2 Primeros pasos con ggplot2
ggplot2 es un paquete de R que permite crear gráficos de forma sencilla y flexible. A diferencia de muchos paquetes de R u otros software, ggplot2 se basa en una gramática de gráficos (Wilkinson 2005) que permite crear gráficos siguiendo una serie de reglas basadas en la construcción de gráficos a partir de capas y otros componentes.
2.1 Objetivos
Entender la gramática de gráficos y su implicación dentro de ggplot2
Estudiar los componentes que formar un gráfico en ggplot2
Crear gráficos sencillos
Entender como funciona la herencia de datos y estéticas
Estudiar la diferencia entre mapear y asignar una estética
En esta sección, trabajaremos con los siguientes paquetes:
2.2 Datos de trabajo
Antes de comenzar a trabajar con ggplot2, vamos a explorar los datos con los que vamos a trabajar. En este caso, vamos a utilizar un conjunto de datos de ejemplo que contiene información sobre una serie de árboles. Para cargar los datos, utilizaremos la función read_rds() del paquete readr:
inventario_tbl <- read_rds("../data/inventario_prep.rds")Una vez que hemos cargado los datos, vamos a utilizar la función skim del paquete skimr para obtener un resumen de los datos:
skim(inventario_tbl)| Name | inventario_tbl |
| Number of rows | 1540 |
| Number of columns | 4 |
| _______________________ | |
| Column type frequency: | |
| factor | 2 |
| numeric | 2 |
| ________________________ | |
| Group variables | None |
Variable type: factor
| skim_variable | n_missing | complete_rate | ordered | n_unique | top_counts |
|---|---|---|---|---|---|
| id_plots | 0 | 1 | FALSE | 27 | 17: 111, 11: 91, 5: 89, 14: 79 |
| nombre_ifn | 0 | 1 | FALSE | 2 | Pin: 1302, Pin: 238 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| dbh_mm | 12 | 0.99 | 184.85 | 50.97 | 65.0 | 153.75 | 177.00 | 207.00 | 531.00 | ▃▇▁▁▁ |
| height_m | 1120 | 0.27 | 9.49 | 3.27 | 3.3 | 7.39 | 8.57 | 10.47 | 21.99 | ▂▇▂▁▁ |
Esta función nos proporciona información sobre las variables del conjunto de datos, incluyendo el tipo de variable, el número de observaciones, el número de valores faltantes (NA), la media, la desviación estándar, los valores mínimos y máximos, y los cuartiles.
Tenemos 2 variables numéricas que son el diámetro y la altura de los árboles, y 2 variables categóricas que son la especie (Pinus nigra o Pinus sylvestris) y un identificador de la parcela de inventario (27 parcelas distintas). Para el diámetro, tenemos un total de 12 valores ausentes (NA) que son aproximadamente un 1% de los datos. Para la altura, tenemos 1120 valores ausentes, que son aproximadamente un 73% de los datos. En este sentido, es importante tener en cuenta que los valores ausentes pueden afectar a los análisis y visualizaciones que realicemos con los datos.
Aunque estos datos tengan una estructura muy sencilla, nos servirán a la perfección para los objetivos de este curso. Nuestro objetivo será entender la gramática de gráficos como una base fundamental que nos permitirá transmitir el mensaje que deseemos con nuestros datos.
2.3 Gramática de gráficos
La gramática de gráficos es un conjunto de reglas que definen cómo se pueden construir gráficos a partir de componentes básicos, y fue creada por Wilkinson (2005). La idea de crear una gramática de gráficos es que, al igual que en la gramática de un idioma, se pueden combinar diferentes elementos para crear gráficos complejos. Cuando aprendemos a hablar un idioma, aprendemos las reglas gramaticales y el vocabulario, y con estos elementos podemos crear frases y textos. De la misma forma, al aprender la gramática de gráficos, podemos crear gráficos complejos a partir de componentes básicos.
Posteriormente se creó ggplot2 (Wickham 2010), que utiliza las reglas gramaticales de la gramática de gráficos para crear gráficos en R. ggplot2 se basa en la idea de que un gráfico se puede construir a partir de capas, y cada capa se puede añadir al gráfico para añadir información adicional.
2.4 Componentes
La gramática de gráficos tiene una serie de componentes diferenciados Figura 2.1 que se definen en Wickham (2010). Estos componentes son:
Datos (data): conjunto de datos que utilizamos para generar el gráfico.
Geometrías (geom): se refiere a la forma de representación de nuestros datos. Algunos ejemplos de geometrías son: puntos, líneas, histograma, diagramas de caja, etc.
Estéticas (aes): también denominados aesthetic mappings. Se refiere a los elementos que definen la estética de las geometrías. Si ponemos el ejemplo de un gráfico de puntos (scatter plot), las estéticas pueden ser: su forma (punto, rectángulo, triángulo…), su tamaño, color, transparencia …
Transformaciones estadísticas (stat):se refiere al estadístico utilizado para resumir nuestros datos. Por ejemplo, para crear un histograma resumimos nuestros datos en intervalos (bins) y contamos el número de observaciones que existen dentro de este intervalo. Este componente es más avanzado que el resto, por lo que trabajaremos solamente con los valores que vienen por defecto.
Escalas (scale): transforman los valores de los datos en estéticas. Nos permiten controlar los colores, tamaños, formas, etc. También nos permiten controlar aspectos de las leyendas y ejes.
Existe una escala por cada estética utilizada.
Facetas (facets): consiste en generar subgráficos según un atributo. Por ejemplo, utilizando nuestros datos de inventario, podemos generar un gráfico de puntos donde representemos la relación diámetro-altura para todos los datos, o bien podemos generar facetas que generen un gráfico por cada una de las especies (es decir, un scatter plot para P. nigra y otro distinto para P. sylvestris).
Coordenadas (coord): sistema de coordenadas utilizado para mapear los datos. Por defecto y normalmente, utilizaremos el sistema de coordenadas cartesiano. Otros sistemas disponibles son el sistema de coordenadas polares (que nos permiten crear los increíbles gráficos circulares), o también sistemas de referencia de coordenadas para generar mapas (sí, con ggplot2 podemos generar mapas🗺️).
Tema (theme): nos permite controlar todos los aspectos relacionados con la apariencia del gráfico, como puede ser la fuente de texto, tamaño de fuente, posición de elementos como la leyenda, colores de relleno, etc.
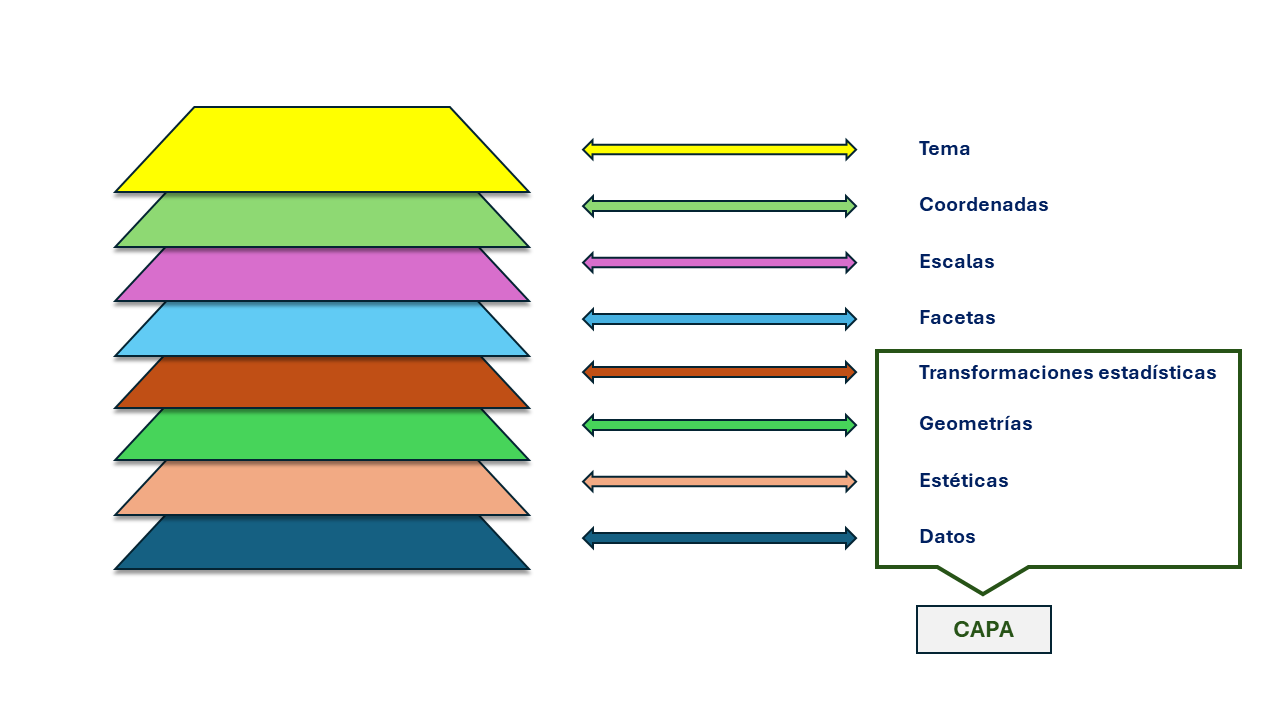
Finalmente, podemos definir una capa como la combinación de datos, estéticas, geometrías y transformaciones estadísticas (Wickham, Navarro, y Pedersen 2021), y en la mayoría de las ocasiones, estos cuatro componentes se especificarán dentro de una función que comienza por geom_*, aunque los datos y las estéticas también se pueden especificar dentro de la función ggplot(). No os preocupéis, pronto veremos las diferencias entre estas opciones.
Un mismo gráfico puede contener más de una capa y estas capas pueden (o no) compartir los mismo datos:
Capa 1: utiliza los datos de inventario, como estéticas utiliza las variables
DBH_mmyheight_m, la geometría de punto y como transformación estadística utiliza identity. Esta transformación es utilizada por muchas geometrías y significa que va a utilizar los valores tal cual aparecen en la tabla de datos, sin realizar ninguna transformación. En términos matemáticos significa que \(f(x)= x\).Capa 2: utiliza los datos de inventario, como estéticas utiliza las variables
DBH_mmyheight_m, la geometría de línea y como transformación estadística utiliza smooth. Esta transformación utiliza un método de suavizado (por defecto una Regresión Local (LOESS)) donde se genera una línea que aproxima la tendencia de los datos.
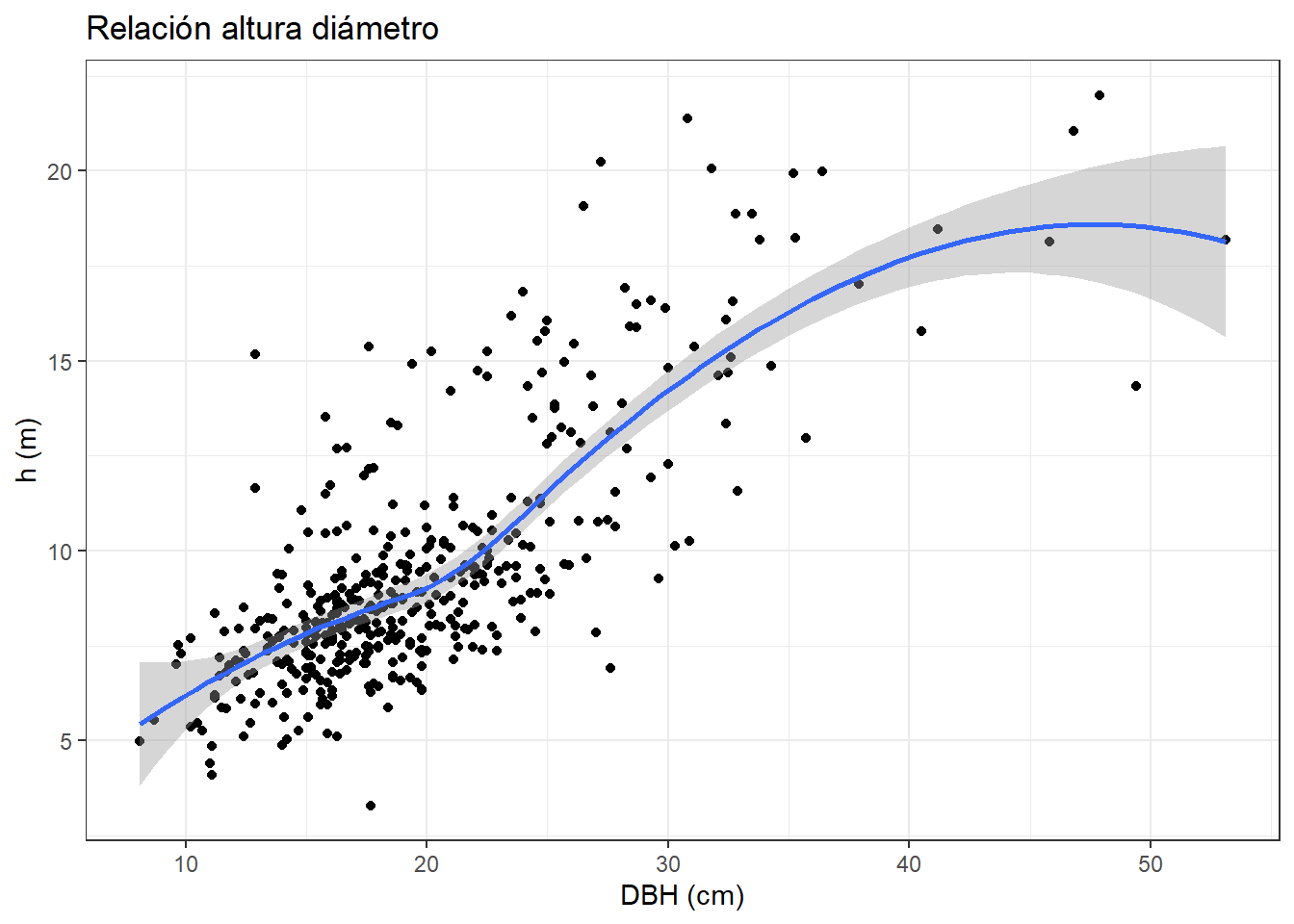
El tipo de gráfico viene definido por dos elementos: el tipo de geometría y la transformación estadística. Por poner un ejemplo relacionado con el anterior:
Gráfico de líneas: se define por una geometría de línea y una transformación estadística identity (
geom_line(stat = "identity")).Gráfico suavizado: utiliza la geometría de línea y una transformación estadística smooth (
geom_line(stat = "smooth")).
No obstante, los gráficos comunes como el gráfico suavizado vienen incluidos en ggplot2 a través de una función que utiliza la transformación estadística adecuada por defecto, y solamente nos hará falta llamar a la función adecuada sin utilizar el argumento stat:
| Función | T.E. por defecto |
|---|---|
| geom_line() | identity |
| geom_smooth() | smooth |
2.5 Ejemplo rápido
Para digerir los conceptos anteriores, vamos a ver un ejemplo rápido. Para este ejemplo, vamos a eliminar los valores ausentes, ya que el objetivo es solamente entender los conceptos anteriores y no generar un gráfico para publicar.
# A tibble: 418 × 4
id_plots dbh_mm height_m nombre_ifn
<fct> <int> <dbl> <fct>
1 0 296 9.26 Pinus sylvestris
2 0 303 10.1 Pinus sylvestris
3 0 105 5.48 Pinus sylvestris
4 0 138 7.07 Pinus nigra
5 0 153 7.54 Pinus sylvestris
6 0 233 9.60 Pinus sylvestris
7 0 140 7.01 Pinus sylvestris
8 0 200 7.36 Pinus sylvestris
9 0 210 10.1 Pinus sylvestris
10 0 142 6.25 Pinus sylvestris
# ℹ 408 more rowsDe este modo nos quedamos con 418 observaciones.
inventario_completo_tbl |>
ggplot(
aes(x = dbh_mm, y = height_m)
) +
geom_smooth()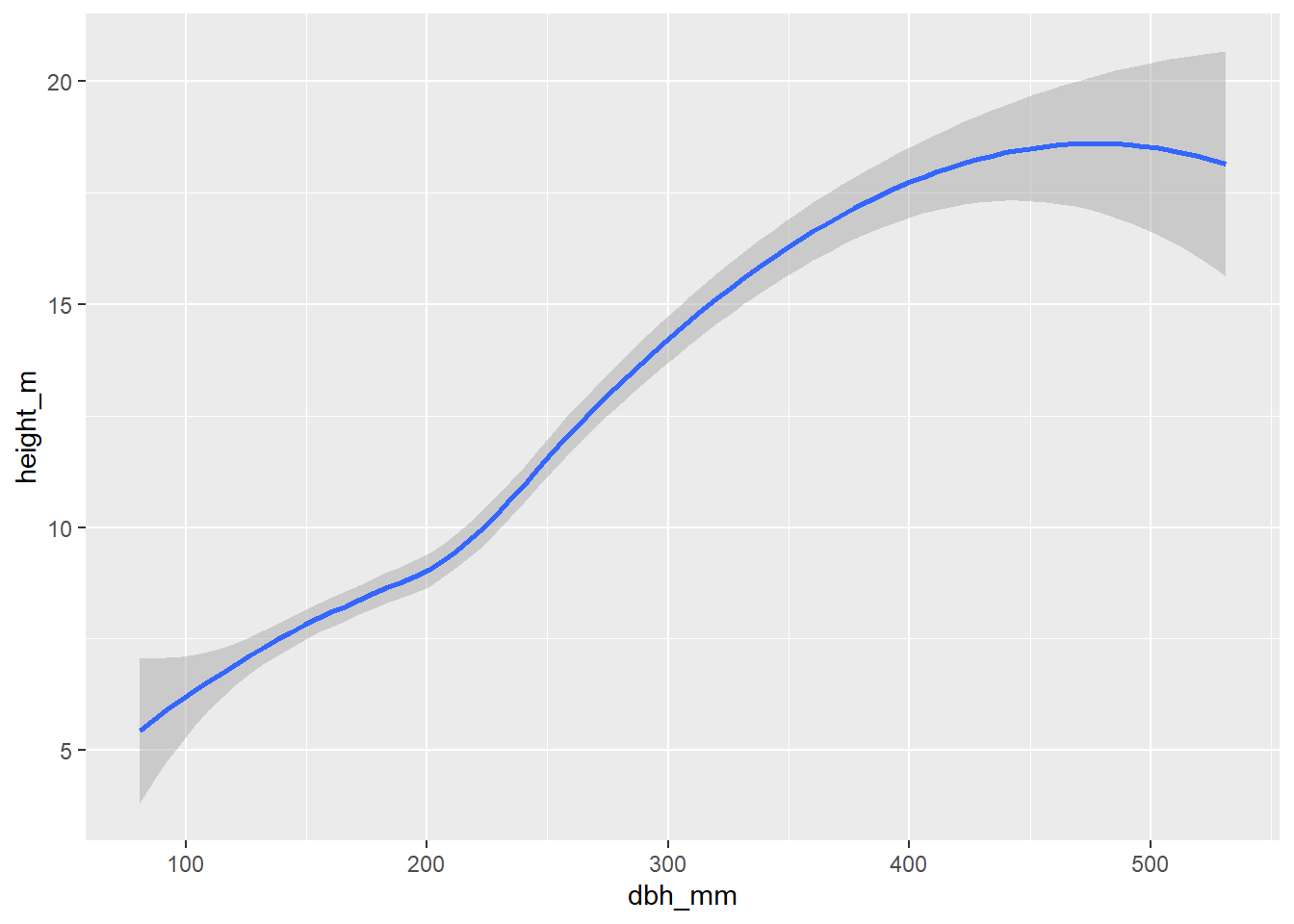
Compara las tres gráficas. En Figura 2.2 no utilizamos el argumento stat ya que el que viene por defecto es identity. Del mismo modo, en Figura 2.4 tampoco es necesario utilizar el argumento ya que stat = "smooth" viene por defecto.
En este curso no vamos a trabajar con transformaciones estadísticas en mayor profundidad. Esta sección solamente quiere remarcar que detrás de cada geometría existe una transformación estadística que viene dada por defecto.
También te habrás dado cuenta de que no hemos utilizado los componentes: facetas, escalas, coordenadas ni tema. Esto se debe a que estos componentes siempre, en todos los gráficos tienen un valor por defecto. Pero todo a su tiempo. Vamos a empezar desengranando el código anterior. Para tener una idea de los argumentos que estamos utilizando vamos a comparar los siguientes gráficos derivados de Figura 2.4:
ggplot(
data = inventario_completo_tbl,
mapping = aes(x = dbh_mm, y = height_m)
) +
geom_smooth()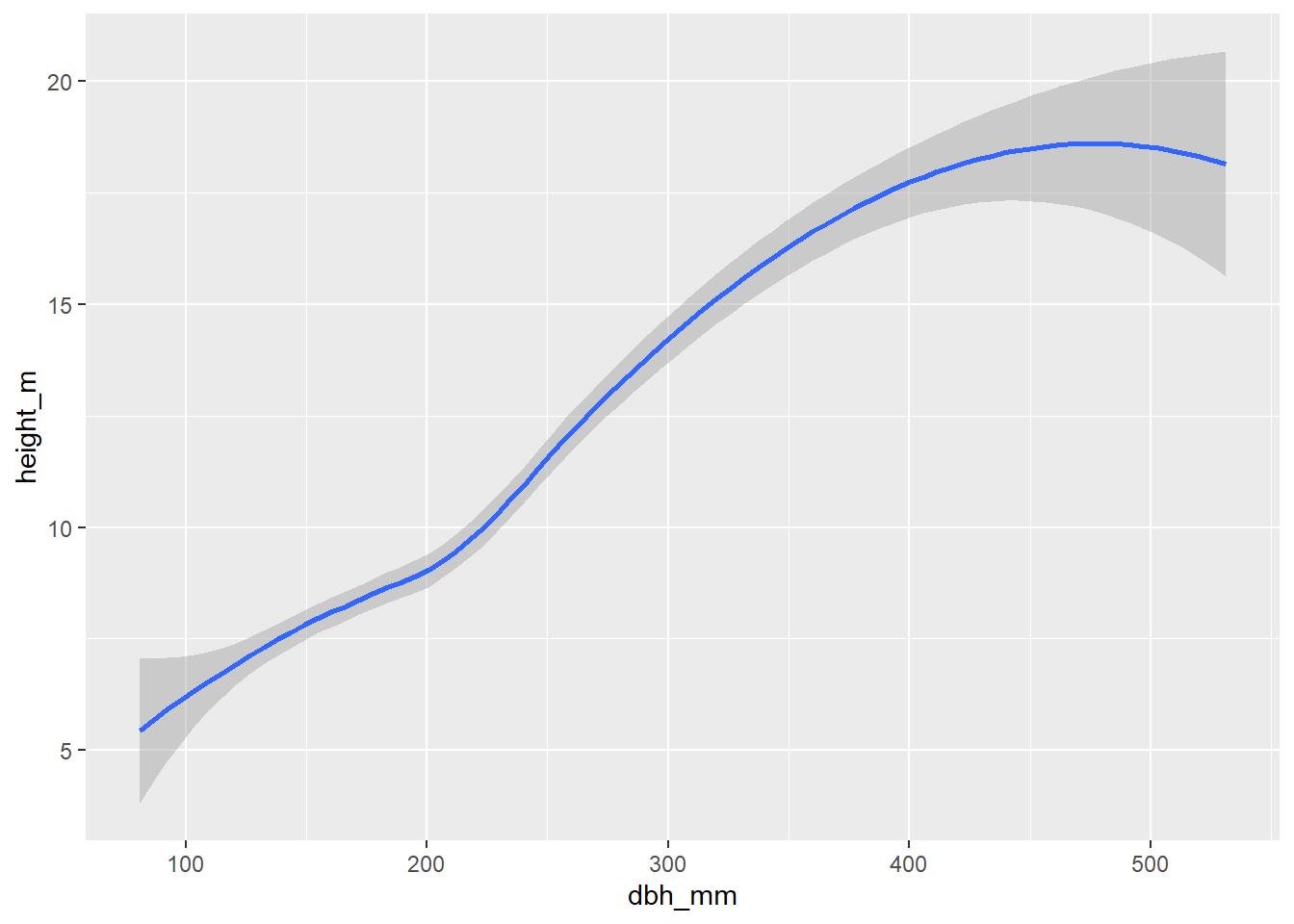
ggplot(inventario_completo_tbl, aes(x = dbh_mm, y = height_m)) +
geom_smooth()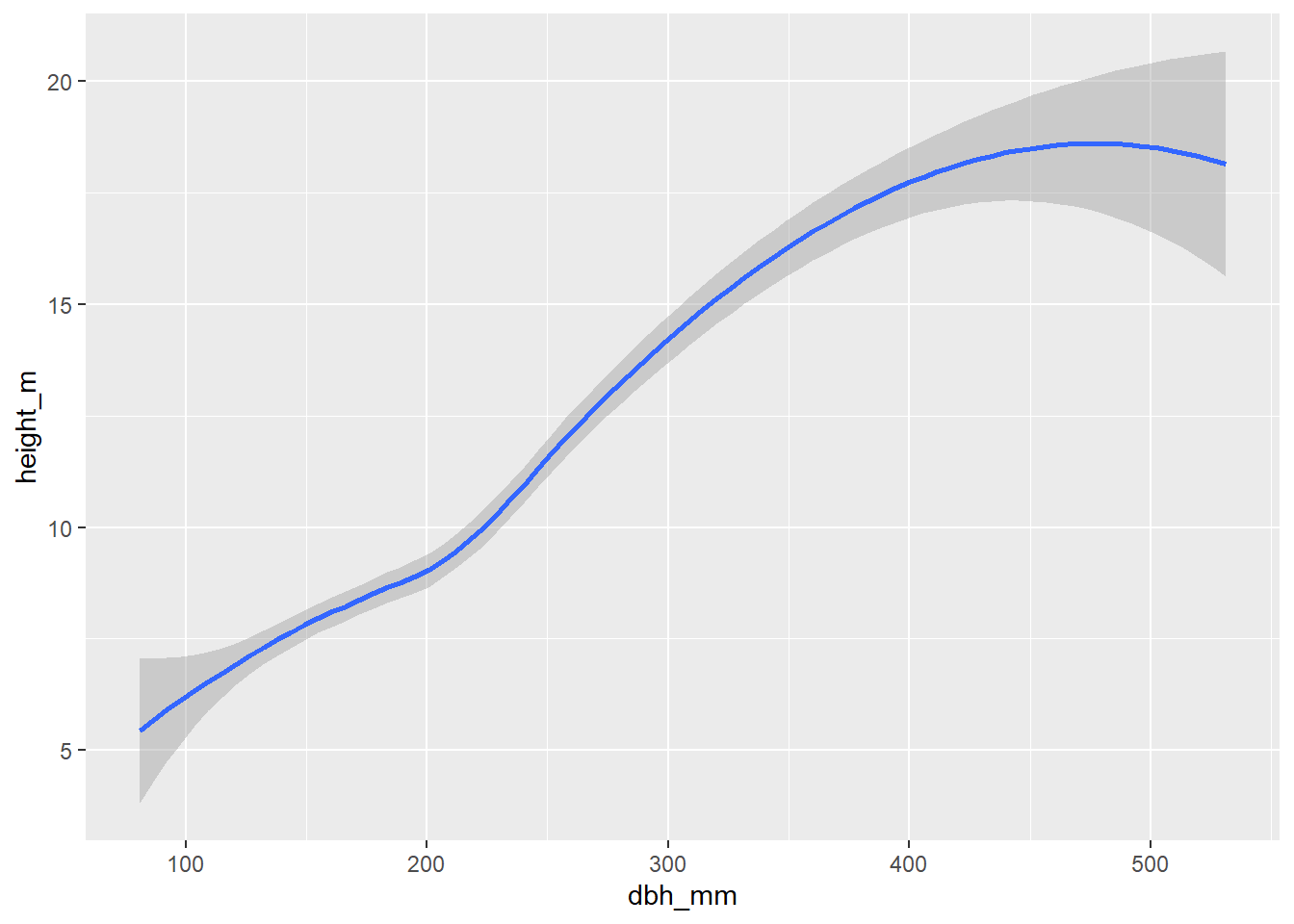
ggplot(
inventario_completo_tbl,
aes(x = dbh_mm, y = height_m)
) +
geom_smooth()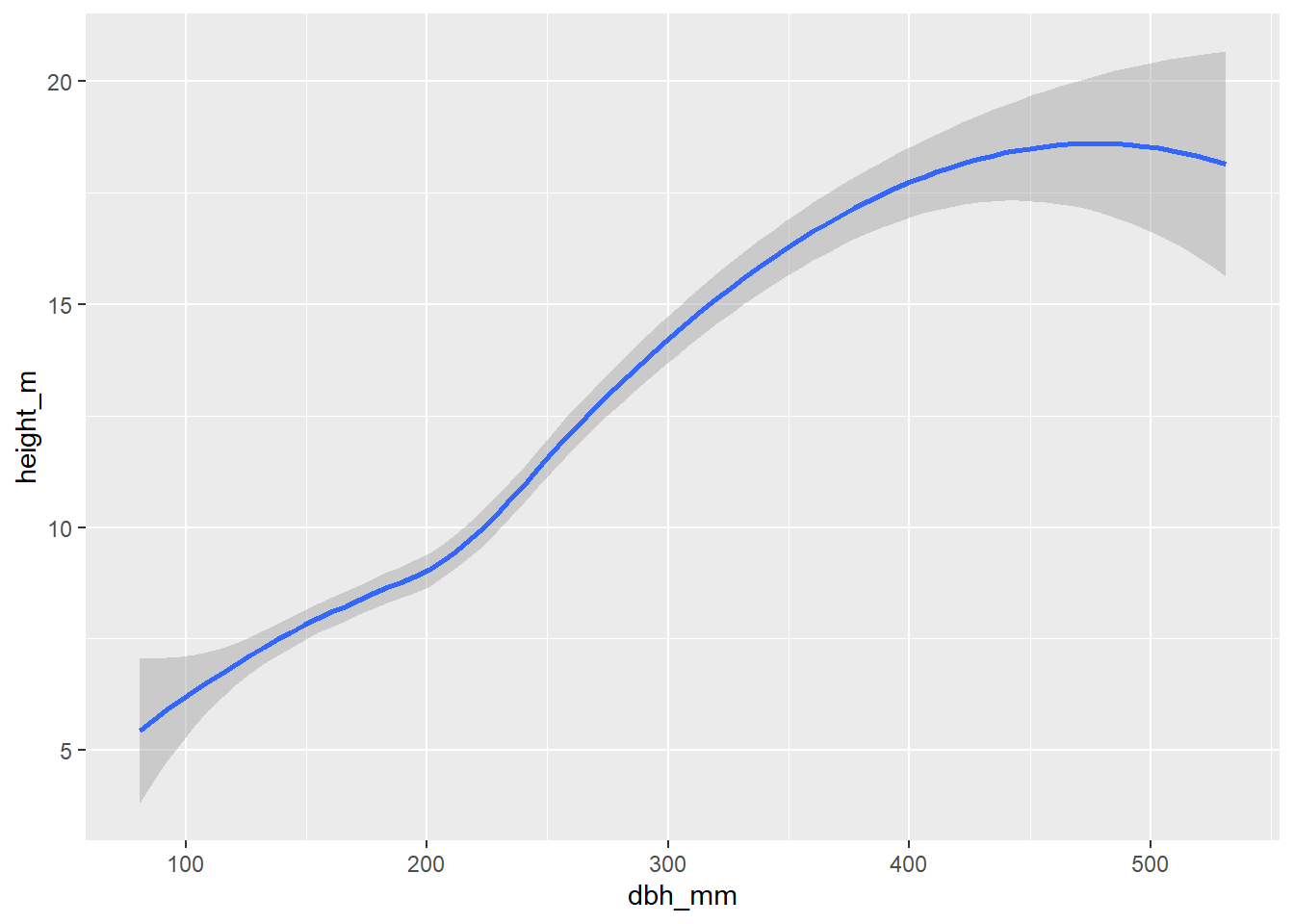
inventario_completo_tbl |>
ggplot(aes(x = dbh_mm, y = height_m)) +
geom_smooth()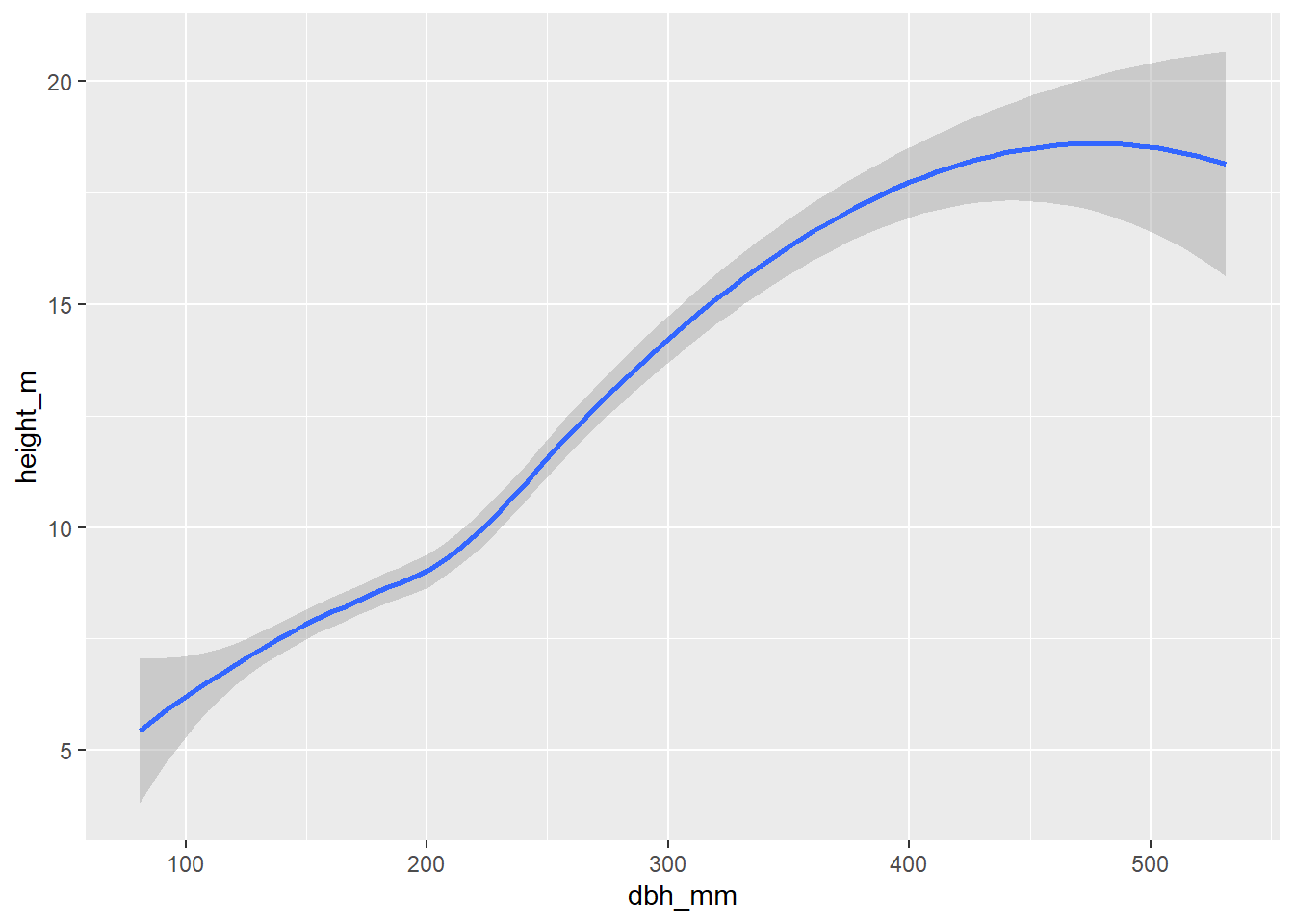
Como veis, el resultado es exactamente el mismo. Normalmente utilizaremos el pipe operator (|> o %>%) como hacemos en el método 4 para inyectar los datos en el primer argumento de la función ggplot() que es data. El argumento mapping también se sabe perfectamente que es el segundo argumento de la función, por lo que no es necesario escribir mapping = ... si no directamente aes(...). En resumen, cualquier método de escritura de código de los anteriores se adecua en mayor o menor medida a los principios de diseño ordenado (Wickham 2014). No obstante, el método 2 solamente será adecuado cuando no introduzcamos más argumentos dentro de la función, ya que haría que tuviésemos demasiado código en una sola línea. Mi método favorito es el método 4, aunque el 3 también es perfectamente válido. La indentación nos ayuda a ver a qué función pertenece cada argumento y hará que nuestro código sea mucho más fácil de leer y mantener. Finalmente, para añadir componentes a nuestro gráfico utilizamos el operador matemático +.
Desgraciadamente, mucha gente utiliza el método 2 para escribir código. En el ejemplo anterior estamos al límite de lo máximo recomendado por línea que son 80 caracteres (Wickham 2014). Pero si cogemos esa mala costumbre podemos escribir código como el siguiente. Lo entiendes?
filter(select(filter(inventario_completo_tbl, dbh_mm >= 300), dbh_mm:nombre_ifn), nombre_ifn == "Pinus sylvestris")# A tibble: 29 × 3
dbh_mm height_m nombre_ifn
<int> <dbl> <fct>
1 303 10.1 Pinus sylvestris
2 309 10.3 Pinus sylvestris
3 494 14.3 Pinus sylvestris
4 335 18.9 Pinus sylvestris
5 300 12.3 Pinus sylvestris
6 326 15.1 Pinus sylvestris
7 325 14.7 Pinus sylvestris
8 343 14.9 Pinus sylvestris
9 329 11.6 Pinus sylvestris
10 328 18.9 Pinus sylvestris
# ℹ 19 more rowsY si lo escribo de este modo?
filter(
select(
filter(
inventario_completo_tbl, dbh_mm >= 300
),
dbh_mm:nombre_ifn),
nombre_ifn == "Pinus sylvestris"
)# A tibble: 29 × 3
dbh_mm height_m nombre_ifn
<int> <dbl> <fct>
1 303 10.1 Pinus sylvestris
2 309 10.3 Pinus sylvestris
3 494 14.3 Pinus sylvestris
4 335 18.9 Pinus sylvestris
5 300 12.3 Pinus sylvestris
6 326 15.1 Pinus sylvestris
7 325 14.7 Pinus sylvestris
8 343 14.9 Pinus sylvestris
9 329 11.6 Pinus sylvestris
10 328 18.9 Pinus sylvestris
# ℹ 19 more rowsY de este?
inventario_completo_tbl |>
filter(dbh_mm >= 300) |>
select(dbh_mm:nombre_ifn) |>
filter(nombre_ifn == "Pinus sylvestris")# A tibble: 29 × 3
dbh_mm height_m nombre_ifn
<int> <dbl> <fct>
1 303 10.1 Pinus sylvestris
2 309 10.3 Pinus sylvestris
3 494 14.3 Pinus sylvestris
4 335 18.9 Pinus sylvestris
5 300 12.3 Pinus sylvestris
6 326 15.1 Pinus sylvestris
7 325 14.7 Pinus sylvestris
8 343 14.9 Pinus sylvestris
9 329 11.6 Pinus sylvestris
10 328 18.9 Pinus sylvestris
# ℹ 19 more rowsComo ves, tres formas de escribir el mismo código aumentando la legibilidad del mismo. Estos principios se utilizarán a lo largo de este curso. Una lectura muy recomendable es The tidyverse style guide.
2.6 Herencia de estéticas
Vamos a continuar con el ejemplo de la línea suavizada. Vamos a añadir otra capa donde se muestre la distribución de las observaciones con una geometría de punto:
inventario_completo_tbl |>
ggplot(
aes(x = dbh_mm, y = height_m)
) +
geom_point() +
geom_smooth()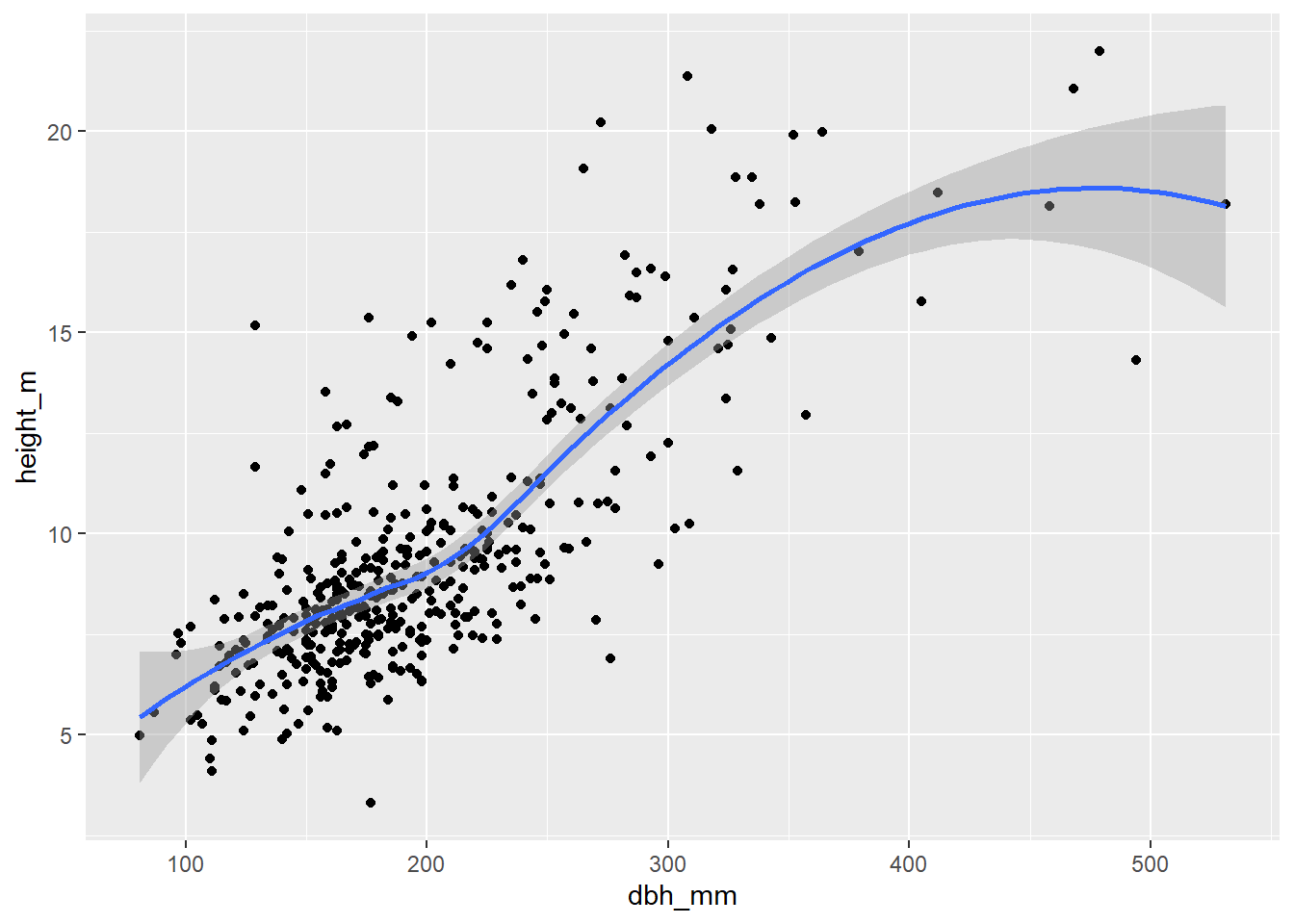
En este ejemplo estamos viendo una propiedad MUY IMPORTANTE en relación a la generación de gráficos con ggplot2. Dentro de la función ggplot() introducimos las estéticas y los datos. En siguiente lugar, las geometrías heredan estos elementos. Es decir, este gráfico podría ser algo más verboso del siguiente modo:
ggplot() +
geom_point(
data = inventario_completo_tbl,
aes(x = dbh_mm, y = height_m)
) +
geom_smooth(
data = inventario_completo_tbl,
aes(x = dbh_mm, y = height_m)
) 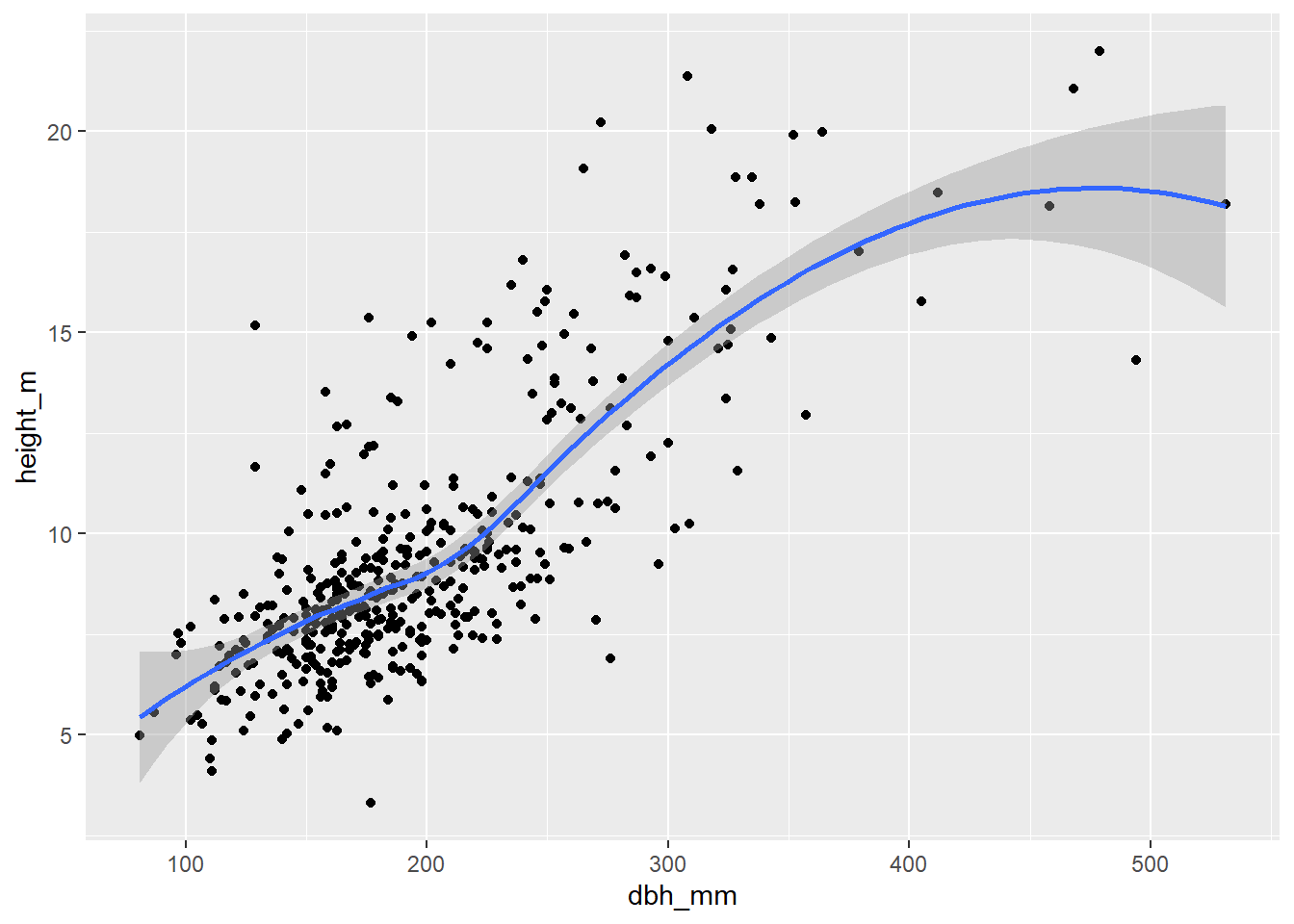
En este caso, estamos especificando los datos y las estéticas en cada una de las geometrías. Aunque esto es posible, no es recomendable ya que aumenta la longitud del código y puede llevar a errores si no se especifican correctamente los datos y las estéticas en cada una de las geometrías. No obstante, en muchos casos es necesario especificar los datos y las estéticas en cada una de las geometrías, ya que pueden utilizar estéticas diferentes o incluso datos diferentes. Vamos a ver un caso sencillo donde queremos representar la relación entre el diámetro y la altura de los árboles, pero queremos que los puntos de una especie sean de un color diferente a los de la otra especie. Vamos a ver una serie de ejemplos:
En este caso introducimos la estética color dentro de la función de ggplot(). En este caso todas las geometrías heredan las estéticas:
inventario_completo_tbl |>
ggplot(
aes(x = dbh_mm, y = height_m, color = nombre_ifn)
) +
geom_point() +
geom_smooth() 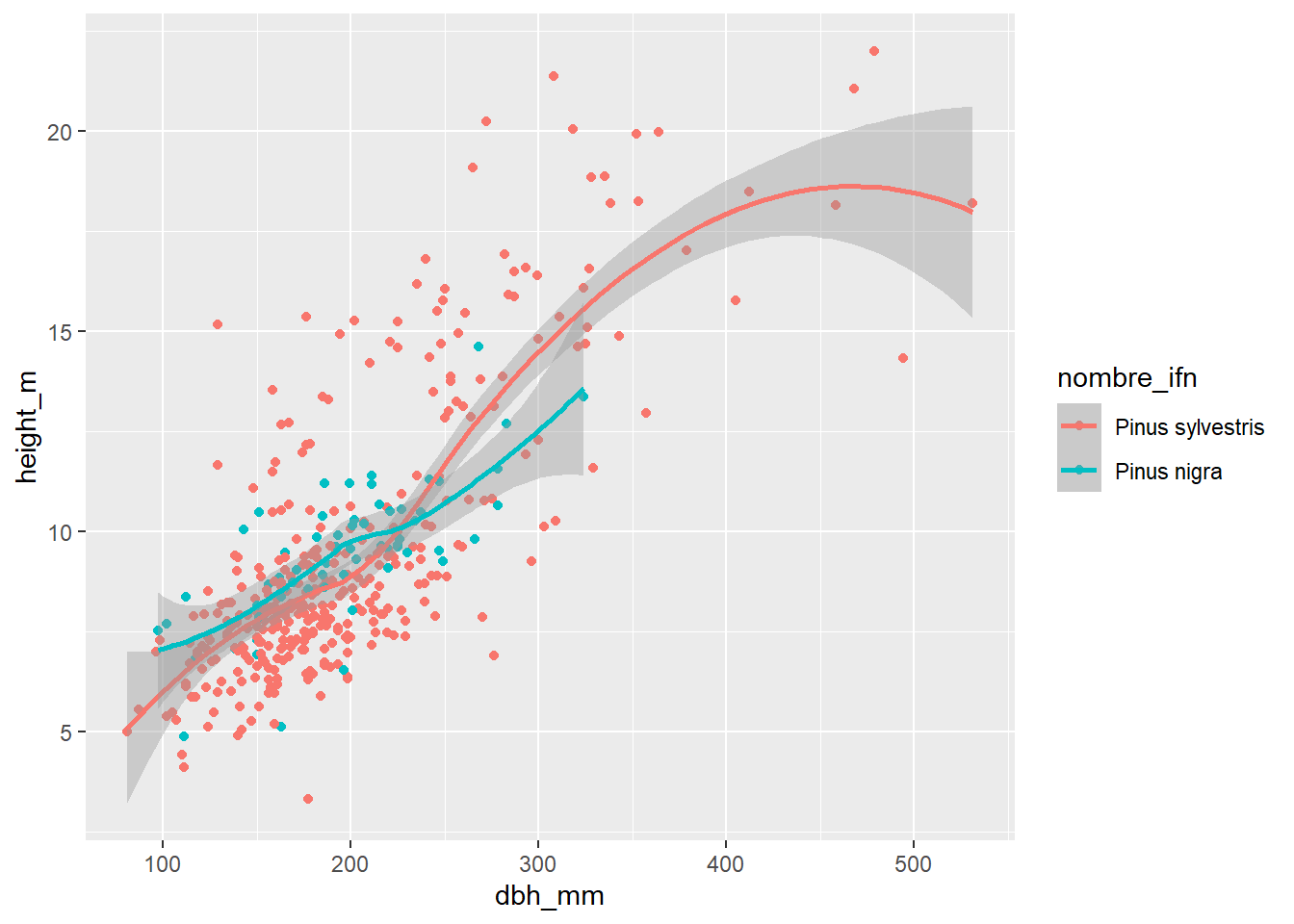
En este otro caso, introducimos la estética color solamente dentro de la función geom_point(), por lo que solamente los puntos utilizan esta estética:
inventario_completo_tbl |>
ggplot(
aes(x = dbh_mm, y = height_m)
) +
geom_point(aes(color = nombre_ifn)) +
geom_smooth()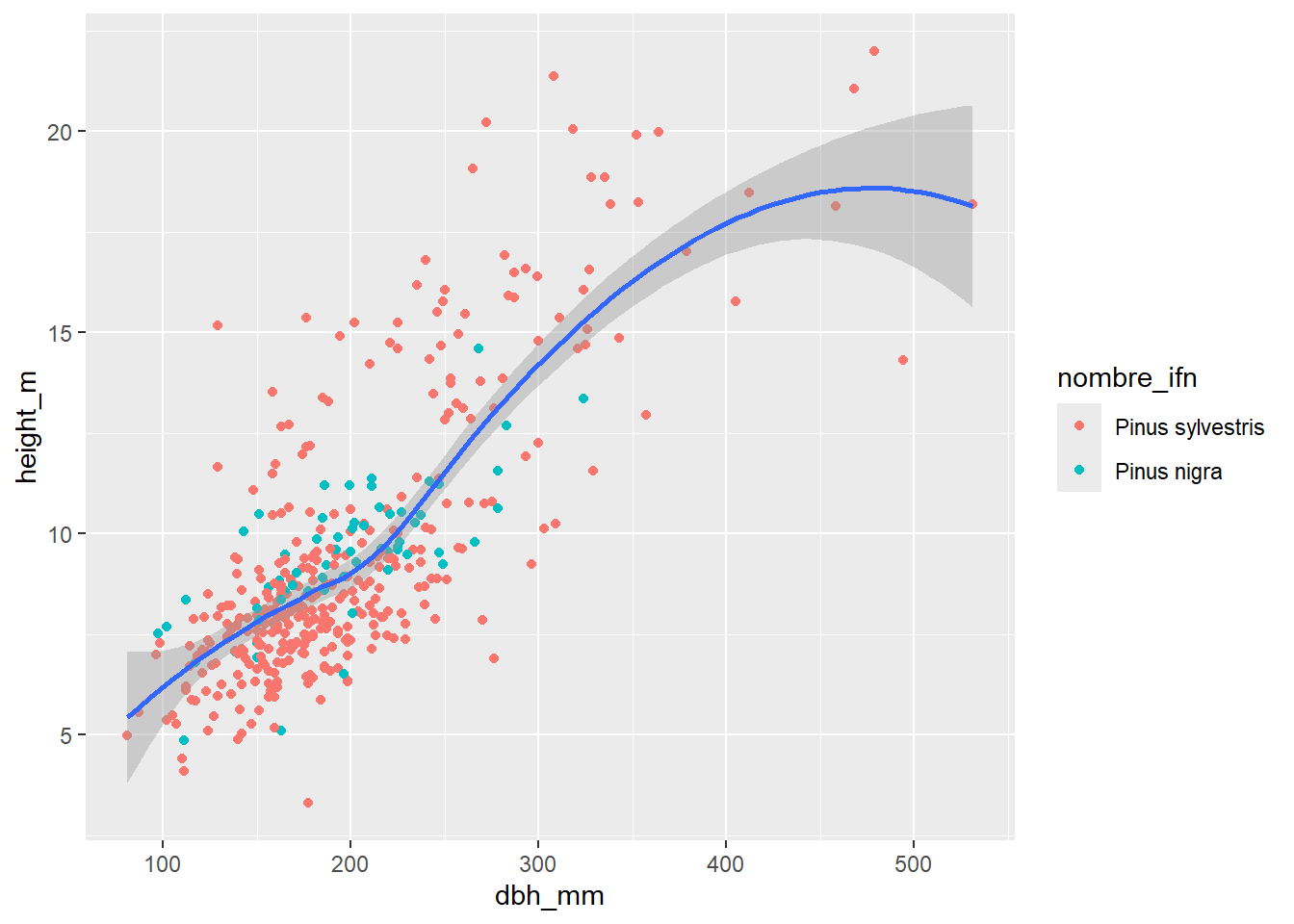
En este último caso, añadimos la estética color a función geom_smooth(), por lo que solamente se colorean las líneas de tendencia:
inventario_completo_tbl |>
ggplot(
aes(x = dbh_mm, y = height_m)
) +
geom_point() +
geom_smooth(aes(color = nombre_ifn))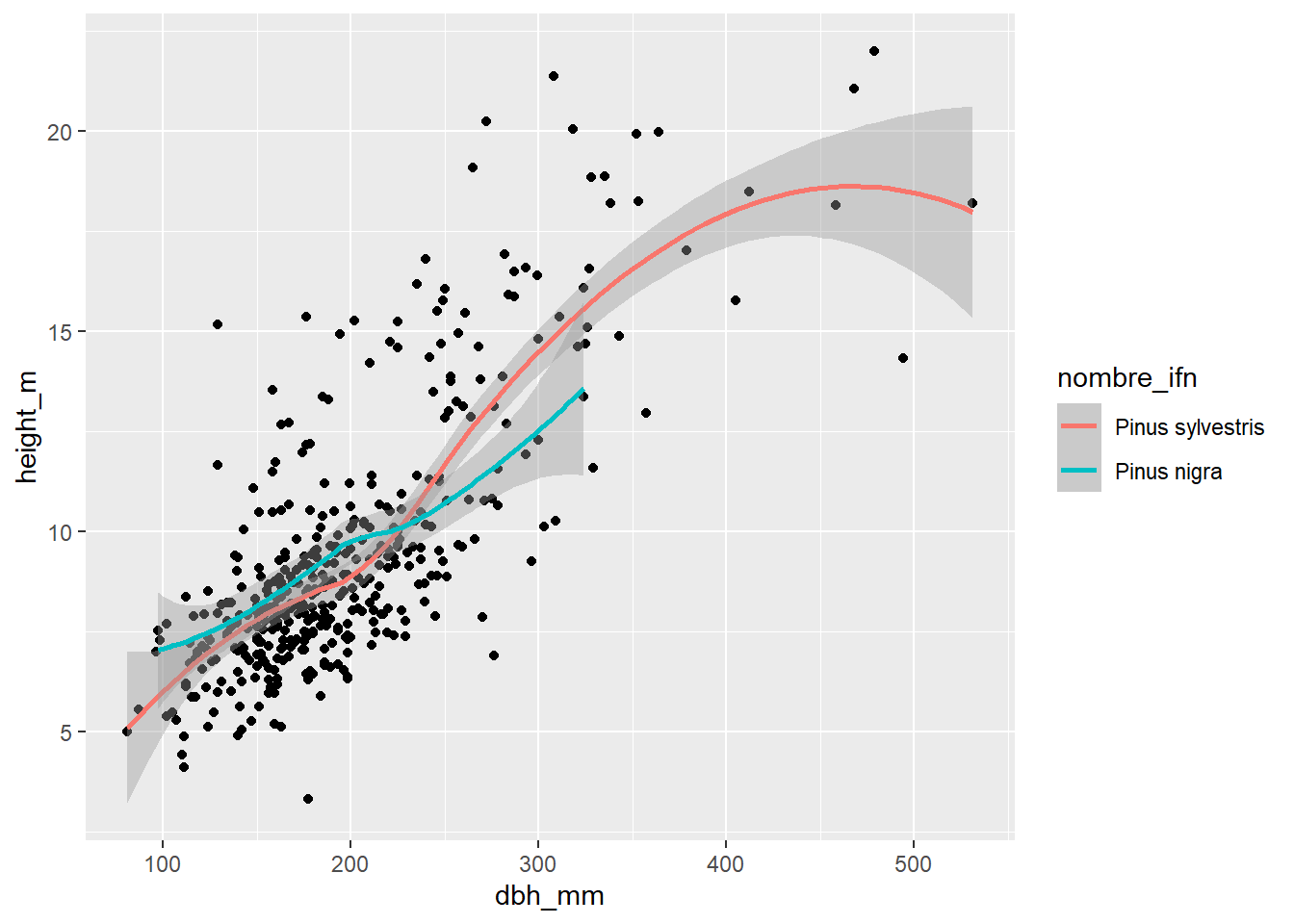
También puedes ver que en los ejemplos anteriores, la geometría de punto la escribimos antes que la línea de tendencia. De este modo se dibujan en el gráfico, primero los puntos, y en siguiente lugar se dibuja la línea de tendencia sobre los puntos.
2.7 Mapear y asignar estéticas
Para finalizar este capítulo, vamos a ver dos conceptos que al principio pueden parecer un poco confusos, pero que veréis que tienen todo el sentido del mundo dentro de la gramática de gráficos. Vamos a comenzar viendo estas dos frases que inicialmente no tendrán mucho sentido, pero que entenderemos al final de esta sección:
Mapeamos estéticas a variables
Asignamos estéticas a valores constantes
Vamos a seguir trabajando con la geometría de puntos, ya que es una de las más sencillas para aprender la teoría. Si buscáis en la documentación oficial de las funciones geom_*, encontraréis una sección de estéticas como la que se muestra en la Figura 2.8:
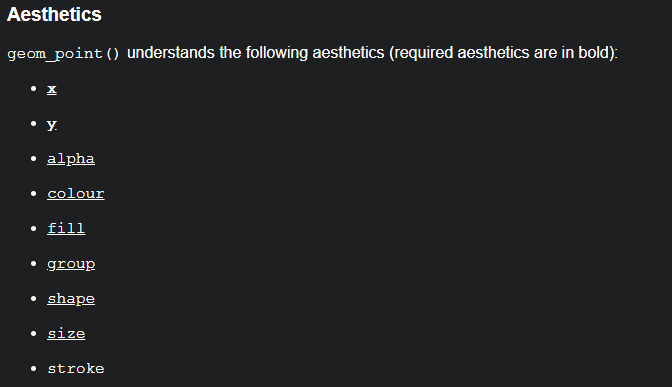
Todas las geometrías tienen una serie de estéticas obligatorias y otras opcionales. Para la geometría de punto las obligatorias son x e y
TODAS estas estéticas se pueden mapear a variables, es decir, todas pueden ir dentro de la función aes(x, y, alpha, color, fill ...). Siempre que vayan dentro de la función aes(), estaremos mapeando la estética a una variable, y por lo tanto, el valor de la estética debe ser una variable de nuestros datos como en el siguiente exagerado ejemplo:
inventario_completo_tbl |>
ggplot(
aes(
x = dbh_mm,
y = height_m,
color = nombre_ifn,
shape = nombre_ifn,
size = height_m
)
) +
geom_point()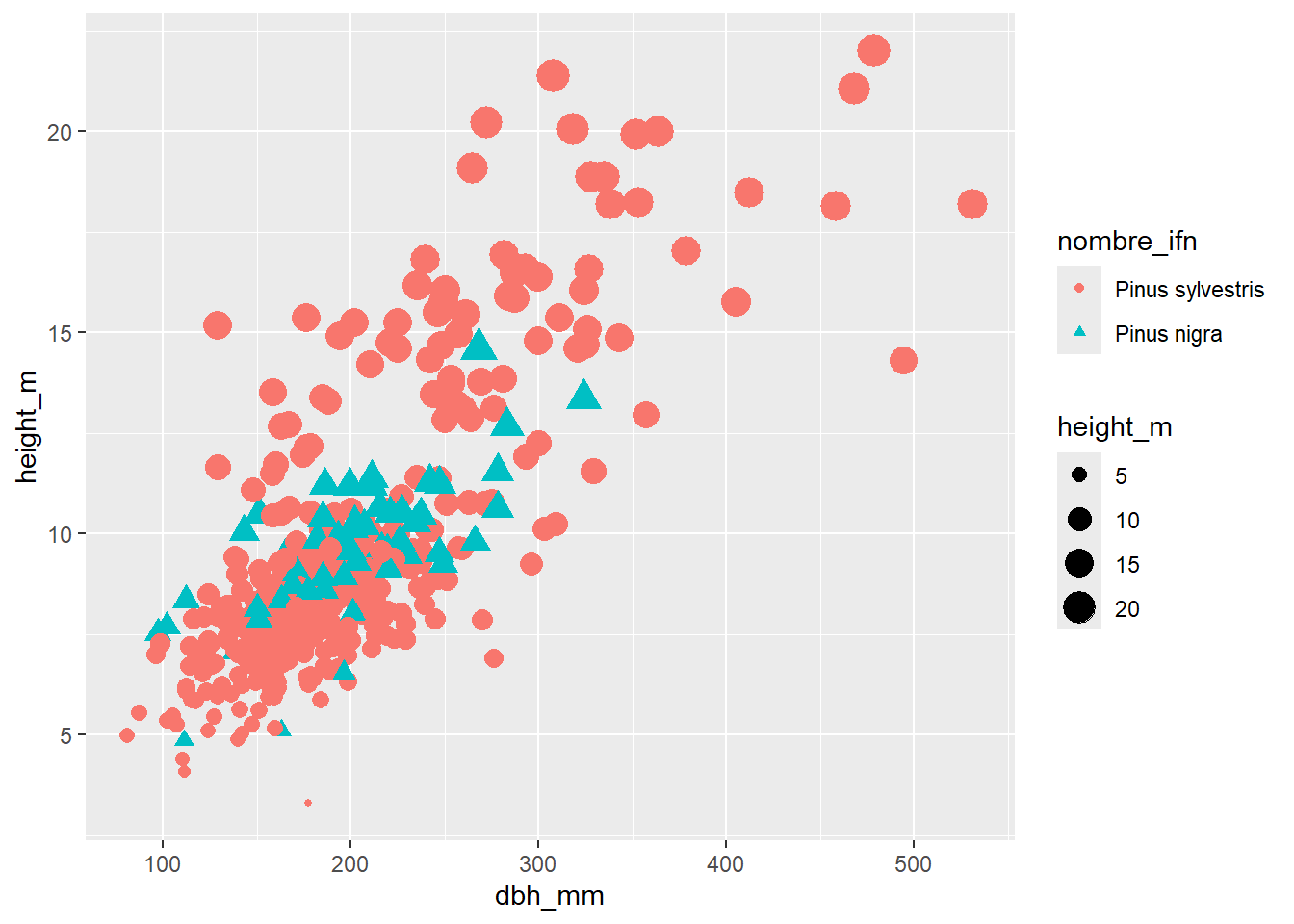
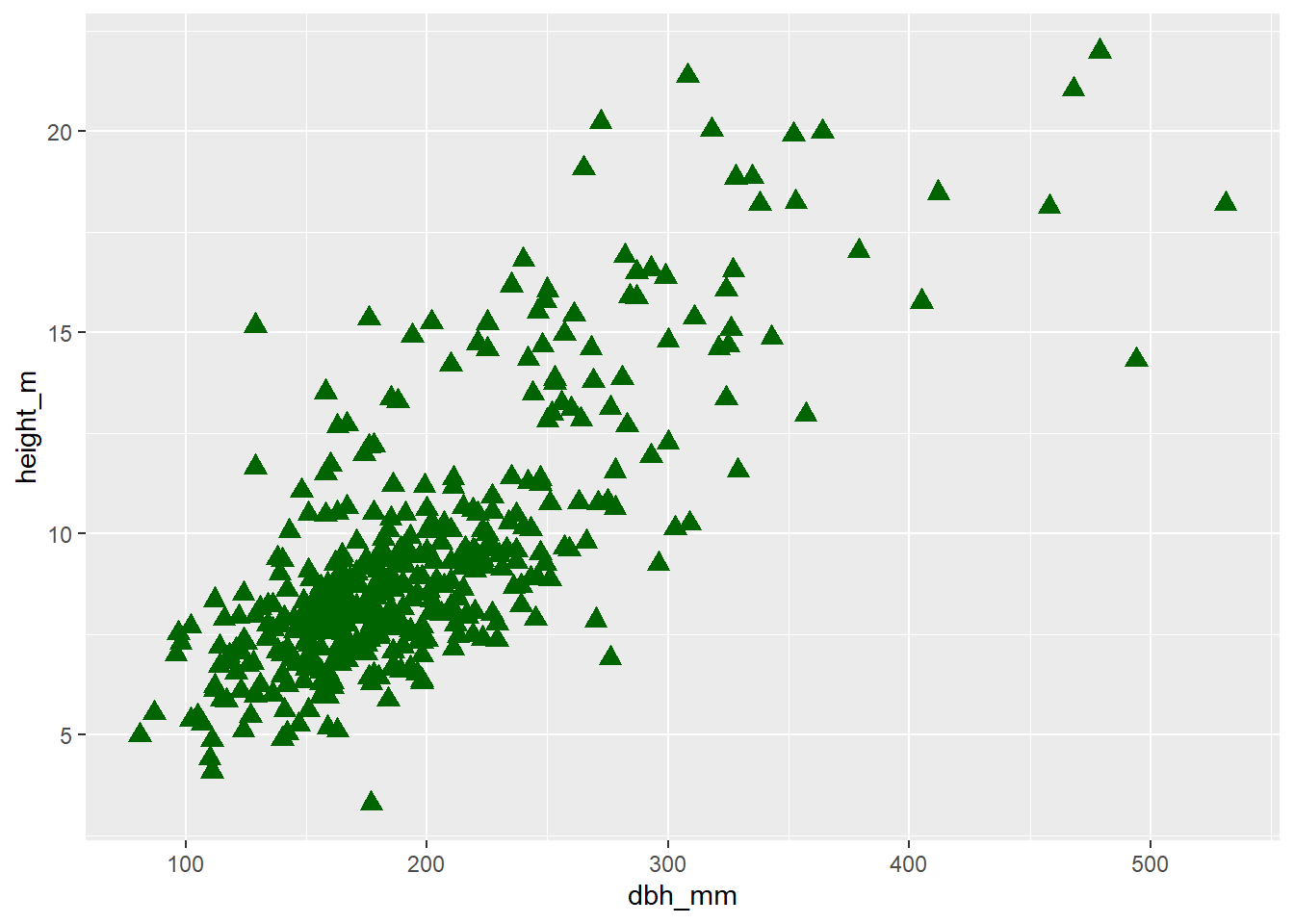
Sin embargo, algunas de las estéticas también se pueden asignar a valores constantes. Es decir, en lugar de generar un color de punto por cada especie, podemos elegir que todos los puntos sean de color verde oscuro. O que la forma de todos los puntos sea triangular. En este caso hablamos de asignar constantes, y las estéticas se escriben dentro de la función de geom_* y fuera de aes():
inventario_completo_tbl |>
ggplot(
aes(x = dbh_mm, y = height_m)
) +
geom_point(
color = "darkgreen",
shape = "triangle",
size = 3
)
En este sentido, algo que NO podemos hacer y que suele ser un fallo común al empezar con ggplot2 es lo siguiente:
inventario_completo_tbl |>
ggplot(
aes(x = dbh_mm, y = height_m)
) +
geom_point(
color = nombre_ifn
)Nos dará el error “Error : objeto ‘nombre_ifn’ no encontrado”. Como color está fuera de aes(), la función está buscando si en el entorno existe el objeto nombre_ifn. Para entender este concepto, vamos a ver el siguiente código:
## Asignar un color a un objeto
nombre_ifn <- "#456435"
## Gráfico
inventario_completo_tbl |>
ggplot(
aes(x = dbh_mm, y = height_m)
) +
geom_point(
color = nombre_ifn
)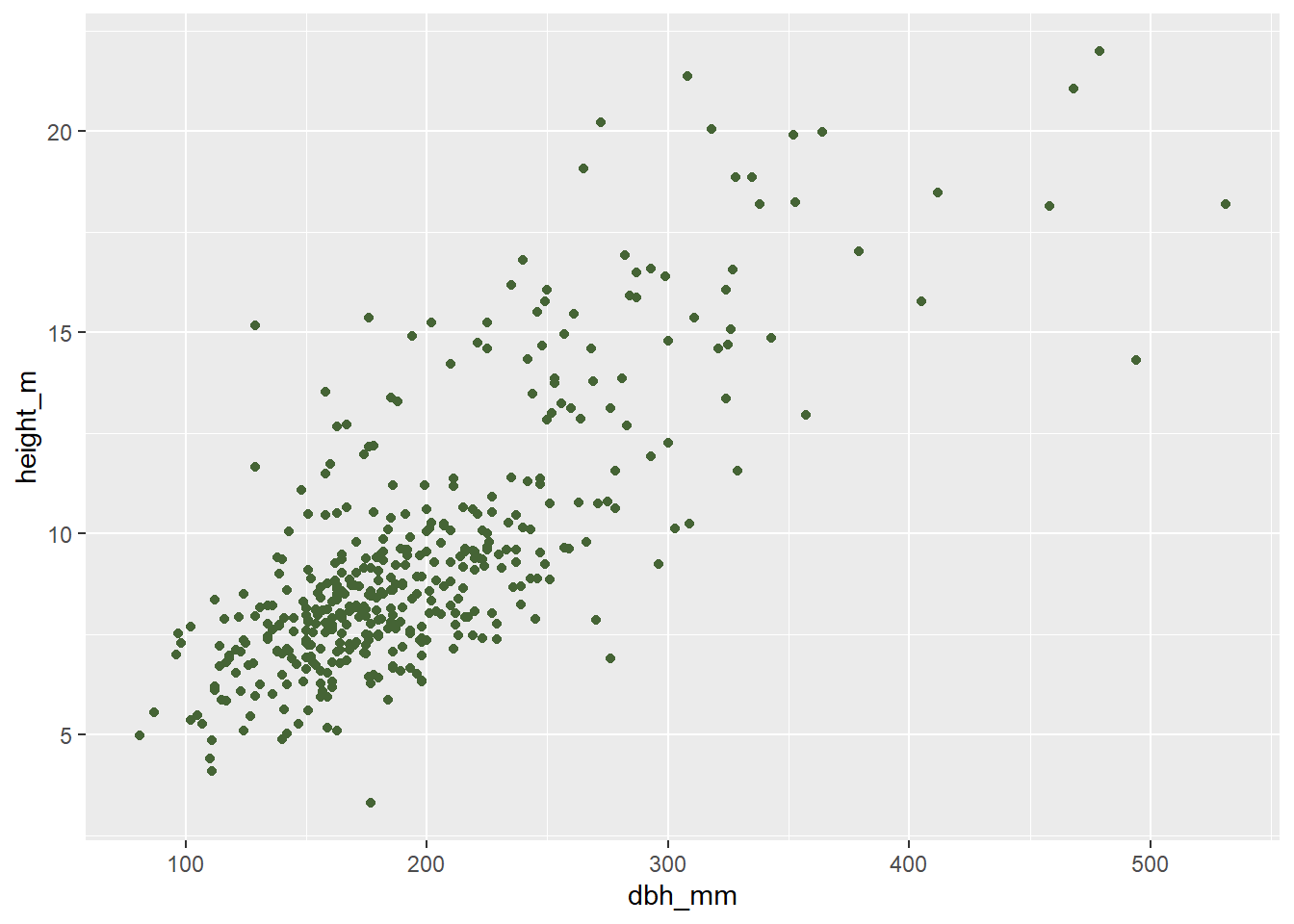
Cuando una estética se encuentra fuera de aes(), no busca nombre_ifn dentro de las columnas de los datos, si no que lo busca en el Global Environment. Finalmente, tampoco podemos introducir constantes dentro de aes():
inventario_completo_tbl |>
ggplot(
aes(x = dbh_mm, y = height_m, color = "blue")
) +
geom_point()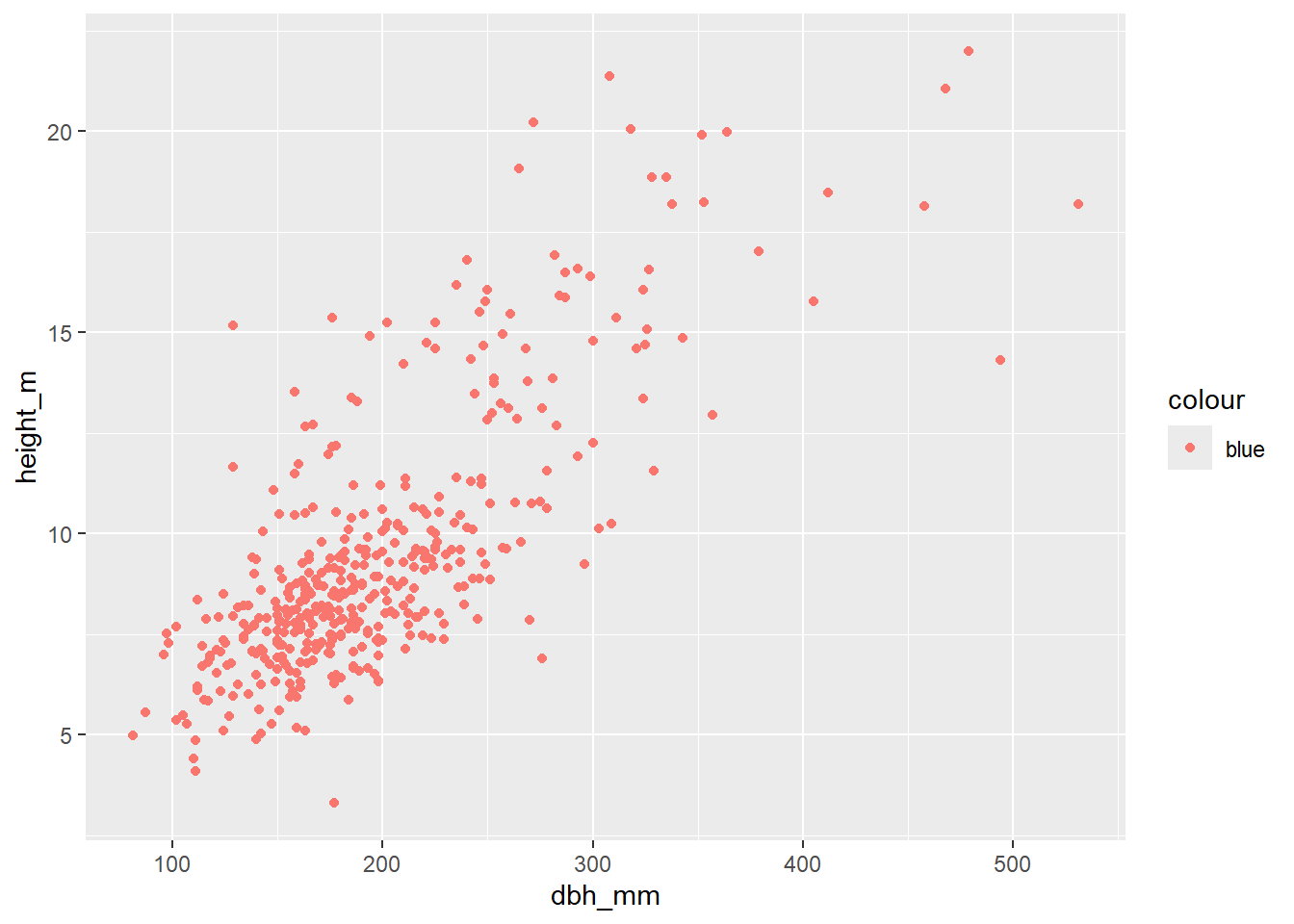
Esto no funciona porque lo que hace es crear una variable constante cuyos valores son “blue”. Es decir, esto es equivalente a:
inventario_completo_tbl |>
mutate(
colour = "blue"
) |>
ggplot(
aes(x = dbh_mm, y = height_m, color = colour)
) +
geom_point()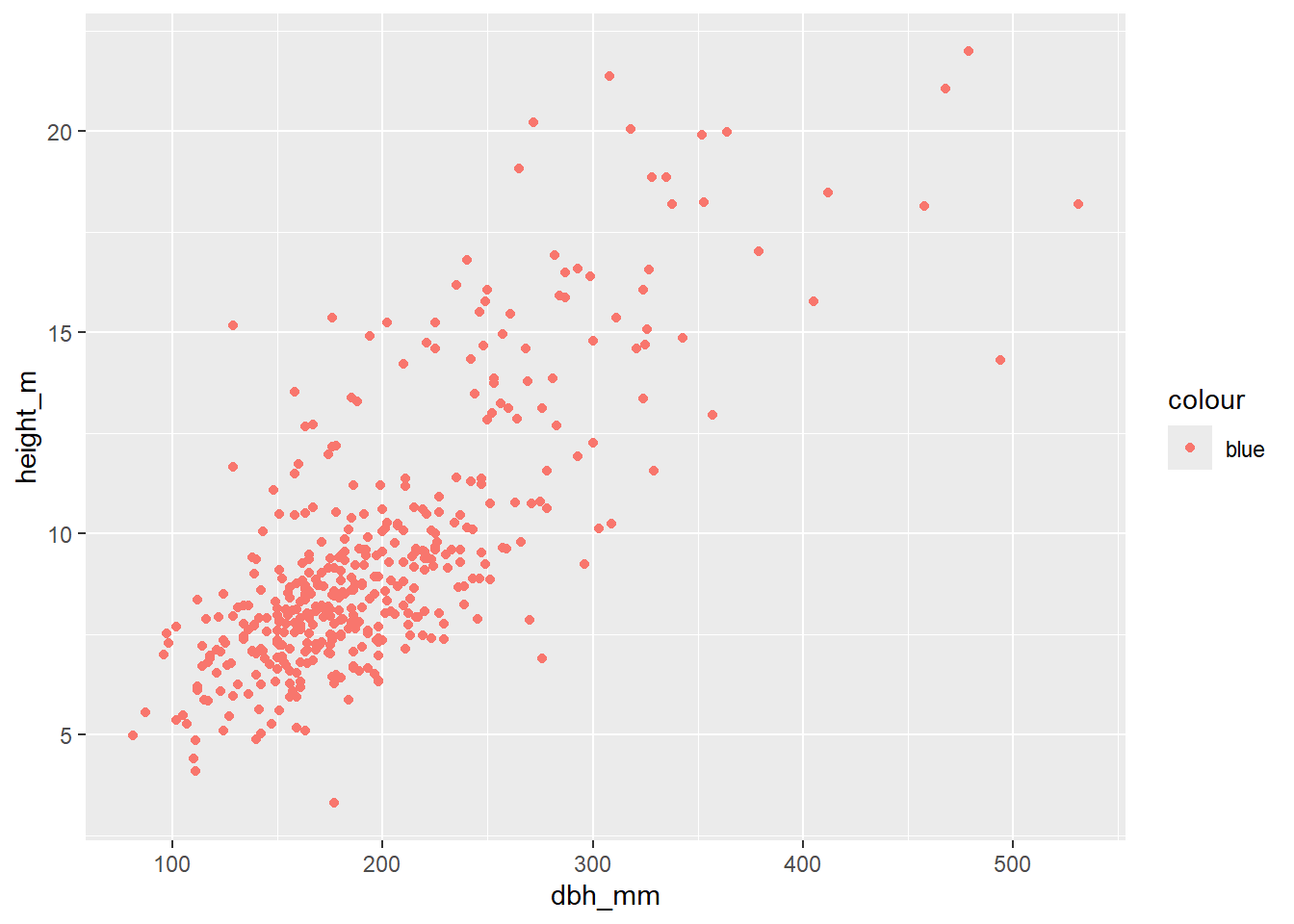
Es decir, no tiene nada de sentido. Para finalizar, vamos a resumir esta sección de nuevo en las frases que veíamos al inicio:
Mapeamos estéticas a variables
Asignamos estéticas a valores constantes
2.8 Resumen
En esta sección hemos aprendido los conceptos básicos de la gramática de gráficos y cómo se aplican en ggplot2. Hemos visto los componentes básicos de un gráfico y cómo se pueden combinar para crear gráficos complejos. También hemos aprendido cómo se pueden mapear estéticas a variables y asignar estéticas a valores constantes. Lo más importante de esta lección ha sido:
Componentes de la gramática de gráficos
Estructura de un gráfico sencillo con una o varias capas:
Herencia de datos y estéticas: todas las geometrías heredan las estéticas y los datos de la función
ggplot(). Las estéticas que se introducen en la geometría se aplican solamente a esa geometría.Mapear y asignar estéticas: las estéticas se pueden mapear a variables o asignar a valores constantes. Las estéticas mapeadas (variables) se introducen dentro de la función
aes(), mientras que las estéticas asignadas (constantes) se introducen fuera deaes()y siempre dentro de la función degeom_*y no deggplot().
En la siguiente sección, veremos los valores por defecto el resto de componentes de la gramática de gráficos.