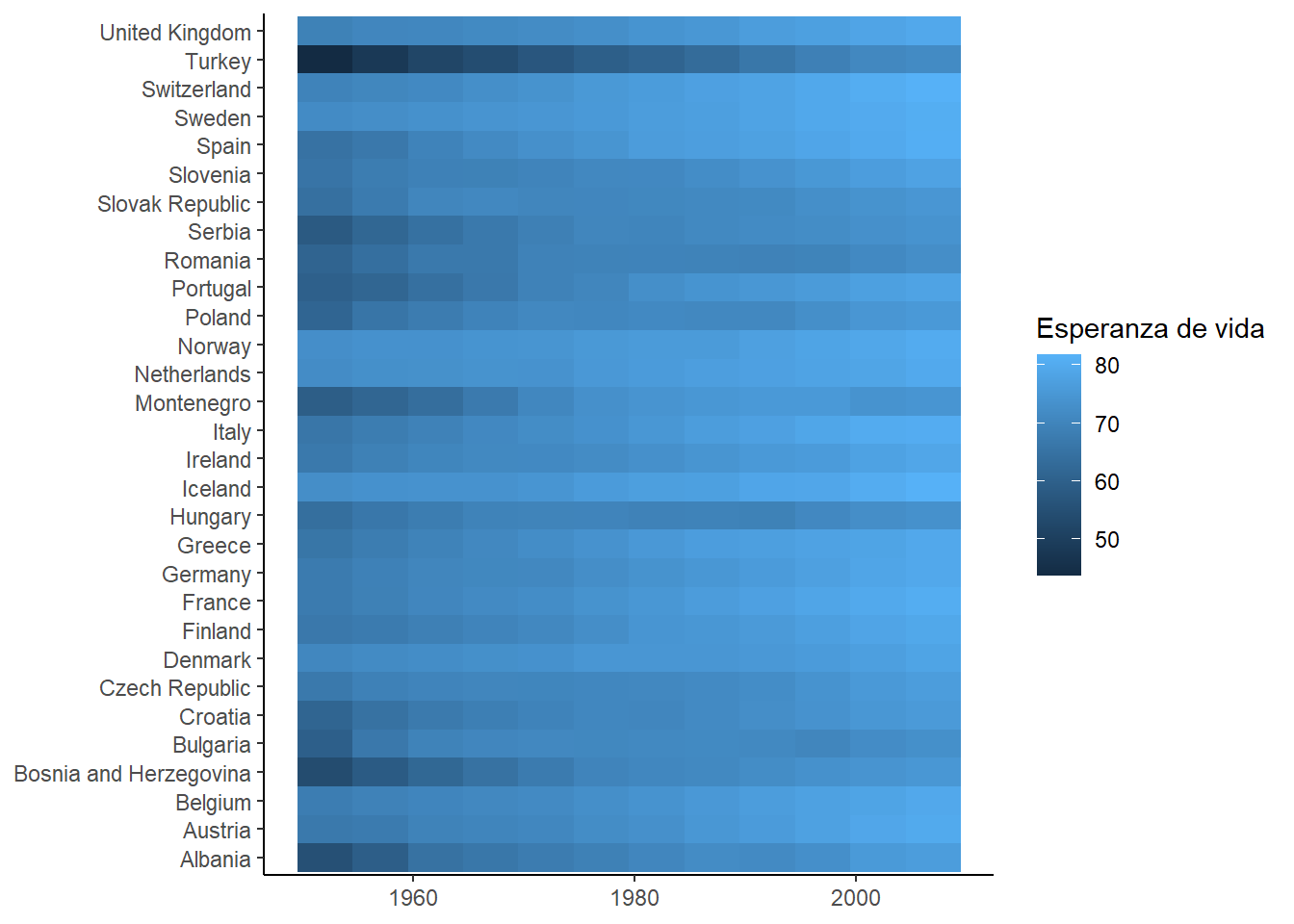
Como primer intento está bien… Pero puedes ver lo que ocurre en el eje x? Los años son números sí, pero son una variable categórica en esto datos. Tenemos un número pequeño de años que queremos tratar como categorías, no como números.
Puedes ver que para eliminar los títulos de los ejes utilizamos y = NULL y x = NULL.
Recuerdas cómo hacíamos para convertir una variable a categórica? Exacto, utilizamos la función as.factor(), que además es muy conveniente ya que ordena los niveles de la variable alfabéticamente:
gapminder |>
filter(continent == "Europe") |>
mutate(
year = as.factor(year)
) |>
## Crear gráfico
ggplot(
aes(x = year, y = country, fill = lifeExp)
) +
geom_tile() +
labs(
x = NULL,
y = NULL,
fill = "Esperanza de vida"
)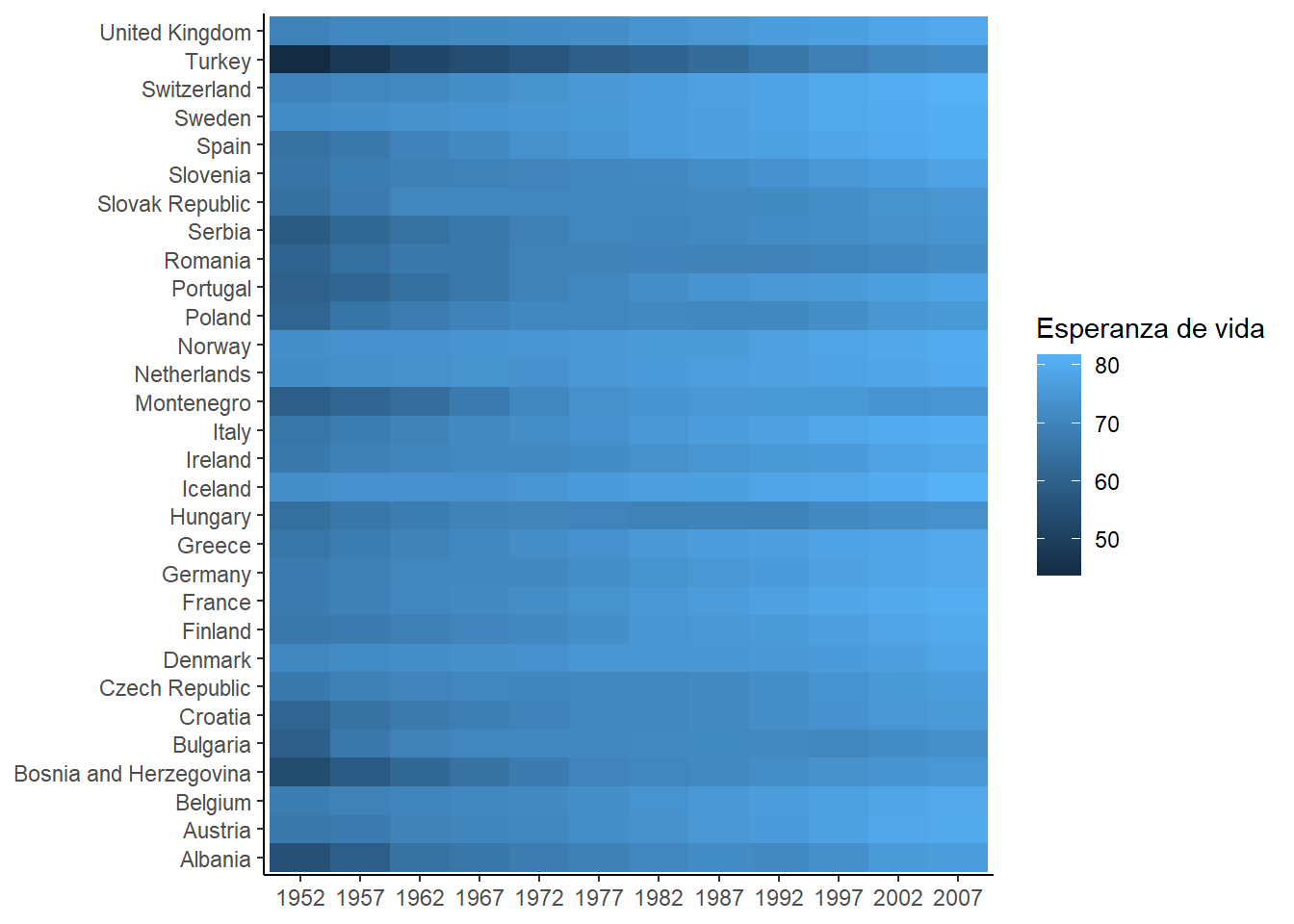
Solucionado! Ahora ya sabemos a qué año pertenece cada celda. Vamos a intentar formatear un poco más el gráfico… Vamos a utilizar una paleta de colores adecuada y ordenar los países para que Albania sea el primero en la parte superior.
En la Figura 5.7 se muestra el resultado final. Vamos a ver lo que hemos hecho:
Hemos ordenado los países utilizando la función
fct_rev()del paquete forcats. Esta función invierte el orden de los factores.Hemos utilizado la paleta de colores viridis con la función
scale_fill_viridis_c(). Utilizamosscale_fill_*, porque la estética que modificamos esfill. A continuación, añadimosscale_fill_viridis_*que es una función que tiene unas paletas de colores muy utilizadas y viene implementada en ggplot2, y finalmente añadimos lac, que quiere decir que la variable de la estéticafilles una variable continua.
gapminder |>
filter(continent == "Europe") |>
mutate(
year = as.factor(year)
) |>
ggplot(
aes(x = year, y = fct_rev(country), fill = lifeExp)
) +
geom_tile() +
labs(
x = NULL,
y = NULL,
fill = "Esperanza de vida"
) +
scale_fill_viridis_c() +
theme_minimal() 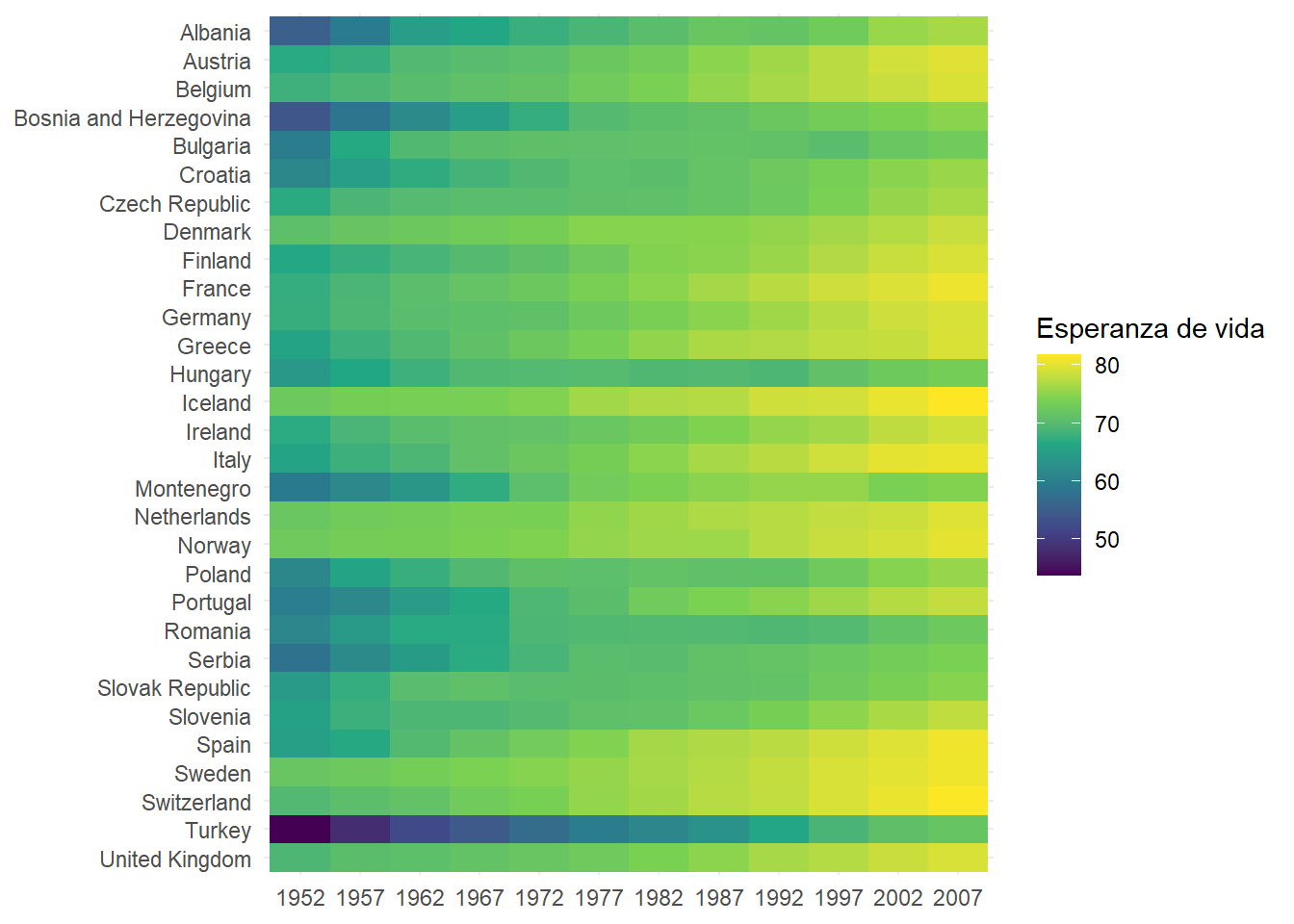
Algo común en los mapas de calor es presentarlos como tablas de colores, donde no solamente tenemos las celdas de colores, si no también el dato real que representan. Para añadirlos, vamos a añadir un nueva geometría que es geom_text(), que tiene 3 estéticas obligatorias: x, y y label. Las dos primeras serán la posición de la etiqueta, y label será el texto que se muestra:
gapminder |>
filter(continent == "Europe") |>
mutate(
year = as.factor(year),
lifeExp = round(lifeExp, 1)
) |>
ggplot(
aes(x = year, y = fct_rev(country))
) +
geom_tile(
aes(fill = lifeExp),
show.legend = FALSE
) +
geom_text(
aes(label = lifeExp),
size = 2.5
) +
labs(
x = NULL,
y = NULL,
title = "La esperanza de vida en los países europeos aumentó considerablemente"
) +
scale_fill_gradientn(
colours = hcl.colors(10, "Blues", rev = TRUE)
) +
theme_minimal() +
theme(
plot.title = element_text(
size = 10,
face = "bold",
hjust = .5
)
)
Hemos añadido scale_fill_grandientn() que es el equivalente a scale_fill_manual() para variables continuas. La función hcl.colors() simplemente nos devuelve un vector de colores:
hcl.colors(10, "Blues", rev = T) [1] "#F4FAFE" "#E1F0F8" "#C8DFEE" "#ACCCE4" "#8FB7D9" "#709FCD" "#5087C1"
[8] "#316DB3" "#305292" "#273871"Fíjate que también hemos movido aes(fill = lifeExp). Se te ocurre por qué puede ser esto? Dentro de ggplot() introducimos las estéticas que queremos que hereden el resto de geometrías, y fill solamente la queremos para geom_tile() mientras que label solamente la queremos para geom_text().
Y finalmente, modificamos el título del gráfico para reducir su tamaño base, ponerlo en negrita y justificarlo en el medio. No te preocupes si la sintaxis de la componente theme() te parece extraña, nos iremos familiarizando con ella poco a poco.
Y con esto hemos visto el primer tipo de de heatmaps. Vamos a realizar un ejercicio utilizando los datos de inventario:
5.4.2 Ejercicio 8
Utilizar de nuevo los datos de inventario para generar un heatmap donde se muestre el DBH medio por parcela y especie. Ten en cuenta que debes calcularlo. En la pestaña “Pista” tendrás la parte que genera estos datos, y que serán los datos que utilizarás en ggplot().
La estructura de los datos era la siguiente:
El resultado esperado es el de la Figura 5.9.
Para conseguir las dimensiones del gráfico tenemos que añadir la componente coord_fixed(ratio = .5). Esto hace que una unidad del eje x sea equivalente a 0.5 unidades del eje y y por lo tanto, los rectángulos tengan el doble de longitud en x
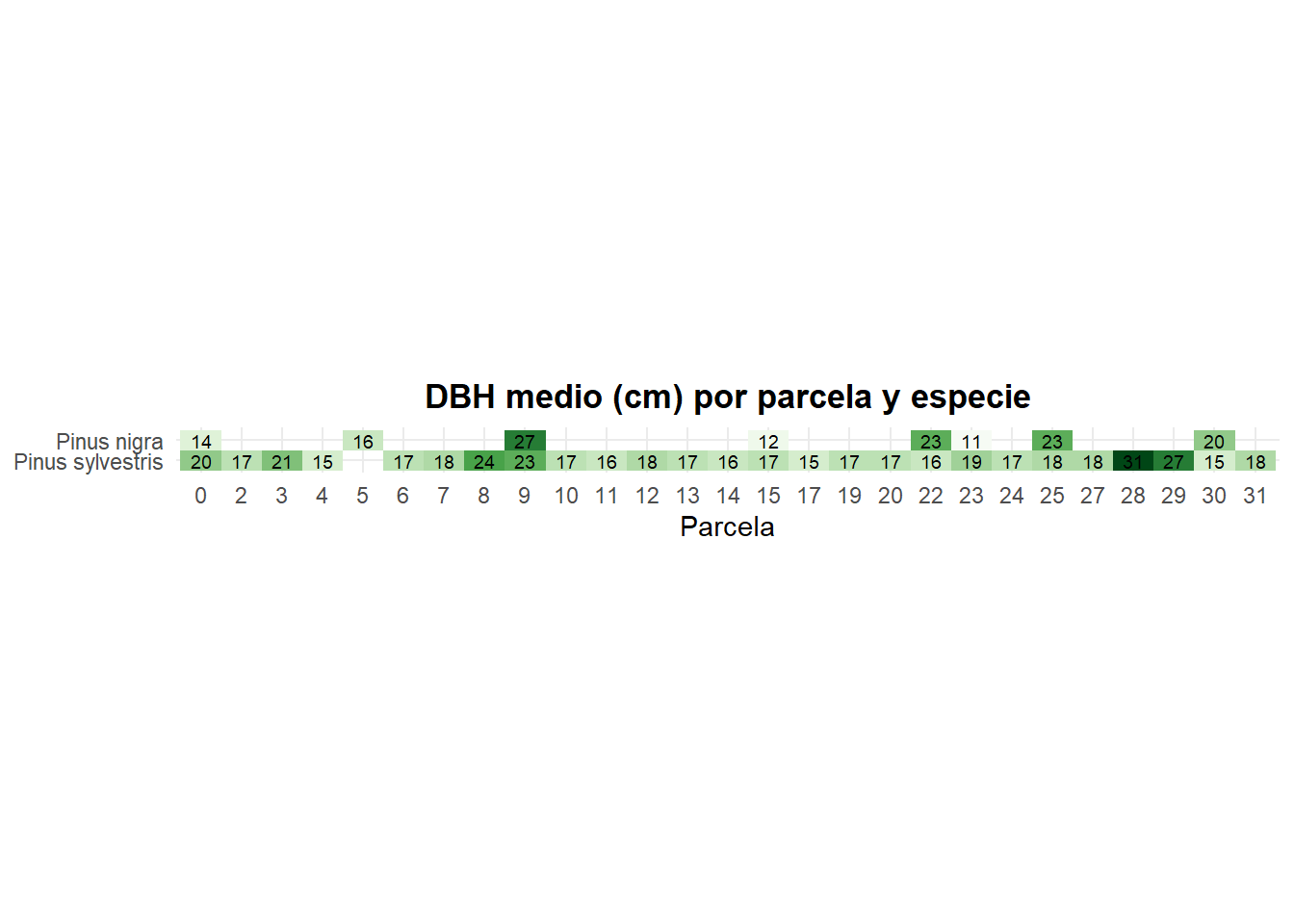
La paleta de colores utilizada es hcl.colors(10, "Greens", rev = TRUE).
El procesado de los datos es el siguiente:
inventario_tbl |>
summarise(
dbh_mean = mean(dbh_mm, na.rm = TRUE) / 10,
.by = c(id_plots, nombre_ifn)
) |>
mutate(
dbh_mean = round(dbh_mean)
)# A tibble: 34 × 3
id_plots nombre_ifn dbh_mean
<fct> <fct> <dbl>
1 0 Pinus sylvestris 20
2 0 Pinus nigra 14
3 2 Pinus sylvestris 17
4 3 Pinus sylvestris 21
5 4 Pinus sylvestris 15
6 5 Pinus nigra 16
7 6 Pinus sylvestris 17
8 7 Pinus sylvestris 18
9 8 Pinus sylvestris 24
10 9 Pinus sylvestris 23
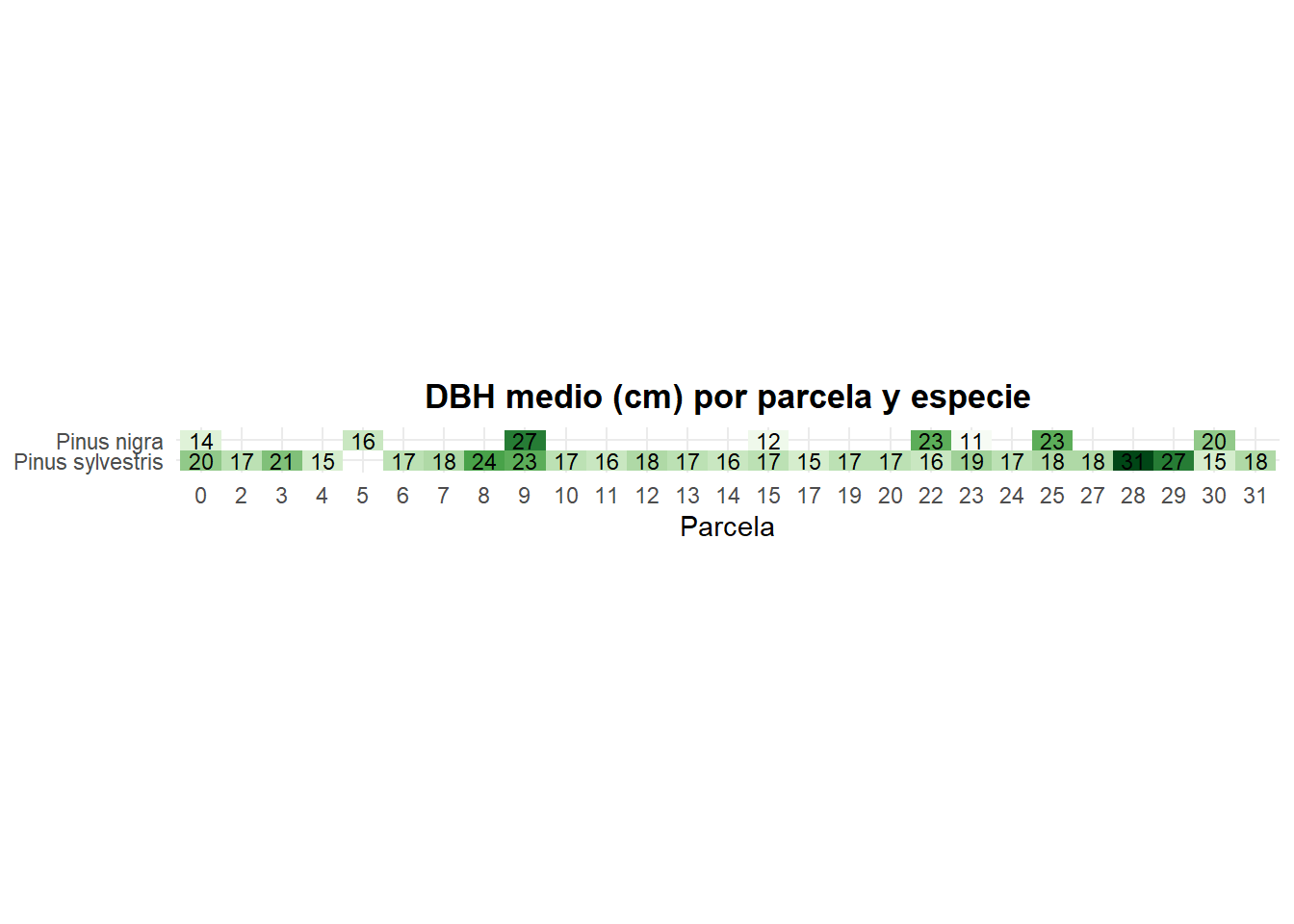
# ℹ 24 more rowsLa solución al ejercicio es:
inventario_tbl |>
summarise(
dbh_mean = mean(dbh_mm, na.rm = TRUE) / 10,
.by = c(id_plots, nombre_ifn)
) |>
mutate(
dbh_mean = round(dbh_mean)
) |>
ggplot(
aes(y = nombre_ifn, x = id_plots)
) +
geom_tile(
aes(fill = dbh_mean),
show.legend = FALSE
) +
geom_text(
aes(label = dbh_mean),
size = 3
) +
scale_fill_gradientn(
colours = hcl.colors(10, "Greens", rev = TRUE)
) +
theme_minimal() +
labs(
x = "Parcela",
y = NULL,
title = "DBH medio (cm) por parcela y especie"
) +
coord_fixed(ratio = .5) +
theme(
plot.title = element_text(hjust = .5, face = "bold")
)
Felicidades 🥳 !!! Hemos aprendido mucho hasta este punto. Aunque estés confuso por el uso de algunas funciones del tipo scale_* o coords_*, no te preocupes! Esto será cuestión de otro tema dedicado a ellas. De momento vamos introduciendo poco a poco estas componentes para que los ejercicios no sean solamente geometrías, y para que te vayas familiarizando poco a poco con la gramática. Sin más dilación, vamos a ver el siguiente tipo de heatmaps.
5.4.3 Mapa de calor de correlación
Los mapas de calor de correlación (correlacion heatmaps) son una forma de visualizar la relación entre las variables numéricas de un dataset. En estos mapas, las variables se representan en los ejes x e y, y la correlación entre ellas se representa mediante el color de las celdas.
Para entender esto, debemos definir la correlación. La correlación es una medida estadística que describe la relación entre dos variables y tiene la siguiente fórmula:
\[ r_{xy} = \frac{cov(x,y)}{SD_x \cdot SD_y} \tag{5.1}\]
\[ r_{xy} = \frac{\sum_{i=1}^{n} (x_i - \bar{x})(y_i - \bar{y})}{\sqrt{\sum_{i=1}^{n} (x_i - \bar{x})^2 \sum_{i=1}^{n} (y_i - \bar{y})^2}} \tag{5.2}\]
Técnicamente, esto es la correlación de Pearson y mide el grado de correlación lineal entre la variable x y la variable y dando como resultado un número entre -1 y 1 donde:
Valores negativos: cuando los valores de una variable aumentan, los de la otra disminuyen
Valores cercanos a 0: no existe relación lineal entre las variables
Valores positivos: cuando los valores de una variable aumentan, lo de la otra también
En la siguiente figura se muestran varios ejemplos:
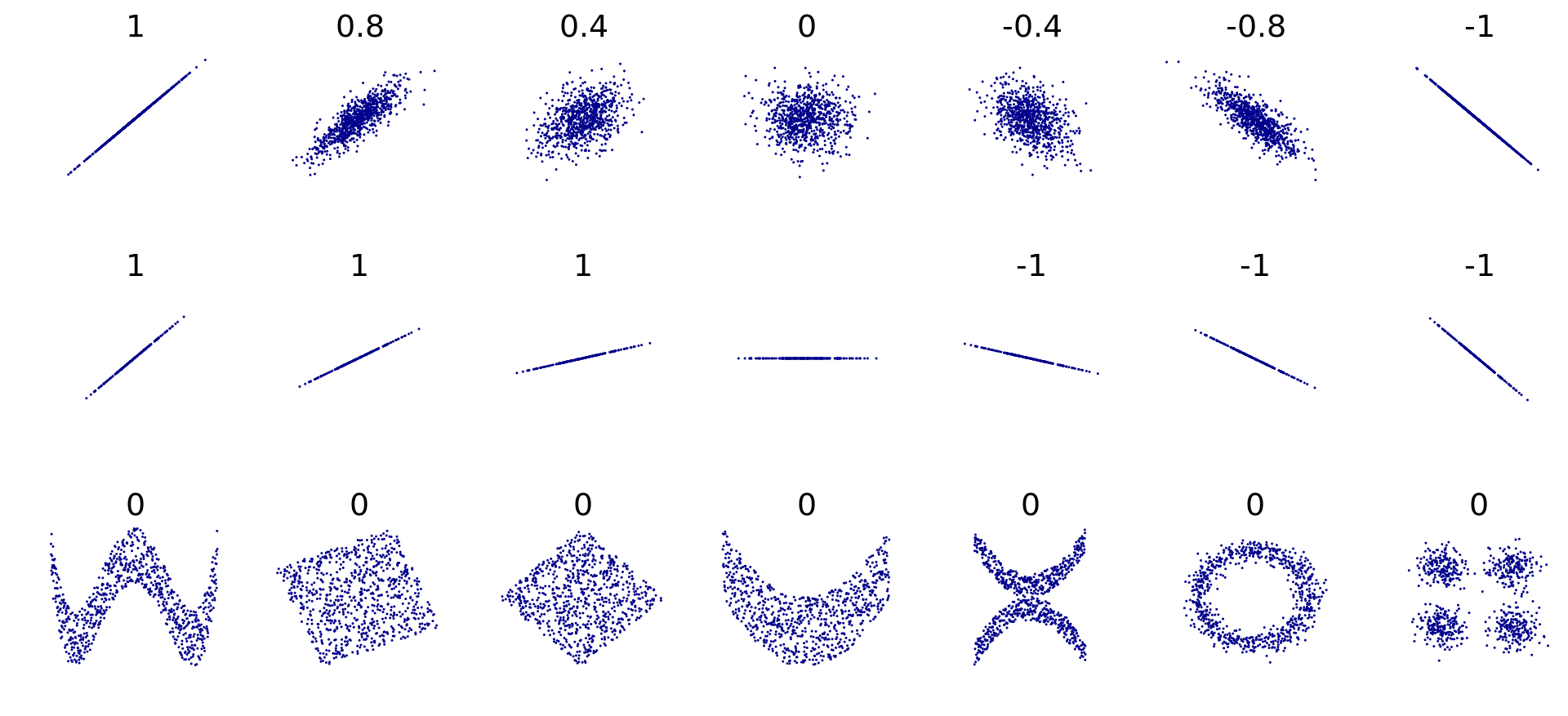
En este sentido, vamos a generar el correlation heatmap para los datos de iris:
La correlación se calcula solamente para variables numéricas, así que para seleccionar solamente estas, y calcular la correlación con la función cor():
## Calcular correlación
iris_cor <- iris |>
select(
where(is.numeric)
) |>
cor()
## Imprimir
iris_cor Sepal.Length Sepal.Width Petal.Length Petal.Width
Sepal.Length 1.0000000 -0.1175698 0.8717538 0.8179411
Sepal.Width -0.1175698 1.0000000 -0.4284401 -0.3661259
Petal.Length 0.8717538 -0.4284401 1.0000000 0.9628654
Petal.Width 0.8179411 -0.3661259 0.9628654 1.0000000La diagonal será siempre 1, ya que la correlación de una variable consigo misma siempre será una recta.
Existen muchos paquetes que traen funciones internas que a partir de la matriz de correlación crean un correlation heatmap. Uno de mis favoritos es GGally.
De hecho, gracias a este paquete, no tenemos que realizar el paso anterior, y simplemente añadiendo nuestro datos a la función ggcor(), hará el trabajo por nosotros:
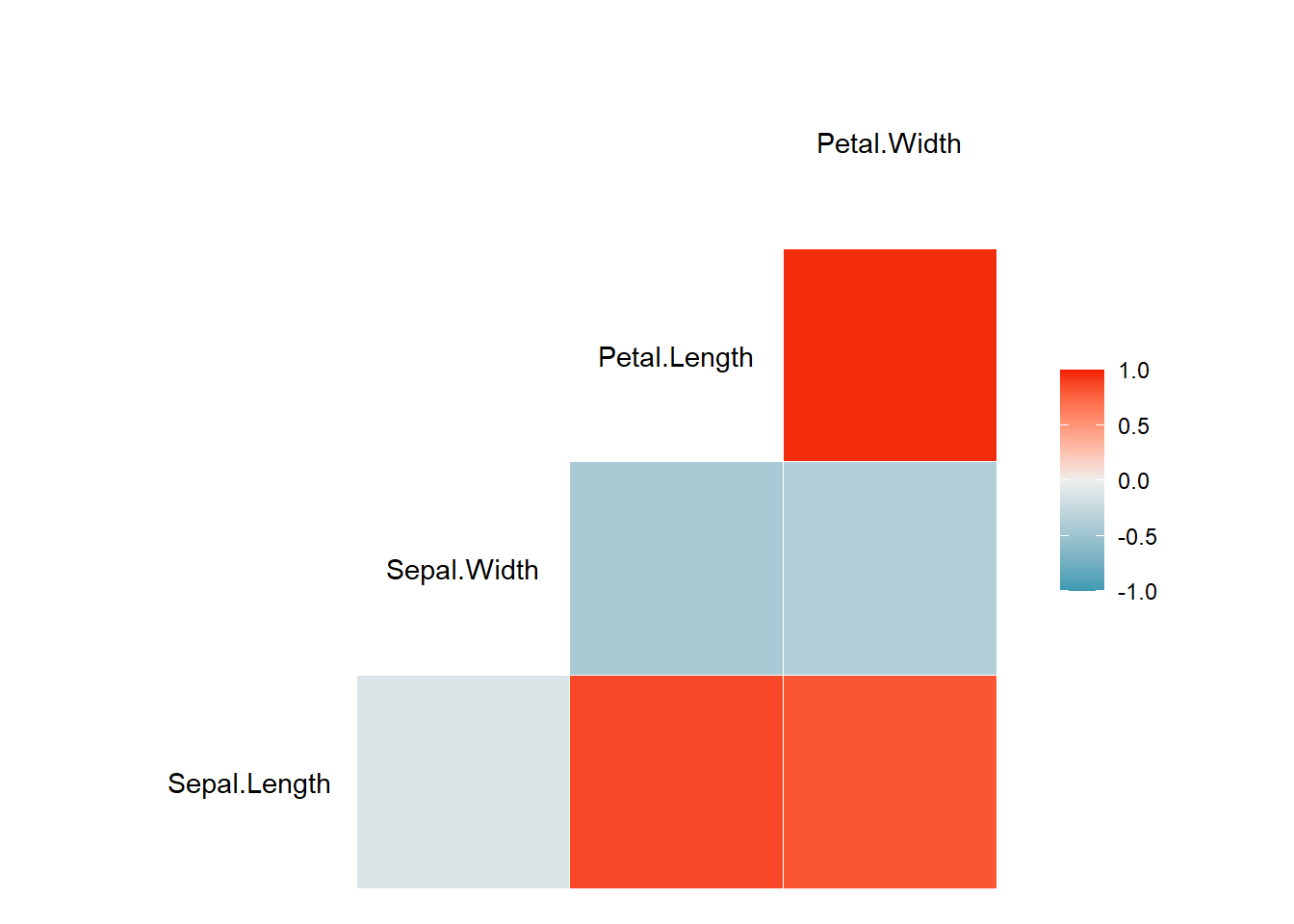
Esta función tiene parámetros que podemos modificar. Además, como es un objeto de ggplot2, podemos modificarlo como tal:
ggcorr(
iris,
label = TRUE,
label_round = 2
) +
labs(
title = "Correlación de Pearson del dataset de {iris}"
) +
theme(
plot.title = element_text(
hjust = .5,
face = "bold"
)
)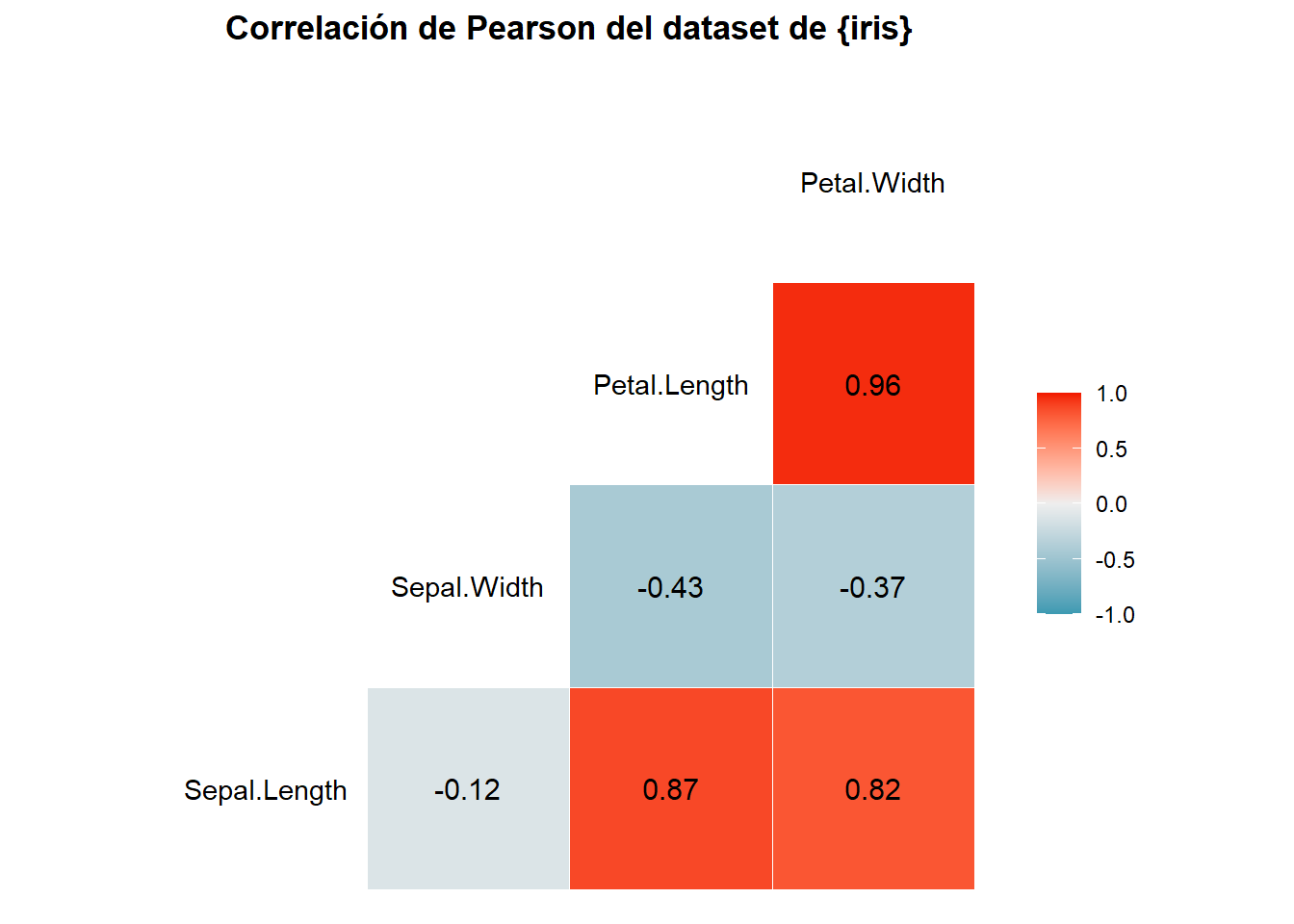
Compara los valores de las etiquetas con los que obtuvimos al utilizar la función cor().
Finalmente, tenemos la opción de añadir una variable categórica como puede ser la especie de Iris, y ver la correlación de cada variable por especie. Dentro de GGally tenemos la siguiente función:
ggpairs(
data = iris,
aes(color = Species)
) +
theme_minimal(base_size = 8)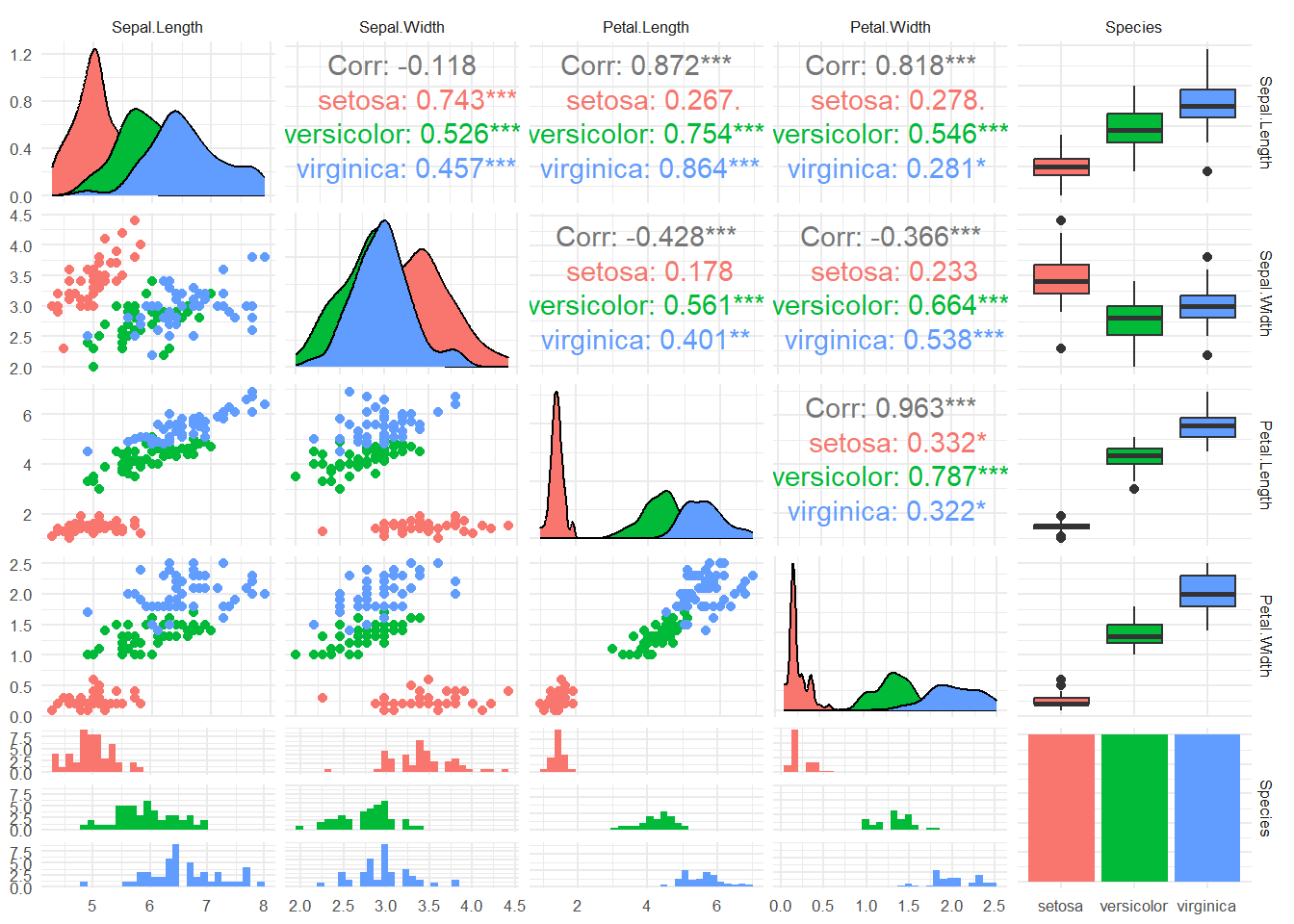
Madre mía, pero esto qué es 🥵🤯 !! Pues aquí tenemos varias cosas:
Colores: cada color representa una especie (rojo = setosa; verde = versicolor; azul = virginica)
Triángulo inferior: relación de las variables mediante scatter plots para pares de variables numéricas e histogramas para 1 variable numérica y 1 variable categórica.
Diagonal: distribución unitaria de cada variable. Gráficos de densidad para numéricas, gráficos de barras para variables categóricas.
Triángulo superior: valores de correlación para pares de variables numéricas. Boxplots para 1 variable numérica y 1 variable categórica.
Como puedes ver, en básicamente una línea de código esta función nos da una información MUY valiosa sobre nuestros datos. Esta función la utilizo mucho durante el análisis exploratorio de mis datos.
5.4.4 Ejercicio 9
Crear un gráfico de correlación con GGally para los datos de inventario.
La estructura de los datos era la siguiente:
El resultado esperado es el de la Figura 5.15. Fíjate que no incluimos la variable id_plots en el gráfico.
Los colores utilizados son cols <- c("#E56399", "#7F96FF").
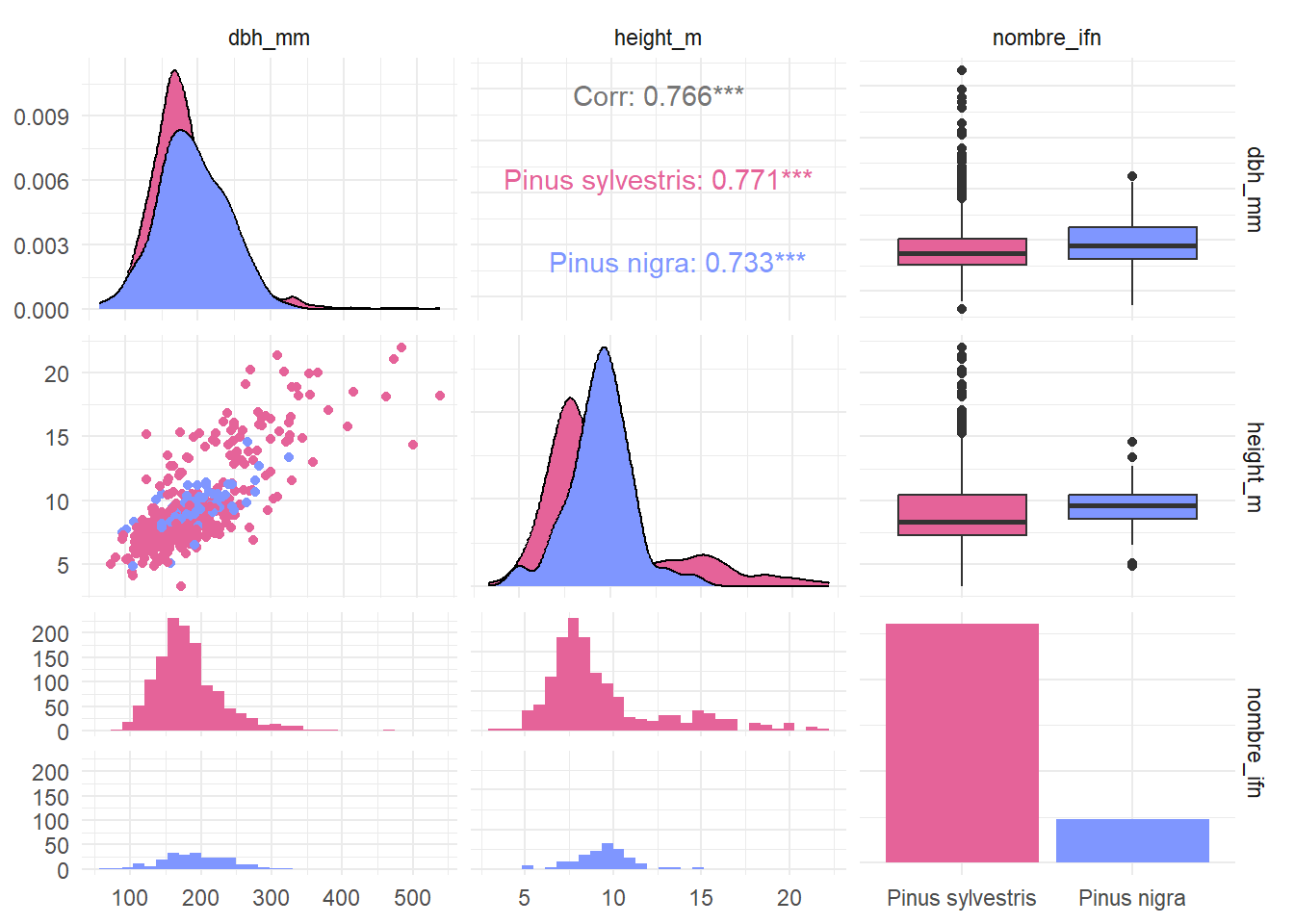
Replica el gráfico anterior e intenta entender qué ocurre en cada subgráfico.
El resultado se muestra en la Figura 5.16. Fíjate que tenemos que añadir tanto scale_color_manual() para cambiar los colores de los puntos y scale_fill_manual() para cambiar los de los rectángulos.
## Colores
cols <- c("#E56399", "#7F96FF")
## Gráfico
inventario_tbl |>
select(-id_plots) |>
ggpairs(
aes(color = nombre_ifn)
) +
scale_color_manual(
values = cols
) +
scale_fill_manual(
values = cols
) +
theme_minimal()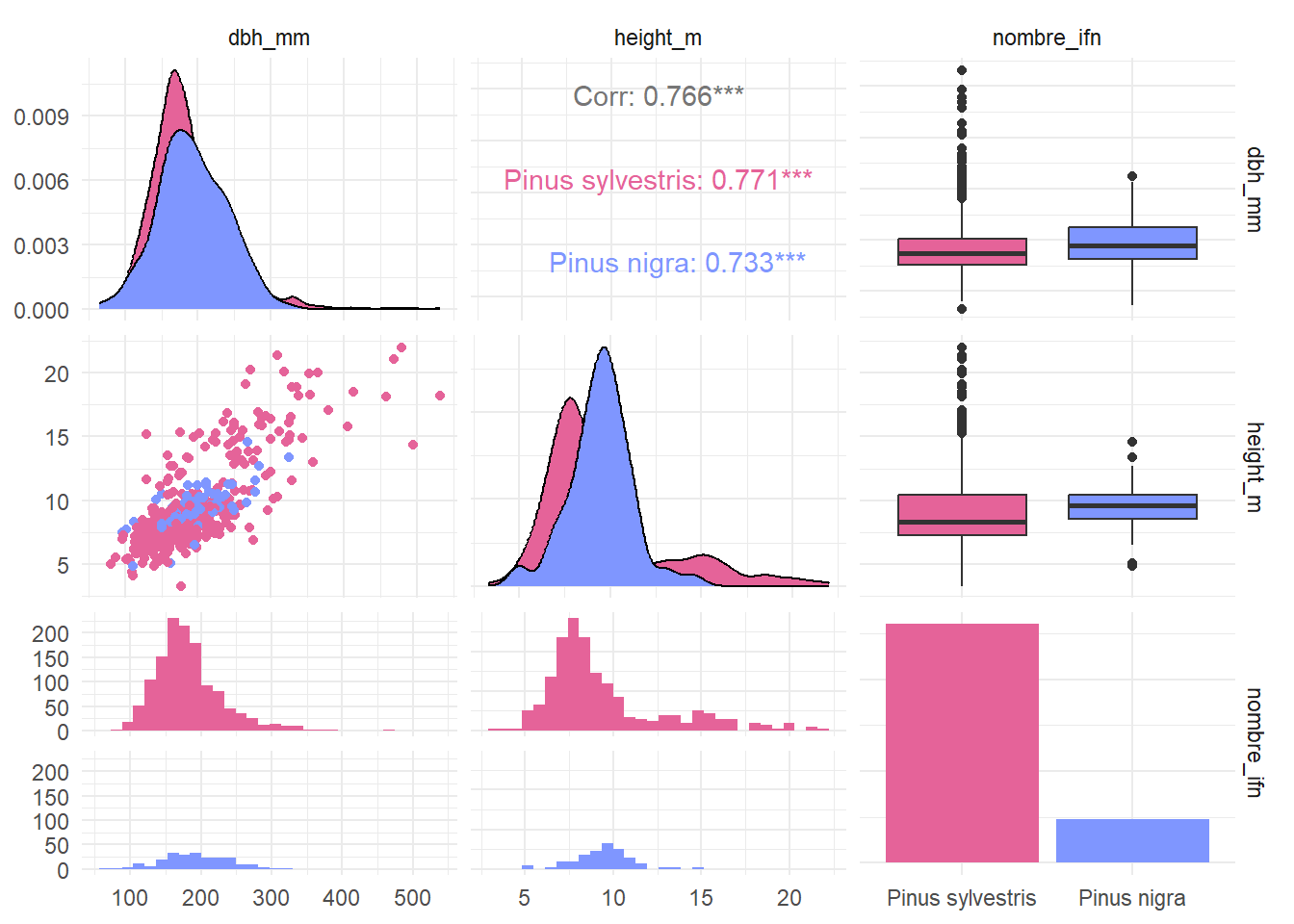
Enhorabuena! Has llegado al final de este capítulo. Sé que ha sido intenso, pero estamos aprendiendo mucho. En el próximo capítulo vamos a ver algunos gráficos de comparación.
5.5 Resumen
En este capítulo hemos aprendido a crear gráficos de dispersión y mapas de calor con ggplot2. Hemos aprendido a modificar las escalas de los ejes, a cambiar los colores de los puntos y a mover las leyendas. Además, hemos aprendido a crear mapas de calor de correlación y a personalizarlos.